大模型固有的局限性
LLM所具有的能力是建立在预训练的基础上,因此,LLM并不具备实时或训练时没有使用的知识:
实时数据:时间等
私有领域/业务知识
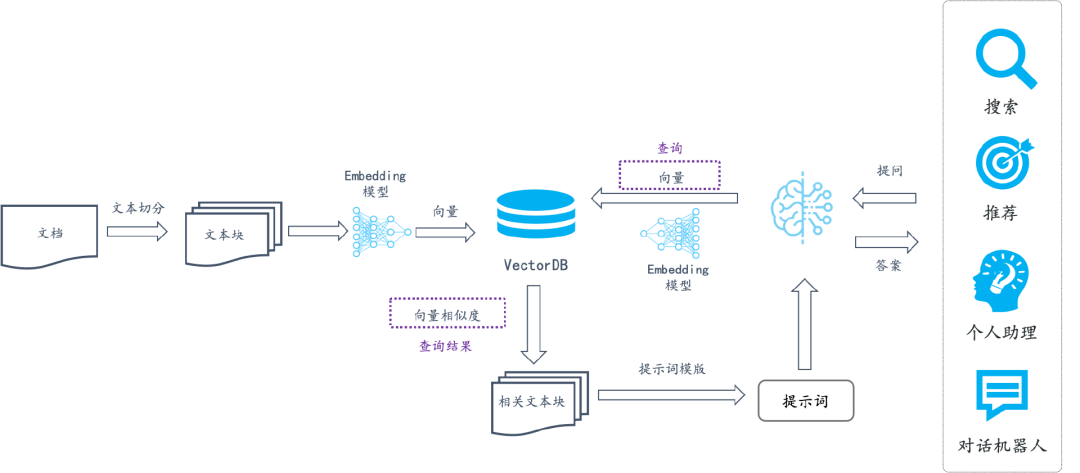
RAG
Retrieval Augmented Generation,通过检索的方式增强生成模型的能力。
基本流程
文档加载,并按照一定的条件切割成片段
将切片灌入检索引擎
封装检索接口
调用流程:Query -> 检索 -> Prompt -> LLM -> Answer
依赖
pip install --upgrade openai
# pdf 解析库
pip install pdfminer.six
pip install numpy
pip install chromadb向量检索
向量是一种有大小和方向的数学对象。它可以表示为从一个点到另一个点的有向线段。例如,二维空间中的向量可以表示为 (x,y),表示从原点 (0,0) 到点 (x,y)$的有向线段。可以用一组坐标 x_0, x_1, \ldots, x_{N-1}) 表示一个 N 维空间中的向量,N$叫向量的维度。
文本向量(Embedding)
将文本转成一组 N 维浮点数,即文本向量又叫 Embeddings
向量之间可以计算距离,距离远近对应语义相似度大小
向量间的相似度计算
import numpy as np
from numpy import dot
from numpy.linalg import norm
def cos_sim(a, b):
'''余弦距离 -- 越大越相似'''
return dot(a, b)/(norm(a)*norm(b))
def l2(a, b):
'''欧氏距离 -- 越小越相似'''
x = np.asarray(a)-np.asarray(b)
return norm(x)
def get_embeddings(texts, model="text-embedding-ada-002", dimensions=None):
'''封装 OpenAI 的 Embedding 模型接口'''
if model == "text-embedding-ada-002":
dimensions = None
if dimensions:
data = client.embeddings.create(
input=texts, model=model, dimensions=dimensions).data
else:
data = client.embeddings.create(input=texts, model=model).data
return [x.embedding for x in data]向量数据库&Chroma
将数据量庞大的知识、新闻、文献、语料等先通过嵌入(embedding)算法转变为向量数据,然后存储在Chroma等向量数据库中。当用户在大模型输入问题后,将问题本身也embedding,转化为向量,在向量数据库中查找与之最匹配的相关知识,组成大模型的上下文,将其输入给大模型,最终返回大模型处理后的文本给用户。
import chromadb
from chromadb.config import Settings
class MyVectorDBConnector:
def __init__(self, collection_name, embedding_fn):
# 内存模式
chroma_client = chromadb.Client(Settings(allow_reset=True))
# 数据持久化
# chroma_client = chromadb.PersistentClient(path="./chroma")
# 注意:为了演示,实际不需要每次 reset(),并且是不可逆的!
chroma_client.reset()
# 创建一个 collection
self.collection = chroma_client.get_or_create_collection(name=collection_name)
self.embedding_fn = embedding_fn
def add_documents(self, documents):
'''向 collection 中添加文档与向量'''
self.collection.add(
embeddings=self.embedding_fn(documents), # 每个文档的向量
documents=documents, # 文档的原文
ids=[f"id{i}" for i in range(len(documents))] # 每个文档的 id
)
def search(self, query, top_n):
'''检索向量数据库'''
results = self.collection.query(
query_embeddings=self.embedding_fn([query]),
n_results=top_n
)
return resultsFAISS: Meta 开源的向量检索引擎 https://github.com/facebookresearch/faiss
Pinecone: 商用向量数据库,只有云服务 https://www.pinecone.io/
Milvus: 开源向量数据库,同时有云服务 https://milvus.io/
Weaviate: 开源向量数据库,同时有云服务 https://weaviate.io/
Qdrant: 开源向量数据库,同时有云服务 https://qdrant.tech/
PGVector: Postgres 的开源向量检索引擎 https://github.com/pgvector/pgvector
RediSearch: Redis 的开源向量检索引擎 https://github.com/RediSearch/RediSearch
ElasticSearch 也支持向量检索 https://www.elastic.co/enterprise-search/vector-search
文本切割粒度
1. 粒度太大可能导致检索不精准,粒度太小可能导致信息不全面
2. 问题的答案可能跨越两个片段
from nltk.tokenize import sent_tokenize
import json
# chunk_size 一般根据文档内容或大小来设置
# overlap_size 一般设置 chunk_size 大小的10%-20%之间
def split_text(paragraphs, chunk_size=300, overlap_size=100):
'''按指定 chunk_size 和 overlap_size 交叠割文本'''
sentences = [s.strip() for p in paragraphs for s in sent_tokenize(p)]
chunks = []
i = 0
while i < len(sentences):
chunk = sentences[i]
overlap = ''
prev_len = 0
prev = i - 1
# 向前计算重叠部分
while prev >= 0 and len(sentences[prev])+len(overlap) <= overlap_size:
overlap = sentences[prev] + ' ' + overlap
prev -= 1
chunk = overlap+chunk
next = i + 1
# 向后计算当前chunk
while next < len(sentences) and len(sentences[next])+len(chunk) <= chunk_size:
chunk = chunk + ' ' + sentences[next]
next += 1
chunks.append(chunk)
i = next
return chunks检索后排序
最合适的答案不一定排在检索的最前面
1. 检索时过招回一部分文本
2. 通过一个排序模型对 query 和 document 重新打分排序
from sentence_transformers import CrossEncoder
model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2', max_length=512) # 英文,模型较小
# model = CrossEncoder('BAAI/bge-reranker-large', max_length=512) # 多语言,国产,模型较大
user_query = "how safe is llama 2"
# user_query = "llama 2安全性如何"
scores = model.predict([(user_query, doc) for doc in search_results['documents'][0]])
# 按得分排序
sorted_list = sorted(zip(scores, search_results['documents'][0]), key=lambda x: x[0], reverse=True)
for score, doc in sorted_list:
print(f"{score}\t{doc}\n")Rerank 的 API 服务
[Cohere Rerank](https://cohere.com/rerank):支持多语言
[Jina Rerank](https://jina.ai/reranker/):目前只支持英文
混合检索
传统的关键字检索(稀疏表示)与向量检索(稠密表示)各有优劣。 举个具体例子,比如文档中包含很长的专有名词,关键字检索往往更精准而向量检索容易引入概念混淆。
1. 基于关键字检索的排序
import time
class MyEsConnector:
def __init__(self, es_client, index_name, keyword_fn):
self.es_client = es_client
self.index_name = index_name
self.keyword_fn = keyword_fn
def add_documents(self, documents):
'''文档灌库'''
if self.es_client.indices.exists(index=self.index_name):
self.es_client.indices.delete(index=self.index_name)
self.es_client.indices.create(index=self.index_name)
actions = [
{
"_index": self.index_name,
"_source": {
"keywords": self.keyword_fn(doc),
"text": doc,
"id": f"doc_{i}"
}
}
for i, doc in enumerate(documents)
]
helpers.bulk(self.es_client, actions)
time.sleep(1)
def search(self, query_string, top_n=3):
'''检索'''
search_query = {
"match": {
"keywords": self.keyword_fn(query_string)
}
}
res = self.es_client.search(
index=self.index_name, query=search_query, size=top_n)
return {
hit["_source"]["id"]: {
"text": hit["_source"]["text"],
"rank": i,
}
for i, hit in enumerate(res["hits"]["hits"])
}from chinese_utils import to_keywords # 使用中文的关键字提取函数
# 引入配置文件
ELASTICSEARCH_BASE_URL = os.getenv('ELASTICSEARCH_BASE_URL')
ELASTICSEARCH_PASSWORD = os.getenv('ELASTICSEARCH_PASSWORD')
ELASTICSEARCH_NAME= os.getenv('ELASTICSEARCH_NAME')
es = Elasticsearch(
hosts=[ELASTICSEARCH_BASE_URL],
http_auth=(ELASTICSEARCH_NAME, ELASTICSEARCH_PASSWORD), # 用户名,密码
)
# 创建 ES 连接器
es_connector = MyEsConnector(es, "demo_es_rrf", to_keywords)
# 文档灌库
es_connector.add_documents(documents)
# 关键字检索
keyword_search_results = es_connector.search(query, 3)
print(json.dumps(keyword_search_results, indent=4, ensure_ascii=False))2. 基于向量检索的排序
# 创建向量数据库连接器
vecdb_connector = MyVectorDBConnector("demo_vec_rrf", get_embeddings)
# 文档灌库
vecdb_connector.add_documents(documents)
# 向量检索
vector_search_results = {
"doc_"+str(documents.index(doc)): {
"text": doc,
"rank": i
}
for i, doc in enumerate(
vecdb_connector.search(query, 3)["documents"][0]
)
} # 把结果转成跟上面关键字检索结果一样的格式
print(json.dumps(vector_search_results, indent=4, ensure_ascii=False))3. 基于 RRF 的融合排序
参考资料:https://learn.microsoft.com/zh-cn/azure/search/hybrid-search-ranking
def rrf(ranks, k=1):
ret = {}
# 遍历每次的排序结果
for rank in ranks:
# 遍历排序中每个元素
for id, val in rank.items():
if id not in ret:
ret[id] = {"score": 0, "text": val["text"]}
# 计算 RRF 得分
ret[id]["score"] += 1.0/(k+val["rank"])
# 按 RRF 得分排序,并返回
return dict(sorted(ret.items(), key=lambda item: item[1]["score"], reverse=True))
import json
# 融合两次检索的排序结果
reranked = rrf([keyword_search_results, vector_search_results])
print(json.dumps(reranked, indent=4, ensure_ascii=False))基于向量检索的RAG
文档加载于切割
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
def extract_text_from_pdf(filename, page_numbers=None, min_line_length=1):
'''从 PDF 文件中(按指定页码)提取文字'''
paragraphs = []
buffer = ''
full_text = ''
# 提取全部文本
for i, page_layout in enumerate(extract_pages(filename)):
# 如果指定了页码范围,跳过范围外的页
if page_numbers is not None and i not in page_numbers:
continue
for element in page_layout:
if isinstance(element, LTTextContainer):
full_text += element.get_text() + '\n'
# 按空行分隔,将文本重新组织成段落
lines = full_text.split('\n')
for text in lines:
if len(text) >= min_line_length:
buffer += (' '+text) if not text.endswith('-') else text.strip('-')
elif buffer:
paragraphs.append(buffer)
buffer = ''
if buffer:
paragraphs.append(buffer)
return paragraphsLLM接口封装
from openai import OpenAI
import os
# 加载环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv(), verbose=True) # 读取本地 .env 文件,里面定义了 OPENAI_API_KEY
client = OpenAI()
def get_completion(prompt, model="gpt-4o"):
'''封装 openai 接口'''
messages = [{"role": "user", "content": prompt}]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 模型输出的随机性,0 表示随机性最小
)
return response.choices[0].message.contentPrompt模版
def build_prompt(prompt_template, **kwargs):
'''将 Prompt 模板赋值'''
inputs = {}
for k, v in kwargs.items():
if isinstance(v, list) and all(isinstance(elem, str) for elem in v):
val = '\n\n'.join(v)
else:
val = v
inputs[k] = val
return prompt_template.format(**inputs)
prompt_template = """
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
已知信息:
{context} # 检索出来的原始文档
用户问:
{query} # 用户的提问
如果已知信息不包含用户问题的答案,或者已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
请不要输出已知信息中不包含的信息或答案。
请用中文回答用户问题。
"""检索
class RAG_Bot:
def __init__(self, vector_db, llm_api, n_results=2):
self.vector_db = vector_db
self.llm_api = llm_api
self.n_results = n_results
def chat(self, user_query):
# 1. 检索
search_results = self.vector_db.search(user_query, self.n_results)
# 2. 构建 Prompt
prompt = build_prompt(
prompt_template, context=search_results['documents'][0], query=user_query)
# 3. 调用 LLM
response = self.llm_api(prompt)
return response# 创建一个RAG机器人
bot = RAG_Bot(
vector_db,
llm_api=get_completion
)
user_query = "llama 2有多少参数?"
response = bot.chat(user_query)
print(response)