本文旨在通过最基础的数学内容,剔除机器学习中复杂的术语,从零描述LLM的工作原理。
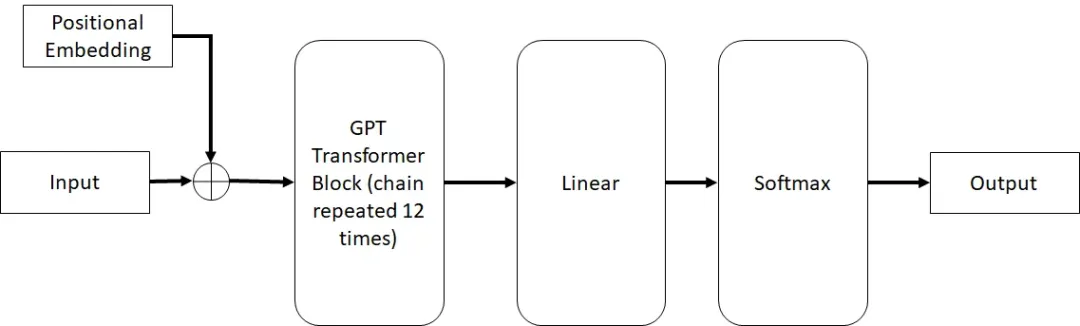
一个简单的神经网络
神经网络仅能接受数字输入,并输出其他数字。所以首先需要考虑的关在在于:
如何将输入转为数字
解读数字输出已实现目标
如何设计能够根据期望输出的神经网络
分析已知数据
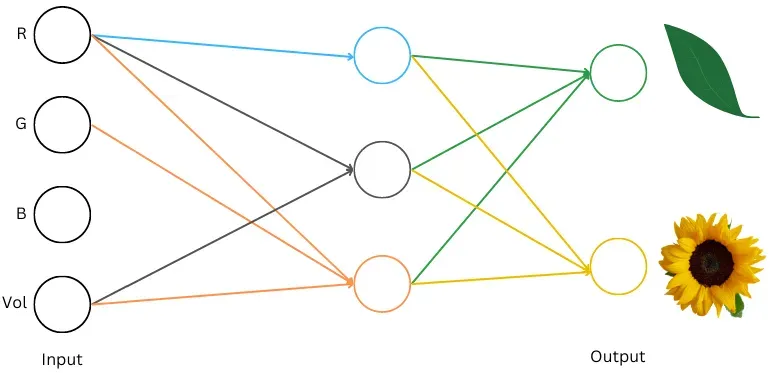
物体属性:色调(RGB)、体积
分类目标:叶子 花朵
构建神经网络(neural net)
定义输入/输出解释方式:第一个数值表示“叶子”的可能性,第二个数值表示“花朵”的可能性,较大的数值对应的类别为预测结果
设计神经网络:
输入层:包含 4 个神经元,对应 RGB 和体积数据。
中间层:包含 3 个神经元。
输出层:包含 2 个神经元,对应“叶子”和“花朵”。
术语解释:
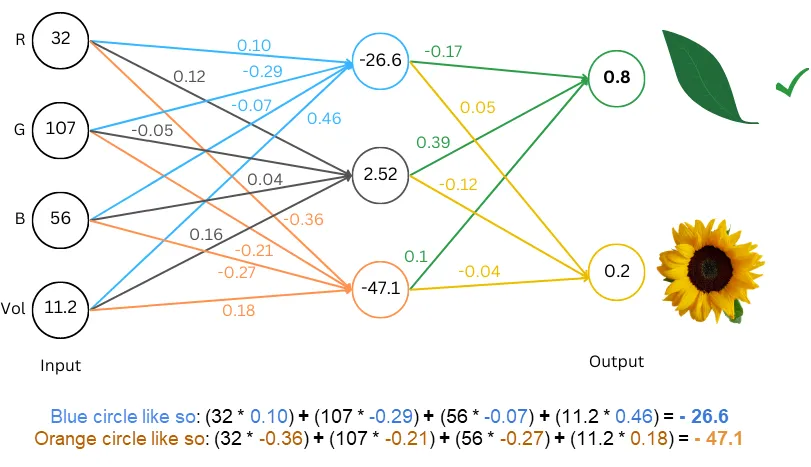
神经元/节点(Neurons/Nodes): 圈内的数值。
权重(Weights): 连接线上标注的数值。
层(Layers): 神经元的集合,例如输入层包含 4 个神经元。
计算这个网络的预测/输出(称为“前向传递”),将圆圈中的数字与对应神经元配对的权重相乘,然后将它们加起来。R:32->-26.6:(32 * 0.10) + (107 * -0.29) + (56 * -0.07) + (11.2 * 0.46) = -26.6运行整个网络时,我们看到输出层的第一个数字较大,因此我们将其解释为“网络将这些(RGB,Vol)值分类为叶子”。
模型的任务是接收恰好4个数字并输出恰好2个数字。模型本身并不知道什么是叶子或花,也不知道RGB和体积。
4 个输入数字是(RGB,Vol)是我们对输入数字的解释,同时也决定了输出数字并推断,如果第一个数字较大,则它为叶子。选择合适的权重,使得模型能处理输入数字,并给出正确的 2 个数字,以便得到想要的解释。同样,对4个输入数字以及2个输出数字可以有不同的解释,如4个输入解释为湿度、云量等,将这两个输出解释为“一个小时后会晴天”或“一个小时后会下雨”。只要调整好权重,你可以让这个相同的网络同时完成两项任务(分类叶子/花),并预测一小时后的天气!神经网络给出的只是两个数字,是否将它们解释为分类、预测或其他内容完全取决于你。
神经网络其他概念
激活层
对每个圆圈中的数字应用一个非线性函数(RELU 是一个常见的函数,它的做法是,如果数字为负数,就将它设为 0,若为正数,则保持不变)。所以在上面的例子中,我们会将中间层的两个数字(-26.6 和 -47.1)替换为 0,然后再继续向下一层传递。当然,重新训练权重后,网络才会再次有用。没有激活层时,所有的加法和乘法都可以简化为一个单一的层。在我们的例子中,你可以将绿色圆圈表示为 RGB 的加权和,使用某些权重,你就不再需要中间层了。它可能会是类似这样的公式:(0.10 -0.17 + 0.12 0.39 - 0.36 0.1) R + (-0.29 -0.17 - 0.05 0.39 - 0.21 0.1) G ……等等。如果这里存在非线性操作,这通常是不可行的。非线性操作帮助网络处理更复杂的情况。
偏差Bias
网络通常还会包含一个与每个节点相关的额外数字,这个数字就是“偏差”。它被简单地加到乘积中,以计算节点的值。所以如果上面蓝色节点的偏差为 0.25,那么该节点的值将是:(32 0.10)+(107 -0.29)+(56 -0.07)+(11.2 0.46)+ 0.25 = -26.35。通常,模型中所有这些数字被称为“参数”,这些数字并不是神经元/节点本身的值。
Softmax
通常不会直接解释输出层的数字,这些数字将会转化为概率(即使所有数字都是正数,并且总和为 1)。如果输出层中的所有数字已经是正数,可以通过将每个数字除以输出层所有数字的和来实现这一点。然而,“softmax” 函数通常用于处理正负数字的情况。
如何训练这些模型
在这个例子中,已经定义了权重,允许将输入到模型的数据计算出良好的输出结果。但是这些权重是怎么确认的呢?设置这些权重(参数)的过程叫做模型训练 ,这个过程需要一些训练参数来训练这个神经网络。这个训练数据中包含输入值,以及已经知道每个输入对应的是叶子还是花,每组(R,G,B,Vol)数字对应的叶子/花标签,就是带标签的数据。
训练过程
初始化随机数: 每个参数/权重设置为一个随机数。
输入数据:
假设输入的数据对应的是叶子(R=32, G=107, B=56, Vol=11.2)。
假设希望输出层对应叶子的数字更大,我们希望叶子的数字是 0.8,花的数字是 0.2。
计算损失:
想要的输出层数字,和从随机初始化的权重得到的输出数字,计算期望的数字和实际得到的数字之间的差异,然后将这些差异加起来。例如(0.8 - 0.6)= 0.2 和 (0.2 - 0.4)= -0.2,最终的总差异为 0.4
这个差异为“损失” 。理想情况下,希望损失接近于零“最小化损失”。
调整参数:
一旦得到了损失,可以稍微调整每个参数,看看增加或减少它是否能减小损失。这就是该参数的“梯度”。
朝着减少损失的方向,略微调整每个参数(即朝梯度的反方向调整)。
一旦所有参数都稍微调整过,损失应该会变小。
重复过程:
不断重复上述过程
最终得到一组“训练过的”权重/参数-
“梯度下降”。
注意事项
为了某个样本减少损失时,可能会导致另一个样本的损失变大。
减少整个训练数据集的平均损失:将损失定义为所有样本损失的平均值,然后对平均损失计算梯度。
这样的迭代称为一个“轮次”(epoch):不断重复这个过程,从而找到能够减少平均损失的权重。
直接通过公式推导出来梯度:
不需要“调整权重”来计算梯度
例如,如果最后一步权重是 0.17,并且该神经元的值为正数,我们希望输出更大,那么我们可以看到将权重增加到 0.18 会有所帮助
“梯度消失”和“梯度爆炸”:梯度很容易在训练过程中失控,可能会变为零或无穷大
梯度消失:变为零
梯度爆炸:无穷大
模型时如何生成语言的
拓展输出层神经网络,假设是26个字母。输出层的每个神经元对应一个字符,大约26个神经元。用这些字符替换网络中的输入“Humpty Dumpt”,并要求它输出一个字符,并将其解释为“网络对我们刚输入的序列的下一个字符建议”。如果可以把权重训练的足够好,以便它输出 “y”,从而完成 “Humpty Dumpty”。
但是,神经网络的工作就是接收数字,根据训练好的参数做一些数学运算,然后输出数字。而具体赋予该模型功能作用的关键在在于解释和训练参数。例如上面讲两个数字解释为“叶子/花”或“一小时后晴天或下雨”,同样也可以解释为“下一个字符”。
因此,一个简单的解决方案就是为每个字符分配一个数字。假设a=1、b=2......
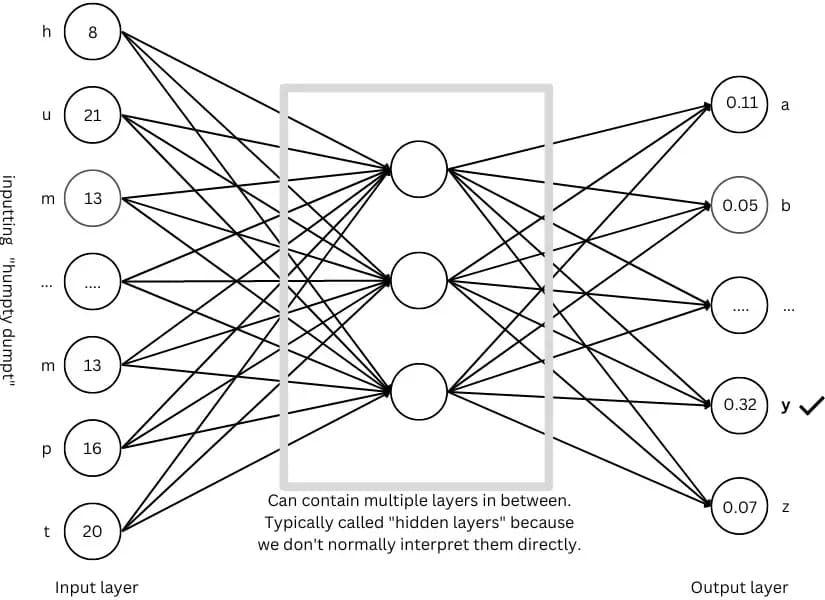
通过给神经网络输入一串字符来预测下一个字符,当预测出“y”后,就可以将‘y’追加到现有的字符列表中,然后再次输入到神经网络中,要求它预测出下一个字符。以此类推,如果神经网络训练的足够好,假设它将会输出“Humpty Dumpty sat on a wall”。这样就实现了生成式 AI(Generative AI)。
实际上不能将“Humpty Dumpty”输入到网络中,因为输入层只有12层个神经元,每个字符对应一个神经元。当追加'y'为最后一个字符时,输入就需要13个神经元。但此时调整整个网络显然是不可行的,解决方法是将‘H’移出,改为输入最近的12个字符。
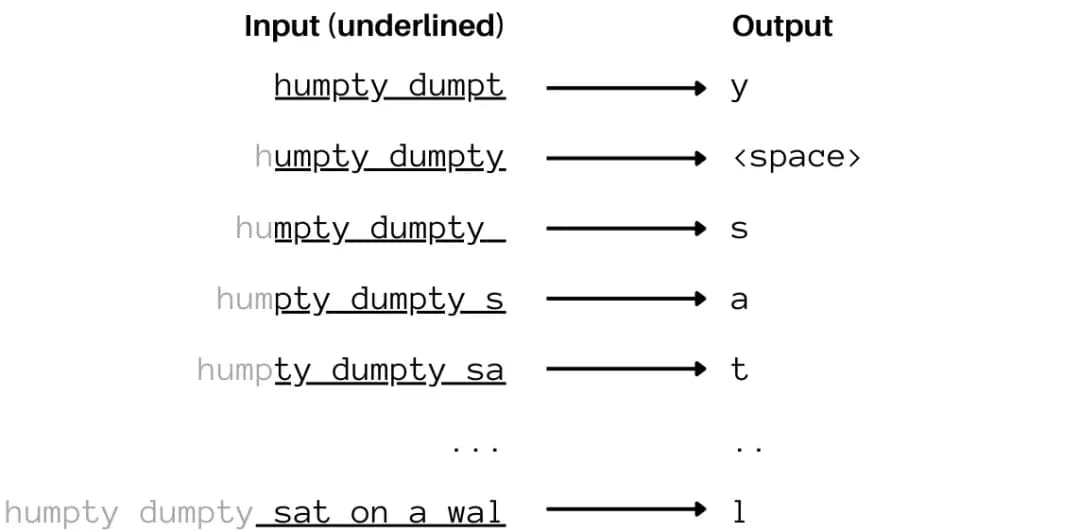
能够输入到网络中的信息长度是固定的(由输入层的大小决定),这个长度叫做“上下文长度”(即为网络提供的上下文),用来做未来的预测,现代的网络可以拥有非常大的上下文长度(几个千词)。
为什么LLM表现如此优异
嵌入(Embeddings)
通过调整权重,看哪种方式能最终得到更小的损失。然后,不断地、递归地调整权重。在这个过程中,输入是固定的。在每一次迭代中:
输入数据。
计算输出层的结果。
将输出与我们理想中的输出进行比较,并计算平均损失。
调整权重并重新开始。
当输入是(RGB,Vol)时,这样做是合理的。
当输入的字符如 a、b、c 等是随意选择的。现在每次迭代时,不仅调整权重,还调整输入的数字,使用不同的数字来表示 “a” 等字符减少损失并使模型变得更好。这种对输入的数字表示应用梯度下降,不仅仅是对权重,这个过程叫做“嵌入”(embedding)。
嵌入是将输入映射到数字的过程,它需要经过训练。
训练嵌入的过程与训练参数的过程非常相似。
嵌入的一个大优点是,可以将它应用到其他模型中。
拓展字符表示方式
为每个字符分配一组数字,以捕捉更丰富的信息,这种有序的数字集合称为“向量”。向量的长度就是它包含的数字的数量。所有的嵌入向量必须具有相同的长度,否则就无法将所有字符组合输入到网络中。
例如,“humpty dumpt” 和下一次的 “umpty dumpty”。在这两种情况下,都需要将 12 个字符输入到网络中,如果每个字符的向量长度不是 10,那么我们就无法可靠地将这些字符输入到长度为 120 的输入层中:
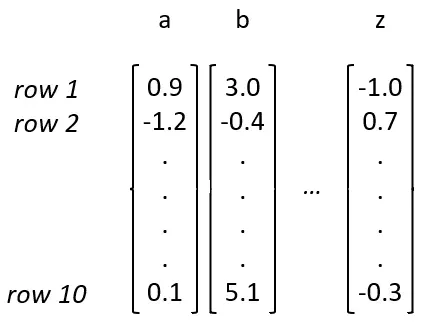
嵌入矩阵:一个对应字母的列号,然后查看矩阵中的那一列,就能得到用来表示该字母的向量。
子词分词器
在为单词分配嵌入,并让网络预测下一个单词中。网络本质上只理解数字,所以可以为 “humpty”、 “dumpty”、 “sat”、 “on” 等单词分别分配一个10长度的向量,然后输入两个单词,网络就可以给出下一个单词。
将单词拆分为子词进行嵌入
由于每个单词视为独立的单元,并且一开始为每个单词分配的是随机的嵌入向量,那么非常相似的单词(例如“cat”和“cats”)最开始是没有任何关系的。但是期望这两个单词的嵌入应该彼此接近。如今语言模型中最常用的嵌入方案之一就是将单词拆分为子词进行嵌入。以 “cat” 为例,将 “cats” 拆分为两个 Token:“cat” 和 “s”。
分词器是一种将输入文本(例如 “Humpty Dumpt”)拆分为多个 Token,并给出相应数字的工具,这些数字将用于在嵌入矩阵中查找对应的嵌入向量。矩阵中列的排列是完全无关紧要的,可以将任意列分配,只要每次输入时查找的向量相同。分词器实际上给的是一个任意(但固定的)数字,目的是便于查找。它们的主要任务是将句子拆分为 Token。
使用嵌入和子词分词后,模型可能会长成如下所示:

自注意力(Self-Attention)
预测的下一个单词依赖于前面所有的单词,它们之间的依赖关系可能会有所不同,有些单词的影响可能比其他单词更大。
例如,如果我们试图预测这句话中的下一个单词:“Damian had a secret child, a girl, and he had written in his will that all his belongings, along with the magical orb, will belong to ____”。此处的空格可能填入 “her”或 “him”,而这个选择具体取决于句子中一个较早的单词:girl 或 boy。
通过前馈层连接到模型中特定位置的权重是固定的(对于每个位置都是一样的)。如果重要的单词总是在相同的位置,模型就能适当地学习到这些权重,可以正常工作。然而,下一次预测所依赖的相关单词,可能出现在任何位置。因此,权重不仅取决于位置,还必须根据位置的内容来决定。
自注意力的实现
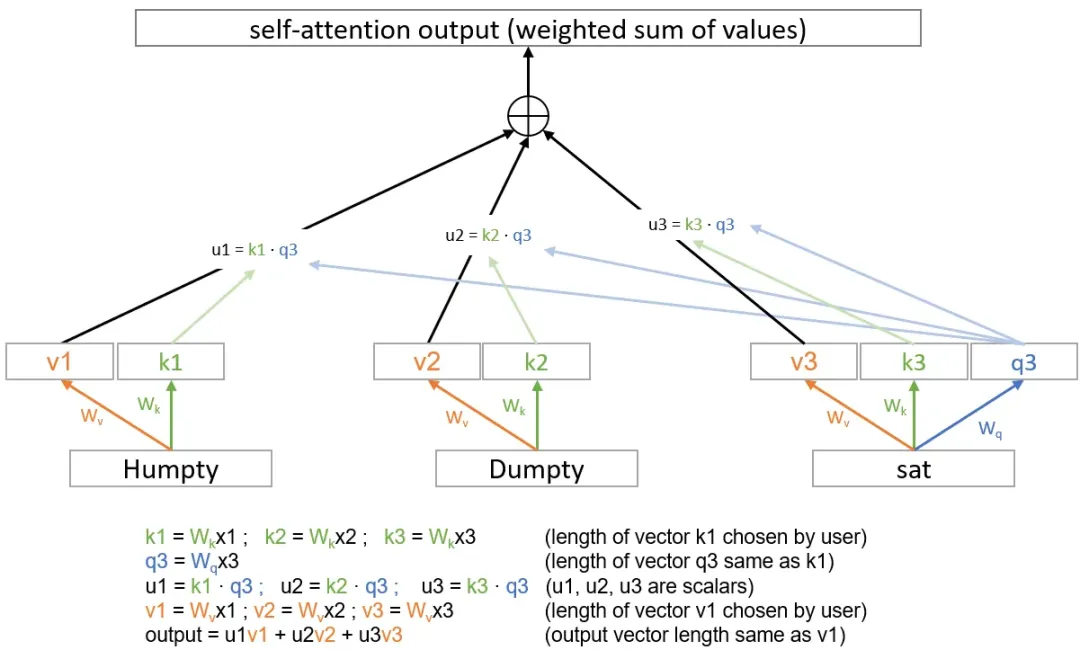
自注意力所做的事情类似于将每个单词的嵌入向量应用一些权重后加起来。因此,如果 “humpty”、 “dumpty”、 “sat” 的嵌入向量分别为 x1、x2、x3,那么它会为每个向量乘以一个权重(一个数字),然后再将它们加起来。假设最终的输出为:output=0.5⋅x1+0.25⋅x2+0.25⋅x3 这里的输出就是自注意力的结果。如果我们将权重表示为 u1, u2, u3 ,那么我们可以写出:output=u1⋅x1+u2⋅x2+u3⋅x3 。
权重的依赖关系
某些向量比其他向量更重要,重要性取决于即将预测的单词。因此,希望权重取决于即将预测的单词。但是在预测之前并不知道下一个单词是什么。自注意力使用的是紧接着我们要预测的单词之前的那个单词,即句子中的最后一个已知单词。
如何计算权重
权重的计算公式为:u1=F(x1,x3) ,其中 x1 是我们将加权的单词,而 x3 是我们已知的最后一个单词(假设只有3个单词)。
为 x1 和 x3 分别构建两个向量( k1 和 q3 ),然后简单地计算它们的点积。就能得到一个依赖于 x1 和 x3 的数字。
为每个单词构建一个小的单层神经网络,将嵌入向量 x1 映射到 k1 ,将 x3 映射到 q3 ,以此类推。
使用矩阵表示法,实际上得到权重矩阵 Wk 和 Wq ,使得:k1=Wk⋅x1andq3=Wq⋅x3。
通过计算 k1 和 q3 的点积来得到标量值:u1=F(x1,x3)=Wk⋅x1⋅Wq⋅x3
添加值向量
自注意力中的另一个重要步骤是,并不是直接对嵌入向量进行加权求和,而是对这些嵌入向量的某种“值”进行加权求和,而这个“值”是通过另一个小的单层神经网络得到的。与 k1 和 q1 类似,也为每个单词生成一个值向量 v1 ,它是通过矩阵 Wv 得到的:v1=Wv⋅x1 ,然后,对这些值进行加权求和。最终,整个自注意力过程如下所示(假设我们只有 3 个单词,正在预测第四个单词):
标量 u1, u2, u3 等不一定会加起来等于1。如果需要它们作为权重, softmax 函数让它们相加等于1。
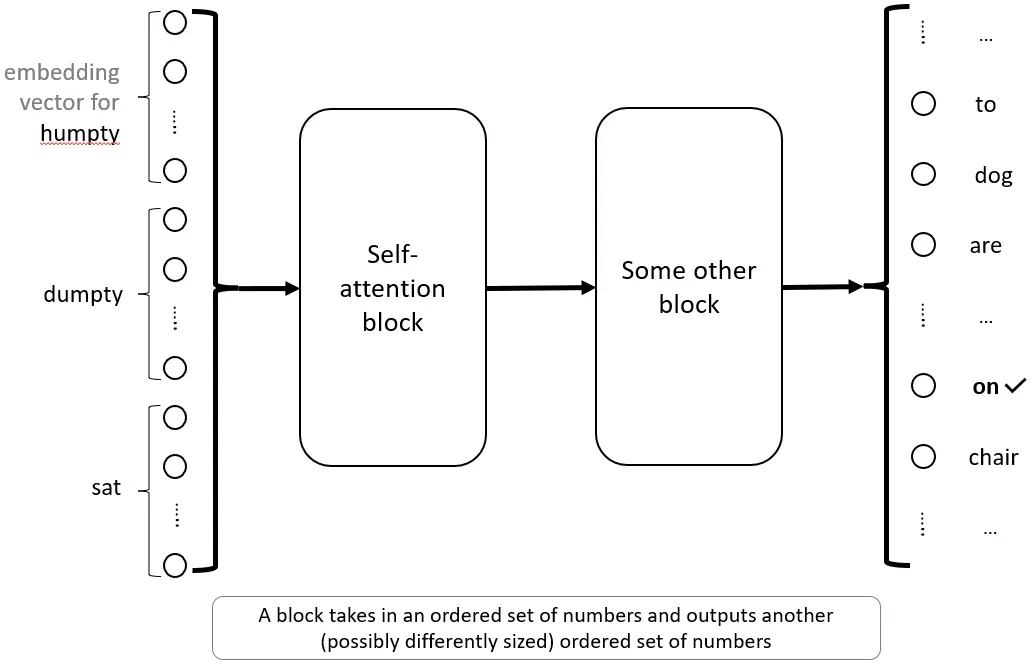
整个过程现在可以封装起来,称之为“自注意力块”(Self-Attention Block)。这个自注意力块接收嵌入向量并输出一个用户选择长度的单一输出向量。这个模块有三个参数:Wk , Wq , 和 Wv
Softmax
logistic 函数(如下图所示),它将所有数字映射到 (0, 1) 区间,并且保持输出顺序。
softmax 函数的作用: logistic 函数的一个推广,但它有更多的功能。如果给它 10 个任意的数字,它会将这些数字转换成 10 个输出,每个输出都在 0 到 1 之间,最重要的是,这 10 个值的和为 1,这样就可以将它们解释为概率。
在几乎每个语言模型的最后一层,都会有 softmax 函数。
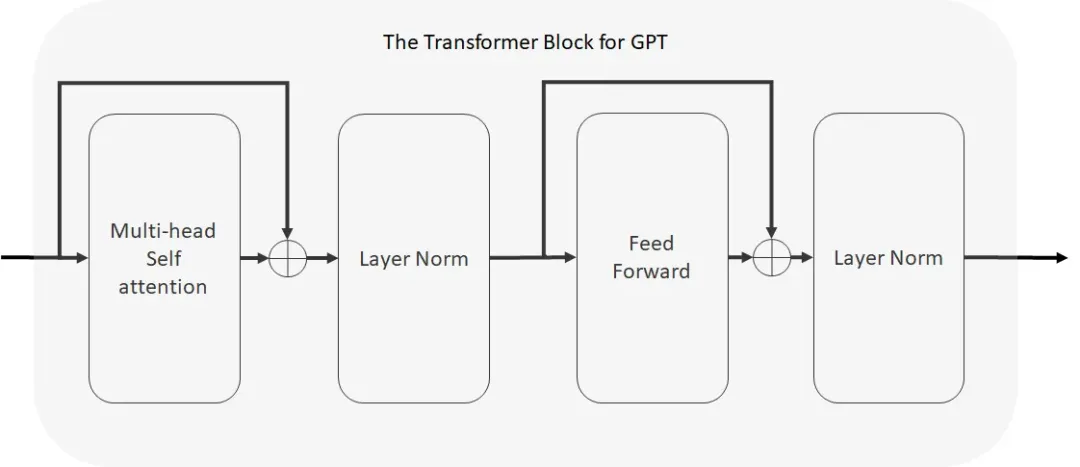
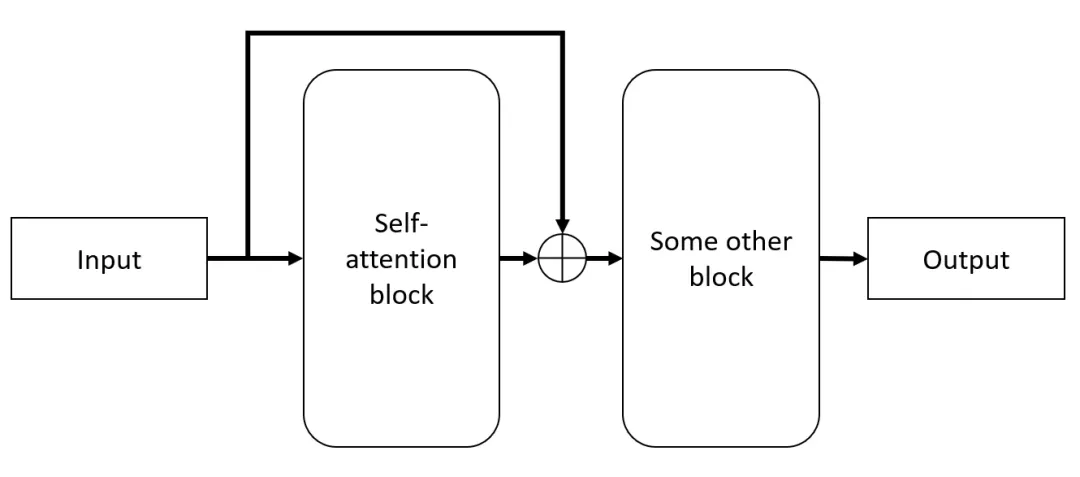
残差连接
层归一化(Layer Normalization)
接收输入的数据信号,并通过减去均值并除以标准差来对其进行归一化。它的作用是稳定了输入向量,有助于深度网络的训练。
举个例子,如果将层归一化应用于输入层,它会对输入层的所有神经元进行操作,计算出两个统计量:它们的均值和标准差。假设均值为 M,标准差为 D,那么层归一化所做的就是将每个神经元的值替换为 (x - M) / D ,其中 x 表示任何一个神经元的原始值。
通过归一化输入,可能会去除一些有用的信息,这些信息可能对学习目标非常重要。为此层归一化层引入了一个比例和一个偏差参数。对于每个神经元,将它乘以一个标量,然后加上一个偏差(标量和偏差的值是可以训练的参数)。这使得网络可以学习到对预测可能有价值的某些变动。而且,由于这些是唯一的参数,LayerNorm 层的训练参数非常少。整个过程大致如下所示:
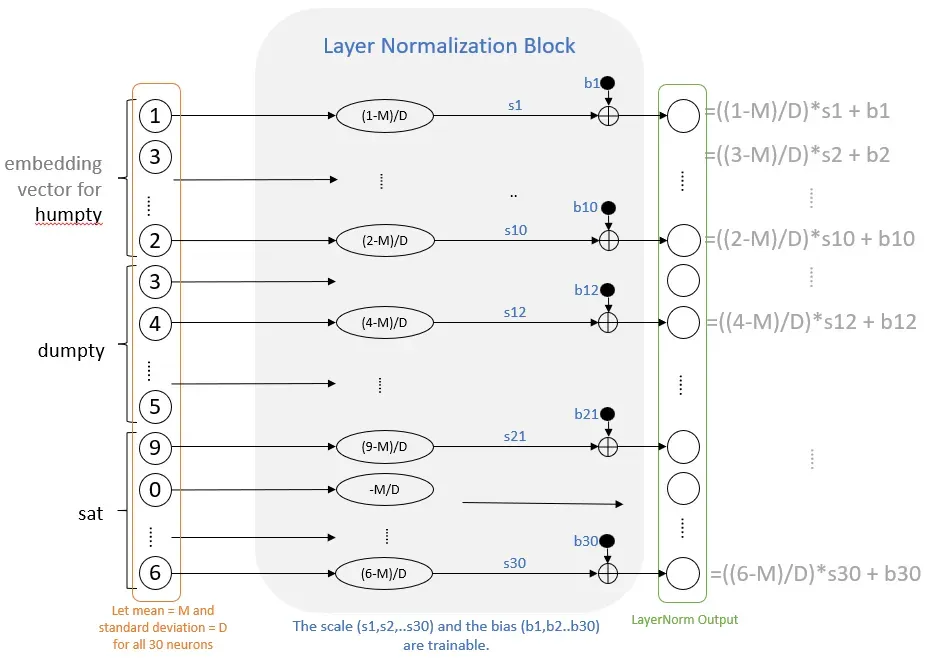
缩放和偏差是可训练的参数:层归一化是一种相对简单的操作,其中每个数字仅仅是逐点操作(在初始均值和标准差计算之后)。
标准差是一个统计量,表示数据的分散程度。例如,如果所有的数值都相同,那么标准差就是零。如果一般情况下每个数值都远离这些数值的均值,那么标准差就会很高。
Dropout(丢弃法)
Dropout 是一种简单但有效的方法,用来避免模型的过拟合。过拟合是指模型在训练数据集上表现得很好,但对模型未见过的样本的泛化能力差。
如果训练一个模型,它可能会在数据上出错,或者以某种方式对数据过拟合。如果训练另一个模型,它可能会做出同样的错误,但方式不同。那么,如果训练多个这样的模型并对它们的输出取平均通常被称为“集成模型”,因为它们通过组合多个模型的输出进行预测,集成模型通常比单个模型表现得更好。Dropout 是一种技术,它并不像集成模型那样构建多个模型,但它能够捕捉到集成模型的一些本质。
通过在训练过程中插入一个 dropout 层,实际上是在随机删除一些层之间的神经元连接(删除的比例是 dropout 率)。例,如果在输入层和中间层之间插入一个 dropout 层,并设定 50% 的 dropout 率,它看起来会是这样:
现在,这种方法迫使网络在训练时具有大量冗余。实际上,你是在同时训练多个不同的模型——但它们共享相同的权重。
推理过程:可以使用 dropout 进行多次预测,然后将它们的结果结合起来。然而,由于这种方法计算开销较大——并且我们的模型共享相同的权重——为什么不直接使用所有的权重进行预测(也就是一次性使用所有权重,而不是每次使用 50% 的权重)呢?这应该能为我们提供一个类似集成模型的近似效果。
使用 50% 权重训练的模型和使用所有权重的模型在中间神经元的数值上会有很大的不同。
Dropout 在推理时的做法:将使用整个网络的所有权重,并简单地将这些权重乘以 (1 - p) ,其中 p 是丢弃概率。
多头注意力(Multi-head Attention)
并行运行多个注意力头(它们接受相同的输入)。然后将所有的输出结果拼接起来。它的结构大致如下所示:
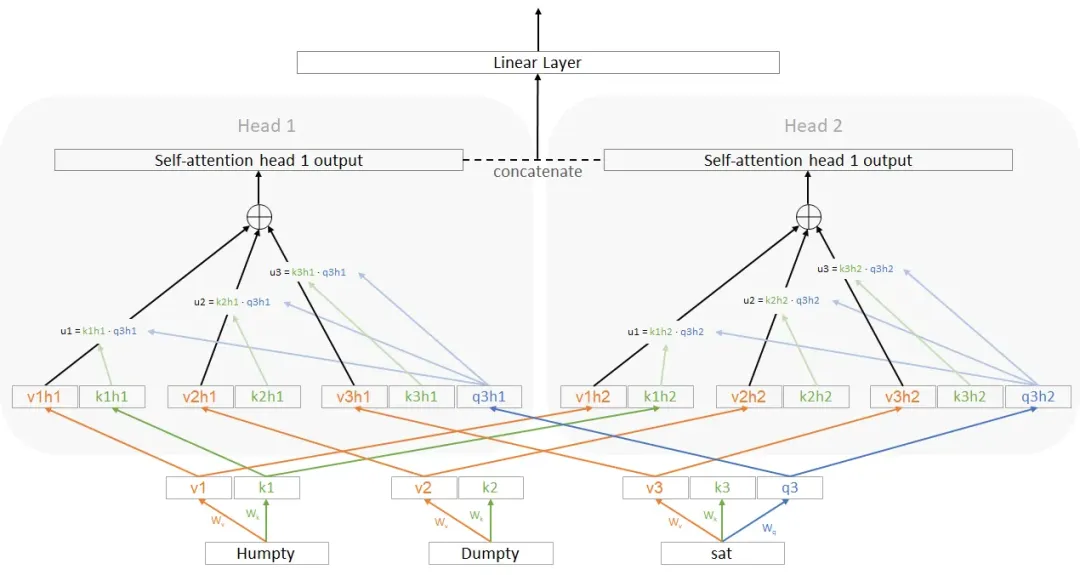
从 v1 到 v1h1 的箭头表示线性层——每个箭头上都有一个矩阵进行变换
在这里发生的事情是,我们为每个注意力头生成相同的 key、query 和 value。但是我们在使用这些 k、q、v值之前,基本上会对它们应用一个线性变换(分别对每个 k、q、v 进行变换,并且对每个头也分别进行变换)。这个额外的层在 自注意力机制 中并不存在。
位置编码与嵌入(Positional Encoding and Embedding)
虽然注意力机制可以识别出需要关注的部分,但这并不依赖于单词的位置。然而,英语中单词的位置是很重要的,给模型提供一些单词位置的感知可能会改善模型的表现。因此,当使用注意力机制时,并不会直接将嵌入向量输入到自注意力块中。而是在将嵌入向量输入到注意力块之前,加入“位置编码”(Positional Encoding)。
位置嵌入 与其他嵌入没有太大区别,唯一的区别是它不是嵌入词汇,而是嵌入数字 1、2、3 等。因此,这个嵌入是一个与词嵌入矩阵长度相同的矩阵,每一列对应一个数字。
GPT 架构