
Step1-定义数据集
用于创建 ChatGPT 的数据集为 570 GB。假设数据集为一下内容:
白日依山尽,黄河入海流。
马无夜草不肥,人无横财不富。
天行健,君子以自强不息,地势坤,君子以厚德载物。
Step2-计算词汇量
Dataset 中单独单词的总数为词汇量。它可以通过一下公式计算,其中单独单词的总数为N:
vocab size = count(set(N))
为了找到N(总词数),将以上数据集分解为单个字。
N = \begin{bmatrix}
白&日&依&山&尽&黄&河&入&海&流 \\
马&无&夜&草&不&肥&人&我&横&财&不&富&\\
天&行&健&君&子&以&自&强&不&息&地&势&坤&君&子&以&厚&德&载&物
\end{bmatrix}
在获取到N之后,执行集合操作以删除重复项,其中独特字的数量就是词汇量大小。
\begin{array}{l}
vocab size = count(set(N)) \\ \\
N = \begin{bmatrix}
白&日&依&山&尽&黄&河&入&海&流 \\
马&无&夜&草&不&肥&人&无&横&财&不&富&\\
天&行&健&君&子&以&自&强&不&息&地&势&坤&君&子&以&厚&德&载&物
\end{bmatrix} \\ \\
set(N) = \begin{pmatrix}
白&日&依&山&尽&黄&河&入&海&流 \\
马&无&夜&草&不&肥&人&横&财&富 \\
天&行&健&君&子&以&自&强&息&地&势&坤&厚&德&载&物
\end{pmatrix} \\ \\
count(set(N)) = 36
\end{array}
因此,词汇量大小为26,因为数据集中有26个单独的字。
Step3-Encoding编码
众所周知,神经网络做的是数学计算,它接收的是数字而非其他任何内容,所以这里我们需要为每一个字符分配一个唯一的数字。将单个Token视为一个字并为其分配一个数字:
\begin{matrix}
1&2&3&4&5&6&7&8&9&10&11&12&13&14&15&16&17&18 \\
白&日&依&山&尽&黄&河&入&海&流&马&无&夜&草&不&肥&人&横 \\
19&20&21&22&23&24&25&26&27&28&29&30&31&32&33&34&35&36 \\
财&富&天&行&健&君&子&以&自&强&息&地&势&坤&厚&德&载&物
\end{matrix}
Step4-计算Word Embedding
Encoding 完整个数据集后,现在选择我们的输入并开始使用 Transformer 架构工作。从语料库中选择一个句子马无夜草不肥在Transformer架构中处理:
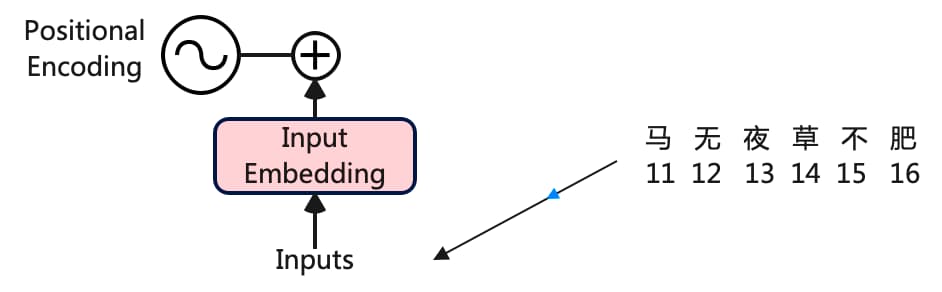
《Attention Is All You Need》论文中为每个输入词使用了512维的嵌入向量:
\begin{array}{l}
vocab\begin{matrix}
11&12&13&14&15&16 \\
马&无&夜&草&不&肥 \\
\end{matrix} \\ \\
512 \left\{\begin{matrix}
\Box & \Box & \Box & \Box & \Box & \Box\\
\Box & \Box & \Box & \Box & \Box & \Box\\
\Box & \Box & \Box & \Box & \Box & \Box\\
\Box & \Box & \Box & \Box & \Box & \Box\\
··& ·· & ·· & ·· & ·· & ··\\
\Box & \Box & \Box & \Box & \Box & \Box
\end{matrix}\right.
\end{array}
使用较小的嵌入向量维度来可视化计算的进行过程。因此,我们将使用嵌入向量的维度6。
\begin{array}{l}
\left.\begin{matrix}
Input\\
Embedding
\end{matrix}\right\}\Leftarrow
\begin{array}{l}
\begin{vmatrix}
0.68 & 0.13 & 0.27 & 0.38 & 0.75 & 0.94 \\
0.23 & 0.43 & 0.53 & 0.12 & 0.54 & 0.76 \\
0.10 & 0.16 & 0.39 & 0.15 & 0.34 & 0.34 \\
0.56 & 0.34 & 0.18 & 0.45 & 0.54 & 0.73 \\
0.09 & 0.29 & 0.75 & 0.54 & 0.21 & 0.67 \\
0.65 & 0.04 & 0.43 & 0.32 & 0.22 & 0.33
\end{vmatrix}
\end{array}
\end{array}
这些嵌入向量的值介于 0 和 1 之间,先用随机数来填充一下矩阵。随着我们的 transformer 开始理解词语之间的含义,这些值随后会通过计算了更新。
Step5-计算Positional Embedding
根据嵌入向量中第 i 个值的每个词的位置,有两种计算位置嵌入Positional Embedding的公式:
\begin{array}{l}
For\space even\space position \\
PE_{(pos,2i)}=\sin(pos/10000^{2i/d_{model} } ) \\ \\
For\space odd\space position \\
PE_{(pos,2i+1)}=\cos(pos/10000^{2i/d_{model} } )
\end{array}
我们的输入句子是“马无夜草不肥”,起始词是“马” ,起始索引(POS)值为 0,维度(d)为 6。对于 i 从 0 to 5 ,计算输入句子第一个词的位置嵌入Positional Embedding:
\begin{array}{l}
\begin{matrix}
马 \\
11
\end{matrix} \\ \\
\begin{array}{l}
\end{array}
\begin{bmatrix}
i& e1 & Position & Formula & p1\\
0& 0.79 & Even & \sin(0/10000^{2*0/6 } ) & 0\\
1& 0.6 & Odd & \cos(0/10000^{2*1/6 } ) & 1\\
2& 0.96 & Even & \sin(0/10000^{2*2/6 } ) & 0\\
3& 0.64 & Odd & \cos(0/10000^{2*3/6 } ) & 1\\
4& 0.97 & Even & \sin(0/10000^{2*4/6 } ) & 0\\
5& 0.2 & Odd & \cos(0/10000^{2*5/6 } ) &1
\end{bmatrix}\\
\begin{array}{l}
d(dim) \space\space\space 6 \\
POS \space\space\space\space\space\space 0
\end{array}
\end{array}
同样为输入句子马无夜草不肥中的所有字计算位置嵌入:
\begin{array}{l}
\begin{matrix}
\begin{matrix}
马 & 无 & 夜 & 草 & 不 & 肥 \\
11 & 12 & 13 & 14 & 15 &16
\end{matrix}
\end{matrix} \\ \\
\begin{array}{l}
\end{array}
\begin{bmatrix}
i& p1 & p2 & p3 & p4& p5& p6\\
0& 0 & 0.8415 & 0.9093 & 0& -0.7568& -0.9589\\
1& 1 & 0.0464 & 0.9957 & 1& 0.1846& 0.9732\\
2& 0 & 0.0022 & 0.0043 & 0& 0.0086& 0.0108\\
3& 1 & 0.0001 & 1 & 1& 0.0003& 1\\
4& 0 & 0 & 0 & 0& 0& 0\\
5& 1 & 0 & 1 &0& 0& 1
\end{bmatrix}
\Rightarrow \left\{\begin{matrix}
Position \\ Embedding
\end{matrix}\right.
\end{array}
Step6-整合Word and Positional Embedding
\begin{array}{l}
Word\space Embedding + Position\space Embedding = \\ \\
\begin{vmatrix}
0.68 & 0.13 & 0.27 & 0.38 & 0.75 & 0.94 \\
0.23 & 0.43 & 0.53 & 0.12 & 0.54 & 0.76 \\
0.10 & 0.16 & 0.39 & 0.15 & 0.34 & 0.34 \\
0.56 & 0.34 & 0.18 & 0.45 & 0.54 & 0.73 \\
0.09 & 0.29 & 0.75 & 0.54 & 0.21 & 0.67 \\
0.65 & 0.04 & 0.43 & 0.32 & 0.22 & 0.33
\end{vmatrix} +
\begin{vmatrix}
0 & 0.8415 & 0.9093 & 0& -0.7568& -0.9589\\
1 & 0.0464 & 0.9957 & 1& 0.1846& 0.9732\\
0 & 0.0022 & 0.0043 & 0& 0.0086& 0.0108\\
1 & 0.0001 & 1 & 1& 0.0003& 1\\
0 & 0 & 0 & 0& 0& 0\\
1 & 0 & 1 &0& 0& 1
\end{vmatrix} \\ \\
=
\begin{vmatrix}
0.79 & 0.38 & 0.01 & 0.12& 0.88& 0.6\\
0.6 & 0.12 & 0.51 & 0.6& 0.41& 0.33\\
0.96 & 0.06 & 0.27 & 0.65& 0.79& 0.75\\
0.64 & 0.79 & 0.31 & 0.22& 0.62& 0.48\\
0.97 & 0.9 & 0.56 & 0.07& 0.5& 0.94\\
0.2 & 0.74 & 0.59 &0.37& 0.7& 0.21
\end{vmatrix} = \oplus
\end{array}
这个由两个矩阵(词嵌入矩阵和位置嵌入矩阵)组合而成的结果矩阵将被视为编码部分的输入。
Step7-多头注意力
多头注意力由许多单头注意力组成,需要组合多少个单头注意力取决于我们。例如,Meta 的 LLaMA LLM 在编码器架构中使用了 32 个单头注意力。以下是单头注意力外观的示意图:
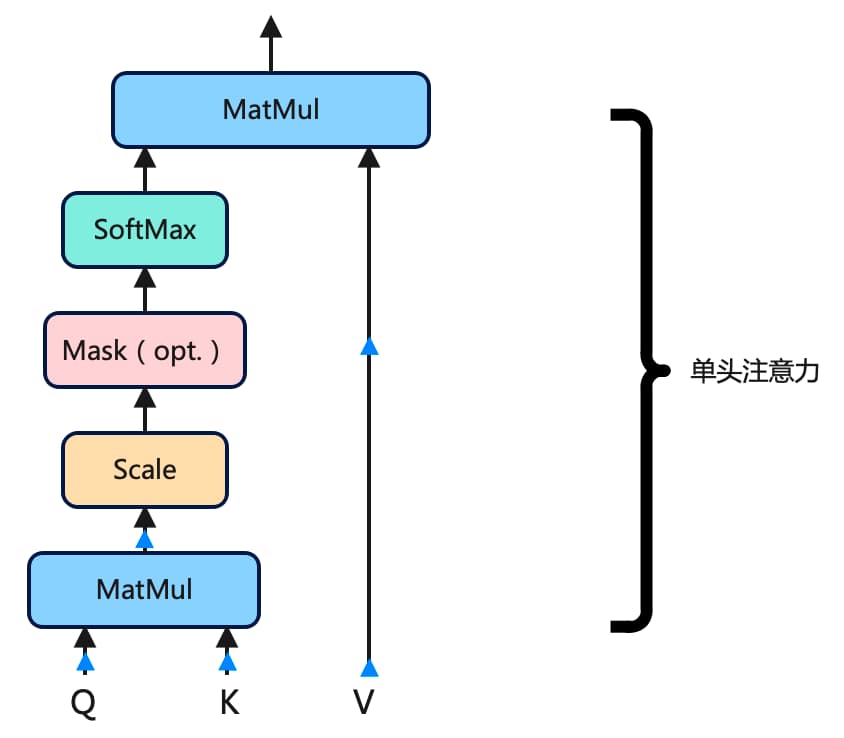
单头注意力机制在 Transformer 中有三个输入:查询Query、键Key和值Value。
QKV矩阵是通过将之前计算的相同矩阵的转置与词嵌入矩阵和位置嵌入矩阵相加,乘以不同的权重矩阵获得的。
假设,为了计算查询矩阵Query,权重矩阵的行数必须与转置矩阵的列数相同,而权重矩阵的列数可以是任意的;例如,我们假设权重矩阵中有4列。权重矩阵中的值是0和1之间随机数:
\begin{array}{l}
Word\space Embedding + Position\space Embedding \space\space\space Liner weight for query\\ \\
\begin{vmatrix}
马&0.79 & 0.38 & 0.01 & 0.12& 0.88& 0.6\\
无&0.6 & 0.12 & 0.51 & 0.6& 0.41& 0.33\\
夜&0.96 & 0.06 & 0.27 & 0.65& 0.79& 0.75\\
草&0.64 & 0.79 & 0.31 & 0.22& 0.62& 0.48\\
不&0.97 & 0.9 & 0.56 & 0.07& 0.5& 0.94\\
肥&0.2 & 0.74 & 0.59 &0.37& 0.7& 0.21
\end{vmatrix} \times
\begin{vmatrix}
0.27 & 0.38 & 0.75 & 0.94 \\
0.53 & 0.12 & 0.54 & 0.76 \\
0.39 & 0.15 & 0.34 & 0.34 \\
0.18 & 0.45 & 0.54 & 0.73 \\
0.75 & 0.54 & 0.21 & 0.67 \\
0.43 & 0.32 & 0.22 & 0.33
\end{vmatrix}
\end{array}
计算查询矩阵Query
使用相同的程序来计算键 和值 矩阵,但权重矩阵中的值必须对两者都不同。
\begin{array}{l}
Word\space Embedding + Position\space Embedding \space\space\space Liner weight for query\\
\begin{vmatrix}
马&0.79 & 0.38 & 0.01 & 0.12& 0.88& 0.6\\
无&0.6 & 0.12 & 0.51 & 0.6& 0.41& 0.33\\
夜&0.96 & 0.06 & 0.27 & 0.65& 0.79& 0.75\\
草&0.64 & 0.79 & 0.31 & 0.22& 0.62& 0.48\\
不&0.97 & 0.9 & 0.56 & 0.07& 0.5& 0.94\\
肥&0.2 & 0.74 & 0.59 &0.37& 0.7& 0.21
\end{vmatrix} \times
\begin{vmatrix}
0.27 & 0.38 & 0.75 & 0.94 \\
0.53 & 0.12 & 0.54 & 0.76 \\
0.39 & 0.15 & 0.34 & 0.34 \\
0.18 & 0.45 & 0.54 & 0.73 \\
0.75 & 0.54 & 0.21 & 0.67 \\
0.43 & 0.32 & 0.22 & 0.33
\end{vmatrix}\\ \\
Word\space Embedding + Position\space Embedding \space\space\space Liner weight for query\\
\begin{vmatrix}
马&0.79 & 0.38 & 0.01 & 0.12& 0.88& 0.6\\
无&0.6 & 0.12 & 0.51 & 0.6& 0.41& 0.33\\
夜&0.96 & 0.06 & 0.27 & 0.65& 0.79& 0.75\\
草&0.64 & 0.79 & 0.31 & 0.22& 0.62& 0.48\\
不&0.97 & 0.9 & 0.56 & 0.07& 0.5& 0.94\\
肥&0.2 & 0.74 & 0.59 &0.37& 0.7& 0.21
\end{vmatrix} \times
\begin{vmatrix}
0.27 & 0.38 & 0.75 & 0.94 \\
0.53 & 0.12 & 0.54 & 0.76 \\
0.39 & 0.15 & 0.34 & 0.34 \\
0.18 & 0.45 & 0.54 & 0.73 \\
0.75 & 0.54 & 0.21 & 0.67 \\
0.43 & 0.32 & 0.22 & 0.33
\end{vmatrix}
\end{array}
在矩阵相乘后,得到的结果查询Query、键Key 和值Value 如下:
\begin{array}{l}
Query =
\begin{vmatrix}
0.27 & 0.38 & 0.75 & 0.94 \\
0.53 & 0.12 & 0.54 & 0.76 \\
0.39 & 0.15 & 0.34 & 0.34 \\
0.18 & 0.45 & 0.54 & 0.73 \\
0.75 & 0.54 & 0.21 & 0.67 \\
0.43 & 0.32 & 0.22 & 0.33
\end{vmatrix}
key =
\begin{vmatrix}
0.27 & 0.38 & 0.75 & 0.94 \\
0.53 & 0.12 & 0.54 & 0.76 \\
0.39 & 0.15 & 0.34 & 0.34 \\
0.18 & 0.45 & 0.54 & 0.73 \\
0.75 & 0.54 & 0.21 & 0.67 \\
0.43 & 0.32 & 0.22 & 0.33
\end{vmatrix}
Value =
\begin{vmatrix}
0.27 & 0.38 & 0.75 & 0.94 \\
0.53 & 0.12 & 0.54 & 0.76 \\
0.39 & 0.15 & 0.34 & 0.34 \\
0.18 & 0.45 & 0.54 & 0.73 \\
0.75 & 0.54 & 0.21 & 0.67 \\
0.43 & 0.32 & 0.22 & 0.33
\end{vmatrix}
\end{array}
计算单头注意力
\begin{array}{l}
Query \times Transpose(Key) = \\
\begin{vmatrix}
0.27 & 0.38 & 0.75 & 0.94 \\
0.53 & 0.12 & 0.54 & 0.76 \\
0.39 & 0.15 & 0.34 & 0.34 \\
0.18 & 0.45 & 0.54 & 0.73 \\
0.75 & 0.54 & 0.21 & 0.67 \\
0.43 & 0.32 & 0.22 & 0.33
\end{vmatrix} +
\begin{vmatrix}
0.79 & 0.38 & 0.01 & 0.12& 0.88& 0.6\\
0.6 & 0.12 & 0.51 & 0.6& 0.41& 0.33\\
0.96 & 0.06 & 0.27 & 0.65& 0.79& 0.75\\
0.64 & 0.79 & 0.31 & 0.22& 0.62& 0.48
\end{vmatrix} \\
= \begin{vmatrix}
0.79 & 0.38 & 0.01 & 0.12& 0.88& 0.6\\
0.6 & 0.12 & 0.51 & 0.6& 0.41& 0.33\\
0.96 & 0.06 & 0.27 & 0.65& 0.79& 0.75\\
0.64 & 0.79 & 0.31 & 0.22& 0.62& 0.48\\
0.97 & 0.9 & 0.56 & 0.07& 0.5& 0.94\\
0.2 & 0.74 & 0.59 &0.37& 0.7& 0.21
\end{vmatrix} = MatMul
\end{array}
为了缩放结果矩阵,我们必须重复使用我们的嵌入向量(embedding vector)的维度,即6。
\begin{array}{l}
\left.\begin{matrix}
\begin{vmatrix}
0.79 & 0.38 & 0.01 & 0.12& 0.88& 0.6\\
0.6 & 0.12 & 0.51 & 0.6& 0.41& 0.33\\
0.96 & 0.06 & 0.27 & 0.65& 0.79& 0.75\\
0.64 & 0.79 & 0.31 & 0.22& 0.62& 0.48\\
0.97 & 0.9 & 0.56 & 0.07& 0.5& 0.94\\
0.2 & 0.74 & 0.59 &0.37& 0.7& 0.21
\end{vmatrix}
\end{matrix}\right\}Scale = \sqrt{d_{k} }
\\
=
\begin{bmatrix}
23.81721 & 12.77409 & 20.30219 & 6.307436& 11.50852& 17.62\\
14.1009 & 7.434201 & 8.062904 & 2.535222& 6.781004& 10.47973\\
20.77167 & 11.186 & 12.09231 & 0& 10.01433& 15.39096\\
7.401542 & 3.972256 & 4.809165 & 3.64974& 3.612997& 5.466445\\
10.76551 & 5.752218 & 17.65266 & 14.54997 & 5.184753& 7.956759\\
17.10152 & 9.254989 & 6.976963 &5.715476& 8.205791& 12.62712
\end{bmatrix} = Scale
\end{array}
计算掩码
掩码就像告诉模型只关注某个点之前发生的事情,在确定句子中不同单词的重要性时不要窥视未来。它帮助模型以逐步的方式理解事物,而不会通过提前查看来作弊。
softmax
s(x_{i} ) = \frac{e^{x_{i} } }{ {\textstyle \sum_{n}^{j=1}e^{x_{j} } } }
\begin{array}{}
\begin{bmatrix}
23.82 & 12.77 & 20.30 & 6.31& 11.51& 17.62\\
14.10 & 7.43 & 8.06 & 2.54& 6.78& 10.48\\
20.77 & 11.18 & 12.09 & 6.98& 10.01& 15.39\\
7.40 & 3.978 & 4.81 & 3.65& 3.61& 5.47\\
10.77 & 5.758 & 17.65 & 14.55 & 5.18& 7.96\\
17.10 & 9.258 & 6.98 &5.72& 8.21& 12.63
\end{bmatrix} \\
\Downarrow \\ softmax(23.82)=\frac{e^{23.82} }{e^{23.82} + e^{12.77}+ e^{20.3}+ e^{8.06}+ e^{11.51}+ e^{17.62} }=0.9693
\\ \downarrow \\
\begin{bmatrix}
0.9693 & 0 & 0.0287 & 0.0006 & 0 & 0.047 \\
0.86 & 0.0011 & 0.1152 & 0.0001 & 0.0006 & 0.0105 \\
0.9534 & 0.0001 & 0.0421 & 0 & 0 & 0.0044 \\
0.6476 & 0.021 & 0.2177 & 0.005 & 0.0146 & 0.094 \\
0.7803 & 0.0052 & 0.164 & 0.0006 & 0.0029 & 0.047 \\
0.9174 & 0.0004 & 0.0716 & 0 & 0.0001 & 0.0105
\end{bmatrix}
\Longrightarrow SoftMax
\end{array}
执行最终的乘法步骤以从单头注意力中获取结果矩阵。
\begin{array}{}
softmax \times Value
\\ \Downarrow \\
\begin{bmatrix}
0.9693 & 0 & 0.0287 & 0.0006 & 0 & 0.047 \\
0.86 & 0.0011 & 0.1152 & 0.0001 & 0.0006 & 0.0105 \\
0.9534 & 0.0001 & 0.0421 & 0 & 0 & 0.0044 \\
0.6476 & 0.021 & 0.2177 & 0.005 & 0.0146 & 0.094 \\
0.7803 & 0.0052 & 0.164 & 0.0006 & 0.0029 & 0.047 \\
0.9174 & 0.0004 & 0.0716 & 0 & 0.0001 & 0.0105
\end{bmatrix} \times
\begin{bmatrix}
3.88 & 3.8 & 4.08 & 2.22 \\
2.55 & 1.86 & 2.77 & 1.78 \\
3.39 & 3.6 & 3.49 & 2.27 \\
1.02 & 1.18 & 1.24 & 1.3 \\
1.9 & 1.56 & 1.88 & 1.53 \\
3.04 & 2.9 & 2.73 & 2.22
\end{bmatrix} \\
= \begin{bmatrix}
3.864257 & 3.79246 & 4.060367 & 3.39751 \\
3.801295 & 3.75252 & 3.977937 & 3.30861 \\
3.855542 & 3.787426 & 4.04909 & 3.385086 \\
3.622841 & 3.584936 & 3.750419 & 3.081834 \\
3.745786 & 3.706744 & 3.904894 & 3.233519 \\
3.835366 & 3.77523 & 4.022837 & 3.356435
\end{bmatrix}
\Longrightarrow MatMul(2)
\end{array}
在任何情况下,无论是单头注意力还是多头注意力,结果矩阵都需要再次通过乘以一组权重矩阵进行线性变换。
\begin{array}{}
[softmax \times Value ] \times Linear \space weights \\
\Downarrow \\
\begin{bmatrix}
3.86 & 3.79 & 4.06 & 3.39 \\
3.80 & 3.75 & 3.97 & 3.30 \\
3.85 & 3.78 & 4.04 & 3.38 \\
3.62 & 3.58 & 3.75 & 3.08 \\
3.74 & 3.70 & 3.90 & 3.23 \\
3.83 & 3.77 & 4.02 & 3.36
\end{bmatrix} \times
\begin{vmatrix}
0.79 & 0.38 & 0.01 & 0.12& 0.88& 0.6\\
0.6 & 0.12 & 0.51 & 0.6& 0.41& 0.33\\
0.96 & 0.06 & 0.27 & 0.65& 0.79& 0.75\\
0.64 & 0.79 & 0.31 & 0.22& 0.62& 0.48
\end{vmatrix} \\
= \begin{vmatrix}
10.84 & 9.45 & 7.33 & 6.09 & 7.66 & 7.09 \\
10.65 & 9.28 & 7.22 & 5.99 & 7.51 & 7.38 \\
10.83 & 9.43 & 7.33 & 6.08 & 7.65 & 7.6 \\
10.08 & 8.77 & 6.85 & 5.67 & 7.66 & 7.33 \\
10.48 & 9.12 & 7.11 & 5.89 & 7.51 & 7.22 \\
10.77 & 9.38 & 7.29 & 6.05 & 7.65 & 7.33
\end{vmatrix} = Mult \space head \space Attention
\end{array}
多个单头注意力
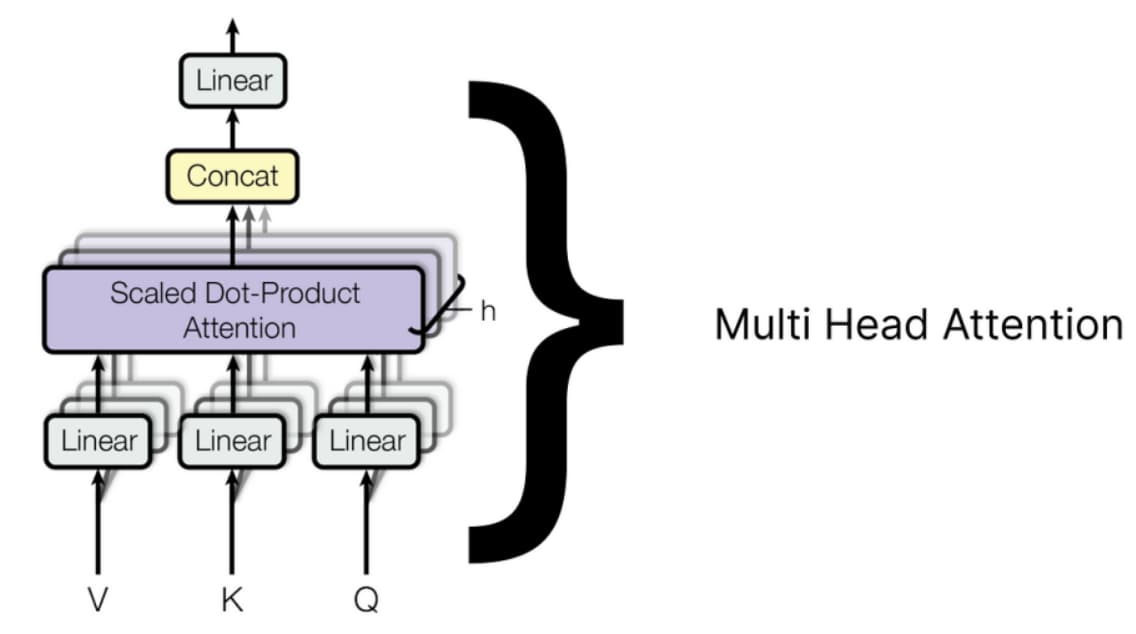
每个单头注意力有三个输入:查询、键和值,每个都有不同的权重集。一旦所有单头注意力输出它们的结果矩阵,它们将被连接起来,最终的连接矩阵再次通过乘以一组随机初始化的权重矩阵进行线性变换,这些权重矩阵将在 transformer 开始训练时进行更新。
Step8-添加层归一化
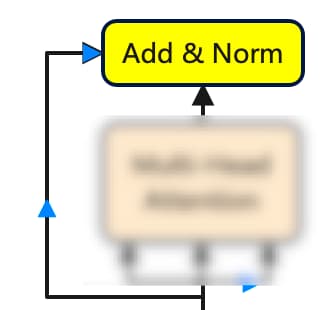
当从多头注意力中获取到结果矩阵后,接下来就是将其添加到原始矩阵中。为了规范化上述矩阵,计算每行的均值和标准差,并用矩阵中每个值减去对应行的平均值,然后除以对应的标准差。其中添加一个小的误差值可以防止分母为零,从而避免使整个项趋于无穷大。
\begin{array}{}
[Word \space Embedding + Position \space Embedding] + Output \space of \space Multi \space Head \space attentiona
\\ \Downarrow \\
\begin{vmatrix}
马&0.79 & 0.38 & 0.01 & 0.12& 0.88& 0.6\\
无&0.6 & 0.12 & 0.51 & 0.6& 0.41& 0.33\\
夜&0.96 & 0.06 & 0.27 & 0.65& 0.79& 0.75\\
草&0.64 & 0.79 & 0.31 & 0.22& 0.62& 0.48\\
不&0.97 & 0.9 & 0.56 & 0.07& 0.5& 0.94\\
肥&0.2 & 0.74 & 0.59 &0.37& 0.7& 0.21
\end{vmatrix} +
\begin{vmatrix}
10.84 & 9.45 & 7.33 & 6.09 & 7.66 & 7.09 \\
10.65 & 9.28 & 7.22 & 5.99 & 7.51 & 7.38 \\
10.83 & 9.43 & 7.33 & 6.08 & 7.65 & 7.6 \\
10.08 & 8.77 & 6.85 & 5.67 & 7.66 & 7.33 \\
10.48 & 9.12 & 7.11 & 5.89 & 7.51 & 7.22 \\
10.77 & 9.38 & 7.29 & 6.05 & 7.65 & 7.33
\end{vmatrix}\\
= \begin{vmatrix}
11.63 & 11.05 & 8.29 & 7.47 & 7.06 & 8.86 \\
11.87 & 9.45 & 7.28 & 8.16 & 6.89 & 8.25 \\
11.75 & 10.94 & 7.6 & 9.23 & 6.64 & 9.24 \\
10.34 & 9.51 & 7.51 & 7.46 & 5.74 & 7.46 \\
10.6 & 9.71 & 7.91 & 8.08 & 6.39 & 8.08 \\
10.41 & 10.68 & 8.05 & 9.1 & 6.99 & 8.81
\end{vmatrix} \longrightarrow
\begin{array}{}
规范化矩阵:计算平均值和标准差 \\
mean = \frac{ {\textstyle \sum_{i=1}^{N}} }{X_{i} } \\
standard \space dev. = \sqrt{\frac{ {\textstyle \sum_{i=1}^{N}(X_{i}-\mu )^{2}} }{N} }
\end{array} \\
\begin{bmatrix}
Mean & Standard \space Deviation \\
9.26 & 1.57 \\
8.56 & 1.64 \\
9.04 & 1.76 \\
7.86 & 1.51 \\
8.37 & 1.35 \\
8.93 & 1.28
\end{bmatrix}\longrightarrow
\begin{array}{}
减平均值,除以标准差 Add \space and \space Norm\\
\begin{vmatrix}
1.51 & 1.14 & -0.62 & 0.11 & -1.4 & -0.25 \\
2.02 & 0.54 & -0.78 & -0.06 & -1.02 & -0.19 \\
1.54 & 1.08 & -0.82 & 0.03 & -1.36 & 0.11 \\
1.64 & 1.09 & -0.23 & -0.26 & -1.4 & -0.26 \\
1.65 & 0.99 & -0.34 & -0.16 & -1.47 & -0.21 \\
1.16 & 1.37 & -0.69 & 0.23 & -1.52 & -0.09
\end{vmatrix}
\end{array}
\end{array}
Step9-前馈网络(Feed Network)
在将矩阵归一化后,它将通过前馈网络进行处理。我们将使用一个非常基本的网络,该网络只包含一个线性层和一个 ReLU 激活函数层。
\left.\begin{matrix}
RELU = max(0,x)\\
\uparrow \\
Linear \space Layser = X*W+b
\end{matrix}\right\}\Rightarrow 前馈网络(Feed \space Forward)
首先,通过将最后计算的矩阵与一组随机的权重矩阵相乘来计算线性层,该权重矩阵在 transformer 开始学习时将更新,并将结果矩阵添加到一个也包含随机值的偏置矩阵中。在计算线性层之后,将其通过 ReLU 层并使用公式计算。
\begin{array}{}
\begin{array}{}
Matrix \space afrer \space add \space and \space norm \space step \\
\begin{vmatrix}
1.51 & 1.14 & -0.62 & 0.11 & -1.4 & -0.25 \\
2.02 & 0.54 & -0.78 & -0.06 & -1.02 & -0.19 \\
1.54 & 1.08 & -0.82 & 0.03 & -1.36 & 0.11 \\
1.64 & 1.09 & -0.23 & -0.26 & -1.4 & -0.26 \\
1.65 & 0.99 & -0.34 & -0.16 & -1.47 & -0.21 \\
1.16 & 1.37 & -0.69 & 0.23 & -1.52 & -0.09
\end{vmatrix} \end{array} \times
\begin{array}{}
W \\
\begin{vmatrix}
10.84 & 9.45 & 7.33 & 6.09 & 7.66 & 7.09 \\
10.65 & 9.28 & 7.22 & 5.99 & 7.51 & 7.38 \\
10.83 & 9.43 & 7.33 & 6.08 & 7.65 & 7.6 \\
10.08 & 8.77 & 6.85 & 5.67 & 7.66 & 7.33 \\
10.48 & 9.12 & 7.11 & 5.89 & 7.51 & 7.22 \\
10.77 & 9.38 & 7.29 & 6.05 & 7.65 & 7.33
\end{vmatrix} \end{array} \\ \\
\begin{array}{}
\begin{array}{}
X*W
\end{array} \\
\begin{array}{}
\begin{bmatrix}
0.49 & 1.07 & 0.84 & 0.14 & 0.26 & 0.7 \\
0.24 & 1.26 & 1.11 & 0.12 & 0.22 & 0.97 \\
0.53 & 1.18 & -0.82 & 0.39 & 0.46 & 0.59 \\
0.53 & 0.97 & 0.98 & 0.15 & 0.33 & 0.52 \\
0.56 & 1.11 & -0.87 & 0.11 & 0.16 & 0.64 \\
0.62 & 1.02 & 0.61 & 0.2 & 0.2 & 0.52
\end{bmatrix} +
\end{array}
\begin{array}{}
Bias\\
\begin{bmatrix}
b1 & b2 & b3 & b4 & b5 & b6\\
0.42 & 0.18 & 0.25 & 0.42 & 0.35 & 0.45
\end{bmatrix}
\end{array}
\end{array} \\
= \begin{bmatrix}
0.91 & 1.25 & 1.09 & 0.56 & 0.68 & 1.15 \\
0.66 & 1.44 & 1.36 & 0.54 & 0.57 & 1.42 \\
0.95 & 1.36 & -0.57 & 0.81 & 0.53 & 1.04 \\
0.95 & 1.15 & 1.23 & 0.57 & 0.68 & 0.97 \\
0.98 & 1.29 & -0.62 & 0.51 & 0.51 & 1.09 \\
1.04 & 1.2 & 0.86 & 0.55 & 0.55 & 0.97
\end{bmatrix} \\ \Downarrow \\
\begin{array}{}
ReLU(x) =max(0,x) \\
\begin{bmatrix}
0.91 & 1.25 & 1.09 & 0.56 & 0.68 & 1.15 \\
0.66 & 1.44 & 1.36 & 0.54 & 0.57 & 1.42 \\
0.95 & 1.36 & -0.57 & 0.81 & 0.53 & 1.04 \\
0.95 & 1.15 & 1.23 & 0.57 & 0.68 & 0.97 \\
0.98 & 1.29 & -0.62 & 0.51 & 0.51 & 1.09 \\
1.04 & 1.2 & 0.86 & 0.55 & 0.55 & 0.97
\end{bmatrix}
\end{array} \\
\Rightarrow \begin{bmatrix}
0.91 & 1.25 & 1.09 & 0 & 0.68 & 1.15 \\
0.66 & 1.44 & 1.36 & 0 & 0.57 & 1.42 \\
0.95 & 1.36 & -0.57 & 0.86 & 0.53 & 1.04 \\
0.95 & 1.15 & 1.23 & 0.56 & 0.68 & 0.97 \\
0.98 & 1.29 & 0 & 0.54 & 0.51 & 1.09 \\
1.04 & 1.2 & 0.81 & 0.81 & 0.55 & 0.97
\end{bmatrix} = Feed \space Forward
\end{array}
Step10-再次添加层归一化
从前馈网络获得结果矩阵,我们必须将其添加到从先前添加和归一化步骤获得的矩阵中,然后使用行均值和标准差对其进行归一化。该加法和归一化步骤的输出矩阵将作为解码器部分中存在的多头注意力机制之一的查询和键矩阵,可以通过从加法和归一化追踪到解码器部分来轻松理解。
\begin{array}{}
Matrix \space from \space Feed \space Forward \space Network + Matrix \space from \space Previous \space Add \space Norm \space Step
\\ \Downarrow \\
\begin{vmatrix}
0.91 & 1.25 & 1.09 & 0 & 0.68 & 1.15 \\
0.66 & 1.44 & 1.36 & 0 & 0.57 & 1.42 \\
0.95 & 1.36 & -0.57 & 0.86 & 0.53 & 1.04 \\
0.95 & 1.15 & 1.23 & 0.56 & 0.68 & 0.97 \\
0.98 & 1.29 & 0 & 0.54 & 0.51 & 1.09 \\
1.04 & 1.2 & 0.81 & 0.81 & 0.55 & 0.97
\end{vmatrix} +
\begin{vmatrix}
1.51 & 1.14 & -0.62 & 0.11 & -1.4 & -0.25 \\
2.02 & 0.54 & -0.78 & -0.06 & -1.02 & -0.19 \\
1.54 & 1.08 & -0.82 & 0.03 & -1.36 & 0.11 \\
1.64 & 1.09 & -0.23 & -0.26 & -1.4 & -0.26 \\
1.65 & 0.99 & -0.34 & -0.16 & -1.47 & -0.21 \\
1.16 & 1.37 & -0.69 & 0.23 & -1.52 & -0.09
\end{vmatrix}\\
= \begin{vmatrix}
2.42 & 2.39 & 0.47 & 0.67 & -0.83 & 0.9 \\
2.68 & 1.98 & 0.58 & 0.48 & -0.21 & 1.23 \\
2.49 & 2.44 & -0.82 & 0.84 & -0.68 & 1.15 \\
2.59 & 2.24 & 1 & 0.31 & -0.89 & 0.71 \\
2.63 & 2.28 & -0.34 & 0.37 & -0.92 & 0.88 \\
2.2 & 2.57 & 0.17 & 0.91 & -1.03 & 0.88
\end{vmatrix} \longrightarrow
\begin{array}{}
规范化矩阵:计算平均值和标准差 \\
mean = \frac{ {\textstyle \sum_{i=1}^{N}} }{X_{i} } \\
standard \space dev. = \sqrt{\frac{ {\textstyle \sum_{i=1}^{N}(X_{i}-\mu )^{2}} }{N} }
\end{array} \\
\begin{bmatrix}
Mean & Standard \space Deviation \\
1.0033 & 1.103534 \\
1.1233 & 1.214349 \\
0.9033 & 1.301837 \\
0.9933 & 1.289055 \\
0.8167 & 1.306016 \\
0.95 & 1.320773
\end{bmatrix}\longrightarrow
\begin{array}{}
减平均值,除以标准差 Add \space and \space Norm\\
\begin{vmatrix}
1.28 & 1.26 & -0.48 & -0.89 & -1.66 & -0.09 \\
1.28 & 0.71 & -0.45 & -0.59 & -1.1 & 0.09 \\
1.22 & 1.18 & -1.32 & -0.3 & -1.22 & 0.19 \\
1.24 & 0.97 & 0.01 & -0.53 & -1.46 & -0.22 \\
1.39 & 1.12 & -0.89 & -0.05 & -1.33 & 0.05 \\
0.95 & 1.23 & -0.59 & -0.53 & -1.5 & -0.05
\end{vmatrix}
\end{array}
\end{array}
Step11-解码器
在训练时,解码器有两个输入。一个是来自编码器,其中最后一个加和归一化层的输出矩阵作为查询和键,用于解码器部分的第二个多头注意力层。
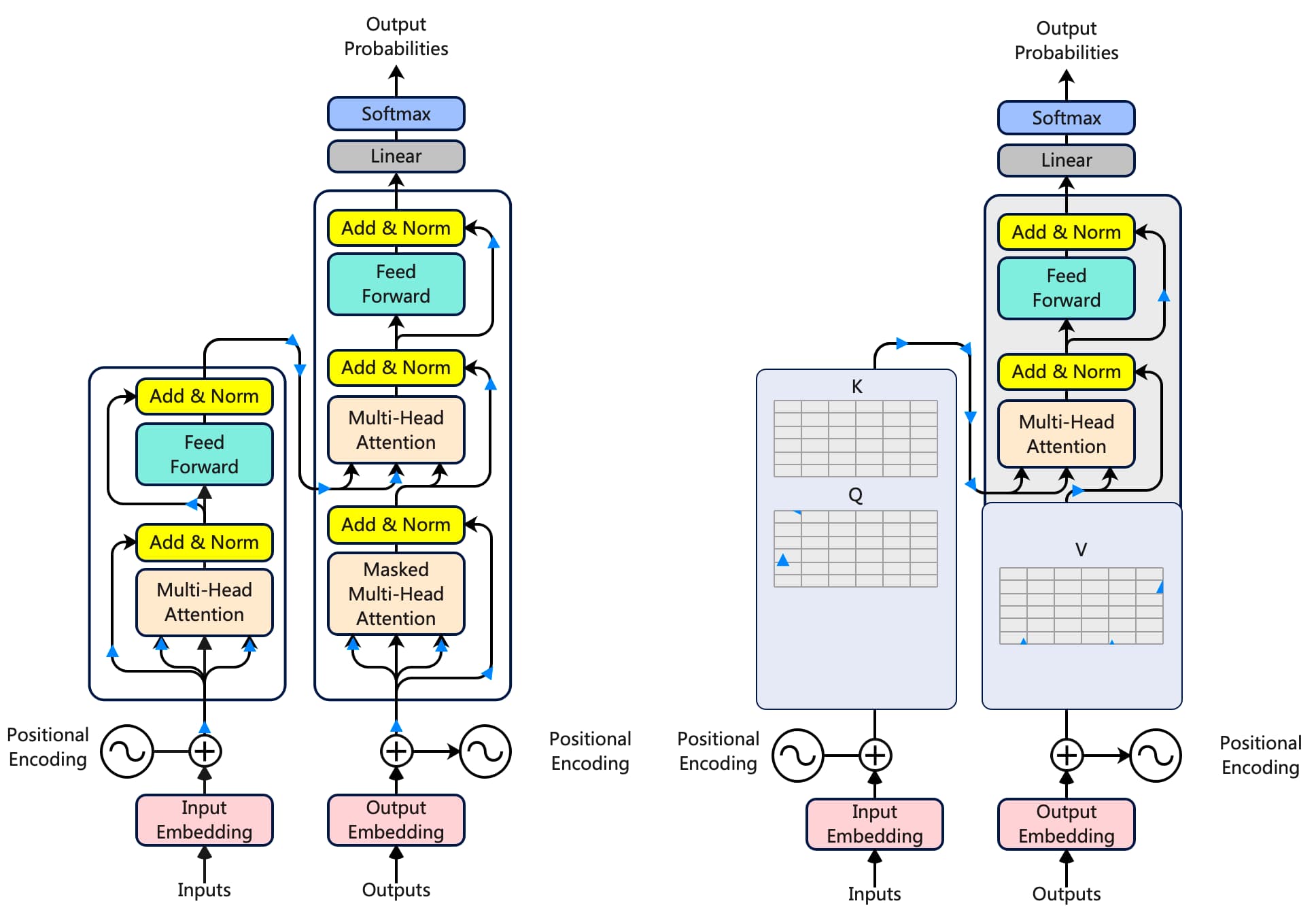
当值矩阵来自解码器在第一次添加和归一化 步骤之后。解码器的第二个输入是预测的文本。如果你还记得,我们输入到编码器的是马无夜草不肥,所以解码器的输入是预测的文本,在我们的例子中是人无横财不富。。
预测输入文本需要遵循一个标准的令牌包装,使 transformer 知道从哪里开始和在哪里结束。
\begin{array}{}
Encoder \space Input \longrightarrow 马 \space 无 \space 夜 \space 草 \space 不 \space 肥 \\
Decoder \space Input \longrightarrow <start> 人 \space 无 \space 横 \space 财 \space 不 \space 富<end>
\end{array}
在哪里<start> 和<end> 是两个新标记被引入。此外,解码器每次只接受一个标记作为输入。这意味着<start> 将作为输入,而人 必须是它的预测文本。
Step12-计算预测单词
输出矩阵必须包含与输入矩阵相同的行数,而列数可以是任何数量。解码器的最后一个添加和归一化块的结果矩阵必须展平,以便与线性层匹配,以找到我们数据集(语料库)中每个独特单词的预测概率。
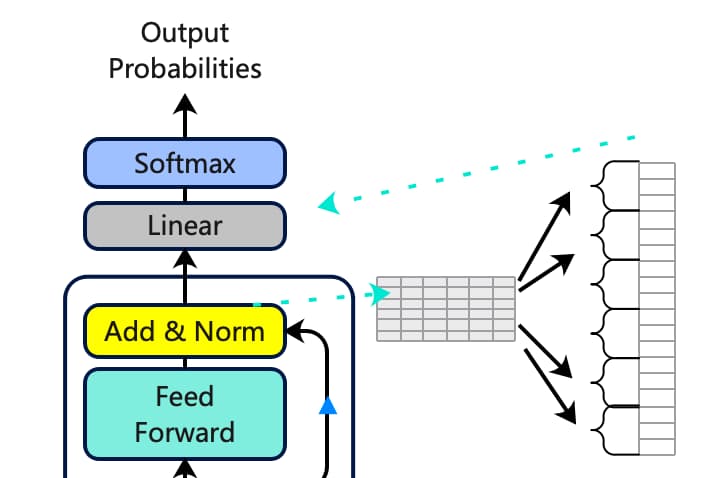
这个展平层将通过一个线性层传递,以计算数据集中每个独特单词的logits(得分),之后就可以使用softmax 函数对它们进行归一化,并找到包含最高概率的单词。
\begin{array}{}
Linear \space Layer=X*W \\ \\
\begin{array}{}
Flatten \space Layer(Row \space matrix) \\
\begin{matrix}
1.2&1.33&2.11&...&1.2&1.56&1.57&1.7
\end{matrix} \\
1 \times n
\end{array} \times
\begin{array}{}
Linear \space set \space of \space weights \\
\begin{matrix}
白&日&依&... &横\\
1&2&3 &...&18 \\ \\
0.28 & 0.72 & 0.14&···& 0.11 \\
0.1 & 0.5 & 0.93 &···& 0.37 \\
0.77 & 0.23 & 0.17 &···& 0.51 \\
0.23 & 0.62 & 0.99 &···& 0.76 \\
0.75 & 0.76 & 0.42 &···& 0.26 \\
0.02 & 0.52 & 0.47 &···& 0.24 \\
0.58 & 0.9 & 0.88 &···& 0.54 \\
... & ... & ... &···& ... \\
0.59 & 0.16 & 0.05 &···& 0.87 \\
0.35 & 0.02 & 0.84 & 0.67
\end{matrix} \\
n \times m (Vocab \space Size)
\end{array} \\ \\
\begin{array}{}
logits=\space
\end{array}
\begin{array}{}
\begin{matrix}
白&日&依&... &人&...&横\\
1&2&3 &...&17&... &18 \\ \\
1.14&2.3&1.15&...&5.4&...&2.3
\end{matrix} \\ \downarrow \\
\end{array} \\ \\
Applying \space softmax \space S(x_{i} )= \frac{e^{\lambda i} }{ {\textstyle \sum_{i=i}^{n}}e^{x_{j} } }
\\ \downarrow \\
\begin{array}{}
Probabilities =
\end{array}
\begin{array}{}
\begin{matrix}
白&日&依&... &人&...&横\\
1&2&3 &...&17&... &18 \\ \\
0.21&0.05&0.001&...&0.56&...&0.12
\end{matrix} \\
\space \space \space \space \space
\space \space \space \space \space
\space \space \space \space \space
\space \space \space \space \space
\begin{array}{}
\uparrow \\ highest \space Probability
\end{array}
\end{array} \\
\Rightarrow
\begin{bmatrix}
人\\
17 \\ \\
0.56
\end{bmatrix}
\Longrightarrow Output \space Probabilites
\end{array}



