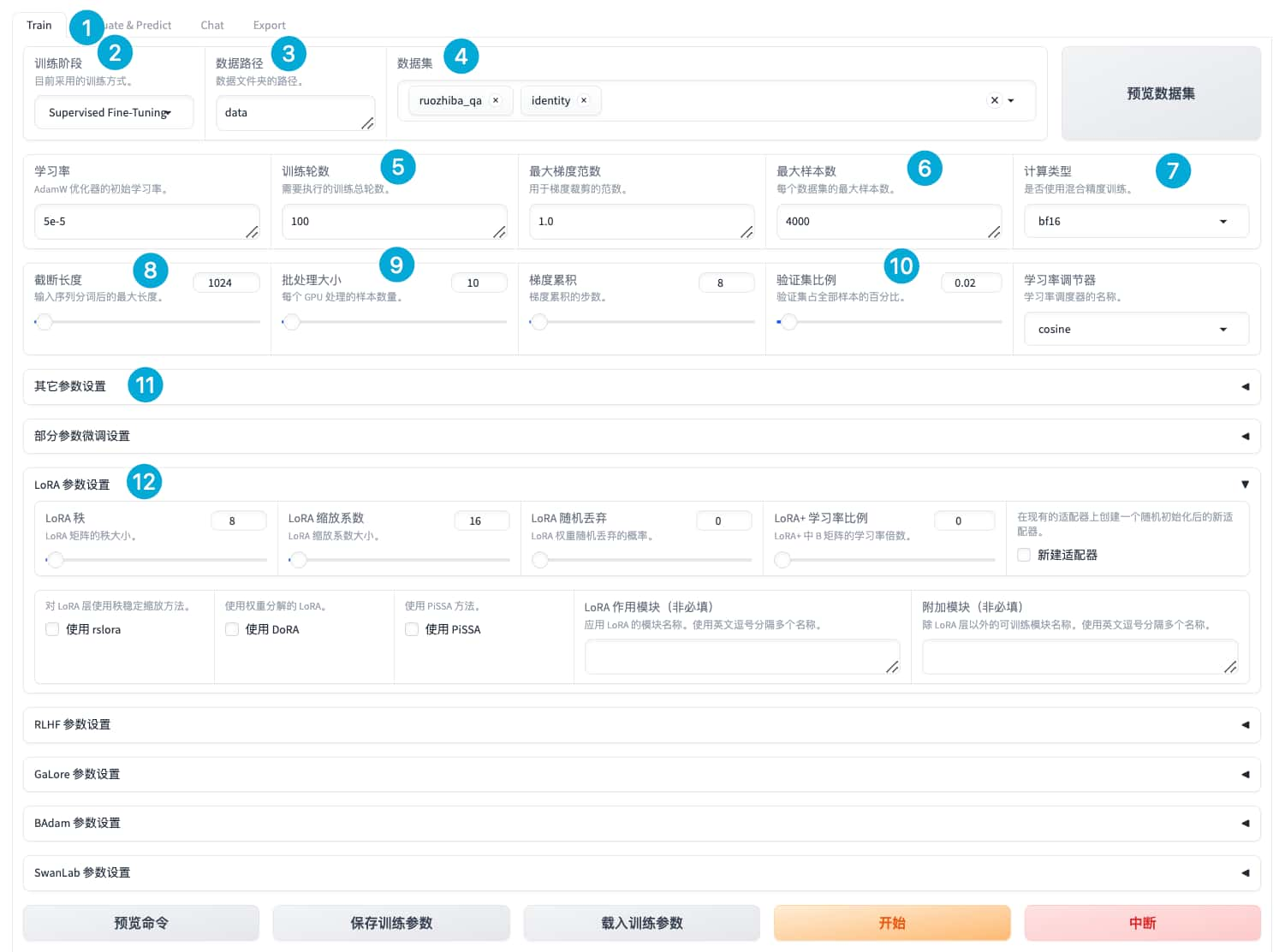
数据集
数据集下载:通过ModelScope获取原始数据集
git clone https://www.modelscope.cn/datasets/w10442005/ruozhiba_qa.git分析数据集信息
[
{
"system": "00000",
"query": "只剩一个心脏了还能活吗?",
"response": "能,人本来就只有一个心脏。"
},
{
"query": "爸爸再婚,我是不是就有了个新娘?",
"response": "不是的,你有了一个继母。\"新娘\"是指新婚的女方,而你爸爸再婚,他的新婚妻子对你来说是继母。"
},
{
"query": "樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买",
"response": "樟脑丸并不是硬糖,而是一种常见的驱虫药,不能食用。虽然它的味道可能不太好,但是由于其有效的驱虫效果,所以仍然有很多人会购买。"
},
......
]分析数据集信息可知,system 列对应的内容将被作为系统提示词、query 人类指令、response 列对应的内容为模型回答。
格式化数据集
在指令监督微调时,instruction 列对应的内容会与 input 列对应的内容拼接后作为人类指令,即人类指令为 instruction\ninput。而 output 列对应的内容为模型回答。
如果指定,system 列对应的内容将被作为系统提示词。
history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"ruozhiba_qa": {
"file_name": "ruozhiba_qaswift.json",
"columns": {
"prompt": "instruction",
"query": "query",
"response": "response",
"system": "system",
"history": "history"
}
}配置数据集
在Llama-Factory/data/dataset_info.json中配置ruozhiba_qa数据集,以便在微调时使用该数据集。
{
"ruozhiba_qa": {
"file_name": "ruozhiba_qaswift.json",
"columns": {
"prompt": "instruction",
"query": "query",
"response": "response",
"system": "system",
"history": "history"
}
},
"identity": {
"file_name": "identity.json"
},
......
}模型
模型选择
根据业务需求选择合适的模型基座,分类任务选择BERT模型,我们这里要实现的是GPT因此选择对中文支持较好的模型,这里我们在ModelScope中下载。
SDK模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('UnicomAI/Unichat-llama3.2-Chinese-1B')微调
# 启动Llama-Factory
root@VM-0-10-ubuntu:/workspace/LLaMA-Factory# llamafactory-cli webui
Running on local URL: http://0.0.0.0:7860配置训练参数
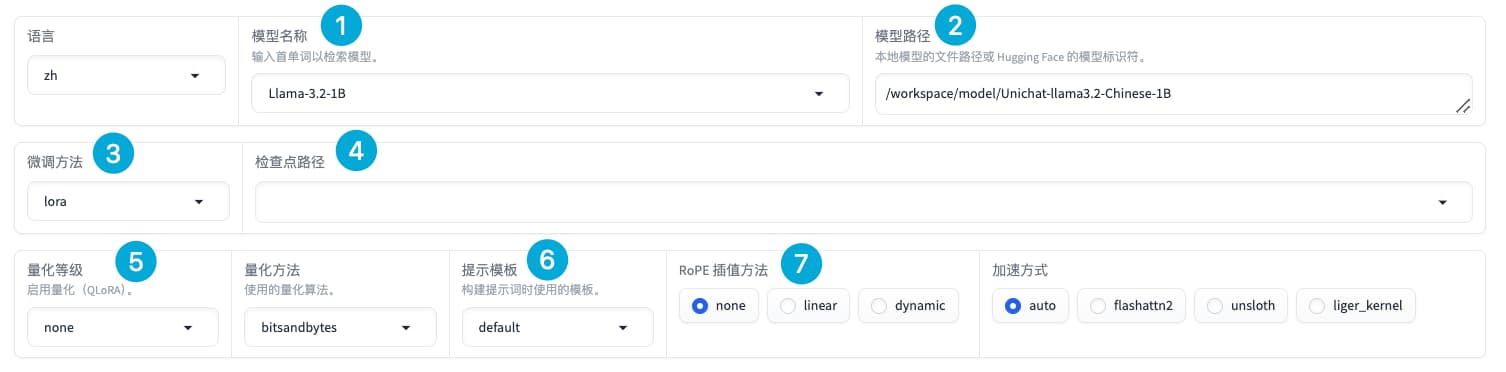
训练时nvitop展示的内存、gpu、cpu使用信息:
Tue Jan 14 14:14:05 2025
╒═════════════════════════════════════════════════════════════════════════════╕
│ NVITOP 1.4.0 Driver Version: 525.105.17 CUDA Driver Version: 12.0 │
├───────────────────────────────┬──────────────────────┬──────────────────────┤
│ GPU Name Persistence-M│ Bus-Id Disp.A │ Volatile Uncorr. ECC │
│ Fan Temp Perf Pwr:Usage/Cap│ Memory-Usage │ GPU-Util Compute M. │
╞═══════════════════════════════╪══════════════════════╪══════════════════════╪════════════════════╕
│ 0 Tesla T4 On │ 00000000:00:09.0 Off │ 0 │ MEM: ████████▋ 96% │
│ N/A 68C P0 69W / 70W │ 14689MiB / 15360MiB │ 100% Default │ UTL: █████████ MAX │
╘═══════════════════════════════╧══════════════════════╧══════════════════════╧════════════════════╛
[ CPU: ████████▋ 17.2% UPTIME: 5:51:02 ] ( Load Average: 1.27 1.21 1.19 )
[ MEM: █████████████████▍ 34.7% USED: 6.14GiB ] [ SWP: ▏ 0.0% ]
╒══════════════════════════════════════════════════════════════════════════════════════════════════╕
│ Processes: root@VM-0-10-ubuntu │
│ GPU PID USER GPU-MEM %SM %CPU %MEM TIME COMMAND │
╞══════════════════════════════════════════════════════════════════════════════════════════════════╡
│ 0 26022 C N/A 1304MiB 0 N/A N/A N/A No Such Process │
│ 0 51067 C N/A 13372MiB 99 N/A N/A N/A No Such Process │
╘══════════════════════════════════════════════════════════════════════════════════════════════════╛输出
(base) root@VM-0-10-ubuntu:/workspace/LLaMA-Factory/saves/Llama-3.2-1B/lora/train_2025-01-14-09-17-41# tree .
.
├── checkpoint-100
│ ├── README.md
│ ├── adapter_config.json
│ ├── adapter_model.safetensors
│ ├── optimizer.pt
│ ├── rng_state.pth
│ ├── scheduler.pt
│ ├── special_tokens_map.json
│ ├── tokenizer.json
│ ├── tokenizer_config.json
│ ├── trainer_state.json
│ └── training_args.bin
├── checkpoint-200
├── checkpoint-300
├── checkpoint-...
├── checkpoint-1800
├── eval_results.json
├── llamaboard_config.yaml
├── running_log.txt
├── special_tokens_map.json
├── tokenizer.json
├── tokenizer_config.json
├── train_results.json
├── trainer_log.jsonl
├── trainer_state.json
├── training_args.bin
├── training_args.yaml
├── training_eval_loss.png
└── training_loss.png
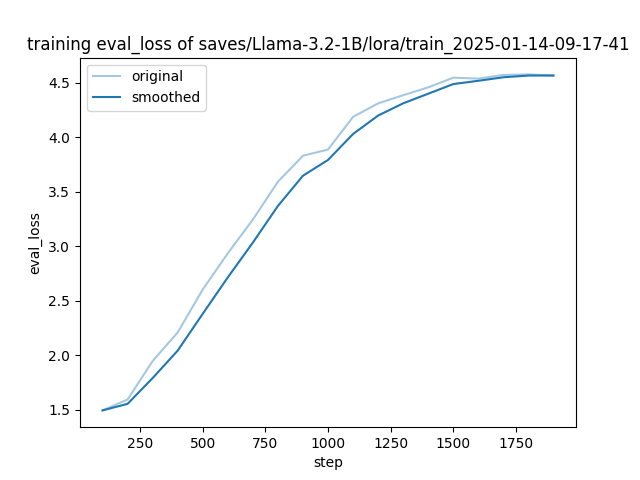
LoRA模型
LoRA模型路径:LLaMA-Factory/saves/Llama-3.2-1B/lora/train_2025-01-14-09-17-41/checkpoint-1800
每个checkpoint中内容为模型在微调过程中根据配置保存的检查点信息,这里并非是全量模型信息,不能单独使用,需要配合基座模型或与基座模型合并后使用推理。
.
├── README.md
├── adapter_config.json
├── adapter_model.safetensors
├── optimizer.pt
├── rng_state.pth
├── scheduler.pt
├── special_tokens_map.json
├── tokenizer.json
├── tokenizer_config.json
├── trainer_state.json
└── training_args.bin日志
检查点中trainer_state.json:
{
"best_metric": null,
"best_model_checkpoint": null,
"epoch": 10.320512820512821,
"eval_steps": 100,
"global_step": 200,
"is_hyper_param_search": false,
"is_local_process_zero": true,
"is_world_process_zero": true,
"log_history": [
{
"epoch": 0.2564102564102564,
"grad_norm": 0.7017256021499634,
"learning_rate": 4.999914564160437e-05,
"loss": 1.9317,
"step": 5
},
{
......
"step": 10
},
......
{
......
"step": 195
},
{
"epoch": 10.320512820512821,
"grad_norm": 1.2792272567749023,
"learning_rate": 4.864543104251587e-05,
"loss": 1.111,
"step": 200
},
{
"epoch": 10.320512820512821,
"eval_loss": 1.595388412475586,
"eval_runtime": 5.2144,
"eval_samples_per_second": 6.137,
"eval_steps_per_second": 0.767,
"step": 200
}
],
"logging_steps": 5,
"max_steps": 1900,
"num_input_tokens_seen": 0,
"num_train_epochs": 100,
"save_steps": 100,
"stateful_callbacks": {
"TrainerControl": {
"args": {
"should_epoch_stop": false,
"should_evaluate": false,
"should_log": false,
"should_save": true,
"should_training_stop": false
},
"attributes": {}
}
},
"total_flos": 1.621427114999808e+16,
"train_batch_size": 10,
"trial_name": null,
"trial_params": null
}
trainer_log.jsonl
{"current_steps": 5, "total_steps": 1900, "loss": 1.9317, "lr": 4.999914564160437e-05, "epoch": 0.2564102564102564, "percentage": 0.26, "elapsed_time": "0:03:41", "remaining_time": "23:19:06"}
......running_log.txt
***** Running Evaluation *****
[INFO|2025-01-14 13:35:36] trainer.py:4119 >> Num examples = 32
[INFO|2025-01-14 13:35:36] trainer.py:4122 >> Batch size = 10
[INFO|2025-01-14 13:35:41] trainer.py:3801 >> Saving model checkpoint to saves/Llama-3.2-1B/lora/train_2025-01-14-09-17-41/checkpoint-300
[INFO|2025-01-14 13:35:41] configuration_utils.py:677 >> loading configuration file /workspace/model/Unichat-llama3.2-Chinese-1B/config.json
[INFO|2025-01-14 13:35:41] configuration_utils.py:746 >> Model config LlamaConfig {
"_name_or_path": "/home/admin/workspace/llama3/LLaMA-Factory/saves/Llama-3.2-1B-Instruct/full/train_2024-10-12-9-52-30",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": [
128001,
128008,
128009
],
"head_dim": 64,
"hidden_act": "silu",
"hidden_size": 2048,
"initializer_range": 0.02,
"intermediate_size": 8192,
"max_position_embeddings": 131072,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 16,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": {
"factor": 32.0,
"high_freq_factor": 4.0,
"low_freq_factor": 1.0,
"original_max_position_embeddings": 8192,
"rope_type": "llama3"
},
"rope_theta": 500000.0,
"tie_word_embeddings": true,
"torch_dtype": "float32",
"transformers_version": "4.46.1",
"use_cache": true,
"vocab_size": 128256
}
[INFO|2025-01-14 13:35:41] tokenization_utils_base.py:2646 >> tokenizer config file saved in saves/Llama-3.2-1B/lora/train_2025-01-14-09-17-41/checkpoint-300/tokenizer_config.json
[INFO|2025-01-14 13:35:41] tokenization_utils_base.py:2655 >> Special tokens file saved in saves/Llama-3.2-1B/lora/train_2025-01-14-09-17-41/checkpoint-300/special_tokens_map.json
[INFO|2025-01-14 13:39:23] logging.py:157 >> {'loss': 0.8045, 'learning_rate': 4.6888e-05, 'epoch': 15.74}
......
[INFO|2025-01-14 14:49:36] logging.py:157 >> {'loss': 0.5252, 'learning_rate': 4.4729e-05, 'epoch': 20.64}
测试
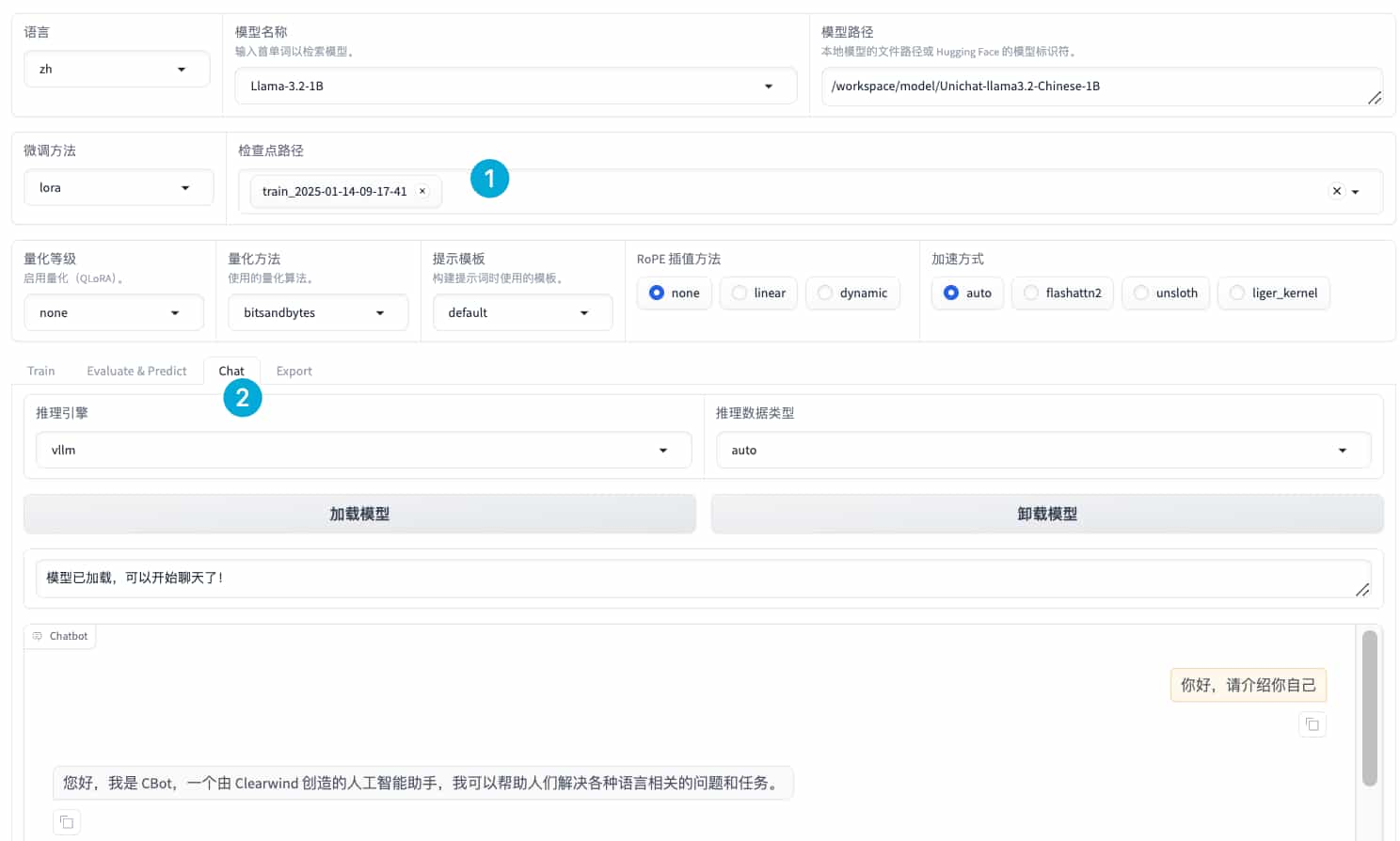
评估
我们知道,BERT模型和GPT模型分别试用不同的场景,分类任务时通常使用BERT,生成式任务使用GPT模型,而对于这两种模型的评估同样不能一概而论。针对具有确定性答案(eg:分类任务)的能力维度和场景,通过构造丰富完善的评测集,对模型能力进行综合评价。针对体现模型能力的开放式或半开放式(eg:大部分生成模型)的问题、模型安全问题等,采用主客观相结合的评测方式。
主观评估:语言表达生动精彩,变化丰富,大量的场景和能力无法凭借客观指标进行评测。针对如模型安全和模型语言能力的评测,以人的主观感受为主的评测更能体现模型的真实能力,并更符合大模型的实际使用场景。
客观评估:针对具有标准答案的客观问题,通过使用定量指标比较模型的输出与标准答案的差异,并根据结果衡量模型的性能。
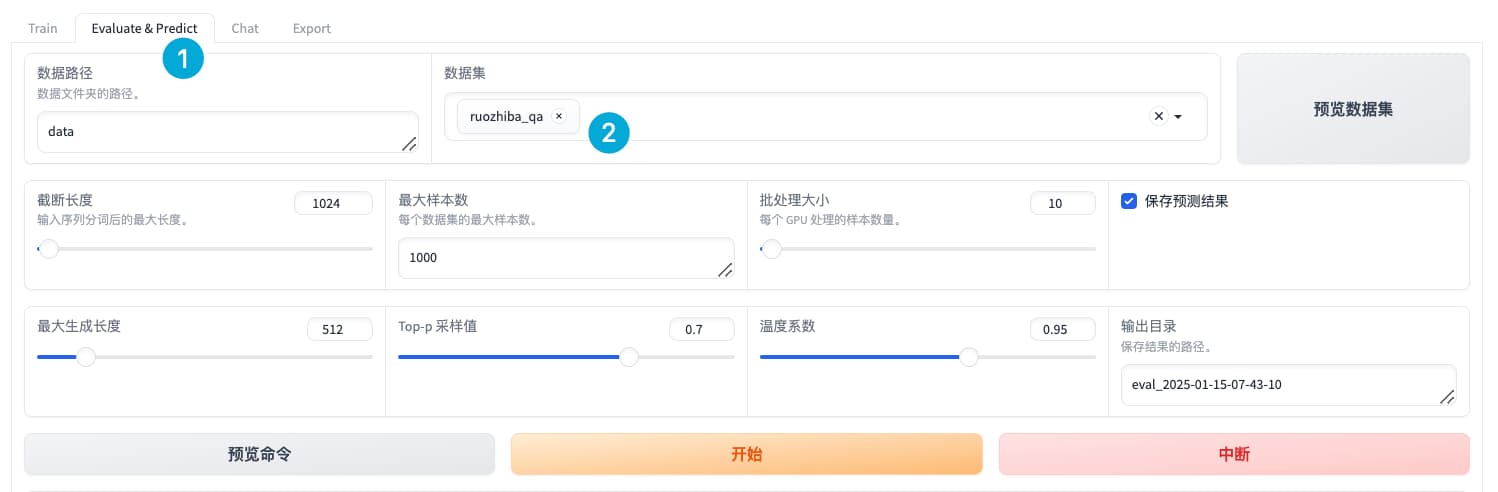
llamafactory-cli train \
--stage sft \
--model_name_or_path /workspace/model/Unichat-llama3.2-Chinese-1B \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--quantization_method bitsandbytes \
--template default \
--flash_attn auto \
--dataset_dir data \
--eval_dataset ruozhiba_qa \
--cutoff_len 1024 \
--max_samples 1000 \
--per_device_eval_batch_size 10 \
--predict_with_generate True \
--max_new_tokens 512 \
--top_p 0.7 \
--temperature 0.95 \
--output_dir saves/Llama-3.2-1B/lora/eval_2025-01-15-07-43-10 \
--trust_remote_code True \
--do_predict True \
--adapter_name_or_path saves/Llama-3.2-1B/lora/train_2025-01-14-09-17-41评估结果:
root@VM-0-10-ubuntu:/workspace/LLaMA-Factory/saves/Llama-3.2-1B/lora/eval_2025-01-15-07-43-10# tree .
.
├── all_results.json
├── generated_predictions.jsonl
├── llamaboard_config.yaml
├── predict_results.json
├── running_log.txt
├── trainer_log.jsonl
└── training_args.yaml{
"predict_bleu-4": 98.1589338,
"predict_model_preparation_time": 0.0032,
"predict_rouge-1": 98.6407997,
"predict_rouge-2": 98.1822169,
"predict_rouge-l": 98.49396239999999,
"predict_runtime": 319.2714,
"predict_samples_per_second": 3.132,
"predict_steps_per_second": 0.313
}合并
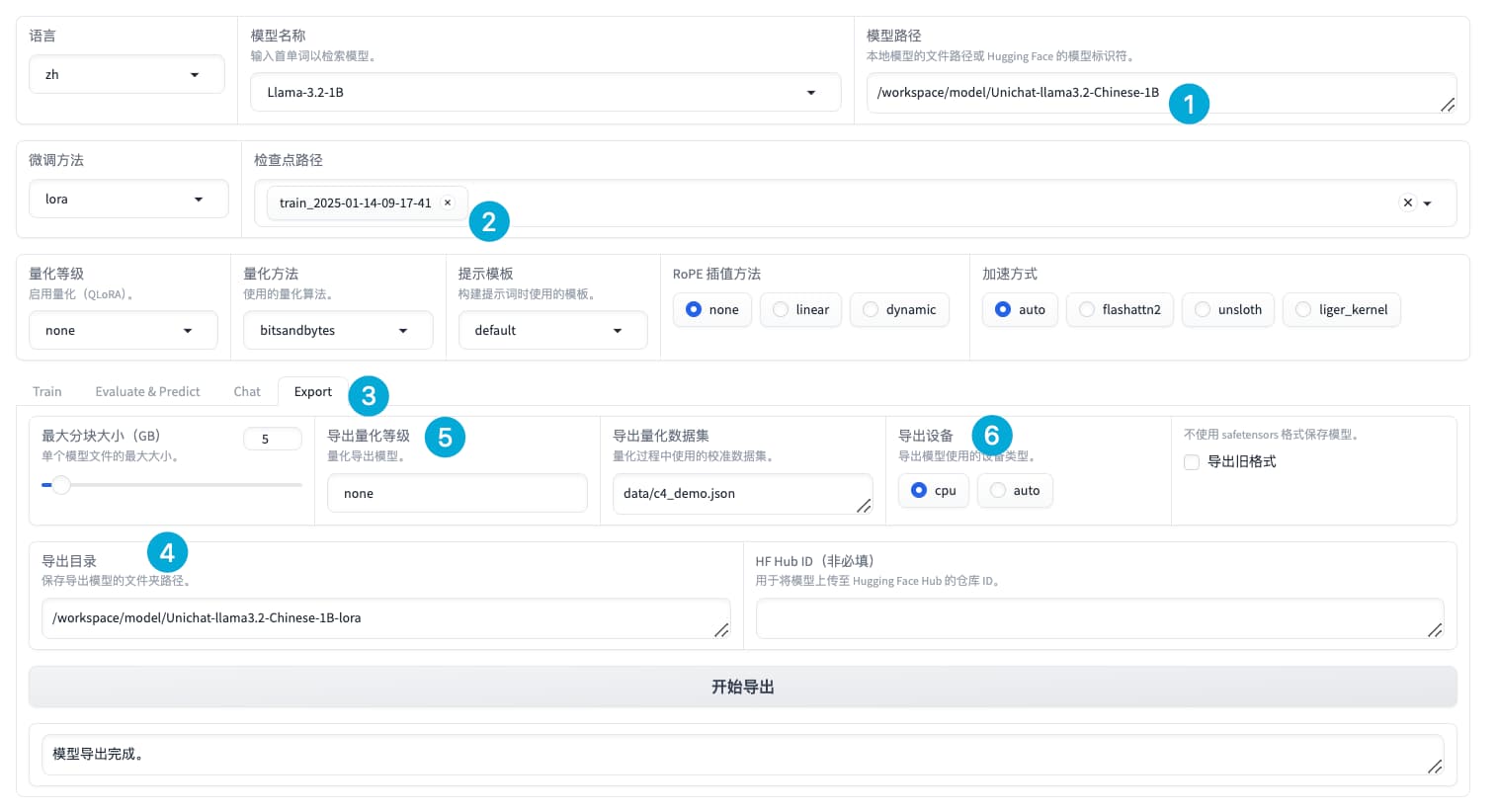
部署
转为gguf模型
root@VM-0-10-ubuntu:/workspace/llama.cpp# python convert_hf_to_gguf.py /workspace/model/Unichat-llama3.2-Chinese-1B-lora --outtype f16 --verbose --outfile /workspace/model/Unichat-llama3.2-Chinese-1B-lora-gguf.gguf
INFO:hf-to-gguf:Loading model: Unichat-llama3.2-Chinese-1B-lora
INFO:gguf.gguf_writer:gguf: This GGUF file is for Little Endian only
INFO:hf-to-gguf:Exporting model...
INFO:hf-to-gguf:Set model quantization version
INFO:gguf.gguf_writer:Writing the following files:
INFO:gguf.gguf_writer:/workspace/model/Unichat-llama3.2-Chinese-1B-lora-gguf.gguf: n_tensors = 147, total_size = 2.5G
Writing: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2.47G/2.47G [00:07<00:00, 350Mbyte/s]
INFO:hf-to-gguf:Model successfully exported to /workspace/model/Unichat-llama3.2-Chinese-1B-lora-gguf.gguf创建Ollama模型文件
创建ModelFile文件内容为:FROM /workspace/model/Unichat-llama3.2-Chinese-1B-lora-gguf.gguf
注册:ollama create Unichat-llama3.2-Chinese-1B-lora-gguf-merged -f Modelfile
启动:ollama run Unichat-llama3.2-Chinese-1B-lora-gguf-merged
transformer调用
from transformers import AutoModelForCausalLM,AutoTokenizer
device = "cpu"
model_dir = "/Volumes/Date/huggingface/model/llama/LLM-Research/Meta-Llama-3-8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_dir,torch_dtype='auto')
tokenizer=AutoTokenizer.from_pretrained(model_dir)
#加载与模型相匹配的分词器。分词器用于将文本转换成模型能够理解和处
prompt="你好,请介绍下你自己。"
messages=[{'role':'system','content':'You are a helpful assistant system'},
{'role': 'user','content': prompt}]
# 使用分词器的 apply_chat_template 方法将上面定义的消,息列表转护# tokenize=False 表示此时不进行令牌化,add_generation_promp
text =tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
#将处理后的文本令牌化并转换为模型输入张量,然后将这些张量移至之前
model_inputs=tokenizer([text],return_tensors="pt").to('cpu')
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
# 对输出进行解码
response=tokenizer.batch_decode(generated_ids, skip_special_tokens=True)



