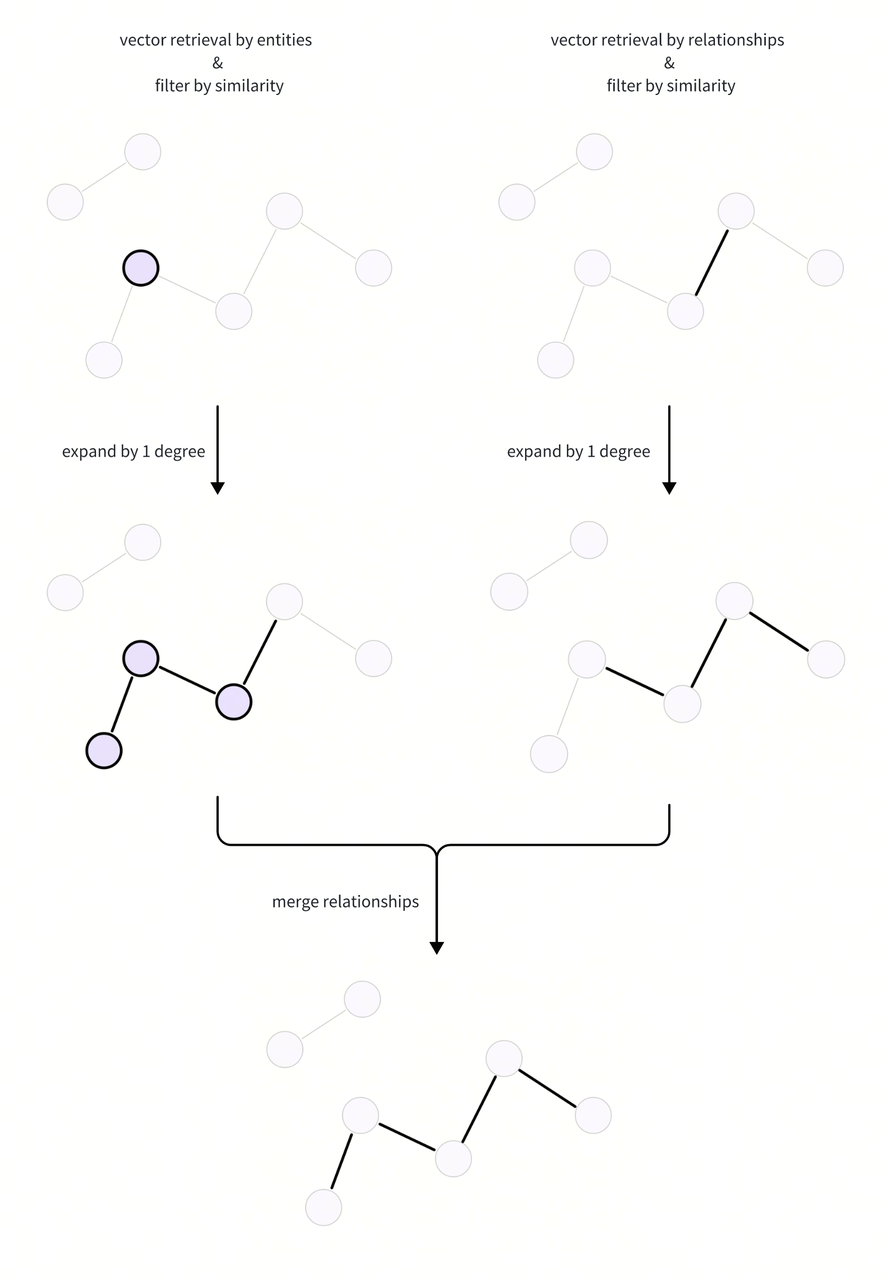
构建环境
# 创建虚拟环境
conda create --name xtuner-env python=3.10 -y
conda activate xtuner-env
# 安装xtuner
git clone https://github.com/InternLM/xtuner.git
cd xtuner
pip install -e '.[all]' # “-e” 表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效
# 验证xtuner安装是否成功
xtuner list-cfg下载模型
pip install modelscope
modelscope download --model Shanghai_AI_Laboratory/internlm2-chat-1_8b --local_dir ./model/internlm2-chat-1_8b微调
创建微调训练相关的配置文件在左侧的文件列表,xtuner 的文件夹里,打开 xtuner/xtuner/configs/internlm/internlm2_chat_1_8b/internlm2_chat_1_8b_qlora_alpaca_e3.py, 复制一份至根目录。 打开这个文件,然后修改预训练模型地址,数据文件地址。
#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = "/workspace/model/internlm2-chat-1_8b"
# Data
data_files = "/workspace/data/data/target_data.json"
# Scheduler & Optimizer
batch_size = 2 # per_device
max_epochs = 3
evaluation_inputs = [
'只剩一个心脏了还能活吗?', '爸爸再婚,我是不是就有了个新娘?',
'樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买','马上要上游泳课了,昨天洗的泳裤还没干,怎么办',
'我只出生了一次,为什么每年都要庆生'
]
#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(
dataset=dict(type=load_dataset, path="json", data_files=data_files),
dataset_map_fn=None,
)
微调训练
xtuner train internlm2_chat_1_8b_qlora_alpaca_e3.pyerror: libGL.sl.1:cannot open shared object file: No such file or directory
sudo apt-get update sudo apt-get install libgl1
02/26 11:51:16 - mmengine - INFO - Iter(train) [20/54] lr: 1.4828e-09 eta: 0:03:21 time: 6.1277 data_time: 0.2100 memory: 9363 loss: 2.1967 grad_norm: 0.4390
02/26 11:52:16 - mmengine - INFO - Iter(train) [30/54] lr: 9.1120e-10 eta: 0:02:23 time: 6.0434 data_time: 0.0097 memory: 9363 loss: 2.2208 grad_norm: 0.4390
02/26 11:53:20 - mmengine - INFO - Iter(train) [40/54] lr: 3.6991e-10 eta: 0:01:25 time: 6.3791 data_time: 0.2100 memory: 9363 loss: 2.2509 grad_norm: 0.4366
02/26 11:54:22 - mmengine - INFO - Iter(train) [50/54] lr: 4.3599e-11 eta: 0:00:24 time: 6.2547 data_time: 0.0097 memory: 9363 loss: 2.2101 grad_norm: 0.4387
模型转换
模型训练后会自动保存成 PTH 模型(例如 iter_2000.pth ,如果使用了 DeepSpeed,则将会是一个文件夹),利用 xtuner convert pth_to_hf 将其转换为 HuggingFace 模型,以便于后续使用。具体命令为:
xtuner convert pth_to_hf ${FINETUNE_CFG} ${PTH_PATH} ${SAVE_PATH}
# 例如:xtuner convert pth_to_hf internlm2_chat_7b_qlora_custom_sft_e1_copy.py
./iter_2000.pth ./iter_2000_模型合并
如果使用了 LoRA / QLoRA 微调,则模型转换后将得到 adapter 参数,而并不包含原 LLM 参数。如果期望获得合并后的模型权重(例如用于后续评测),那么可以利用 xtuner convert merge :
xtuner convert merge ${LLM} ${LLM_ADAPTER} ${SAVE_PATH}