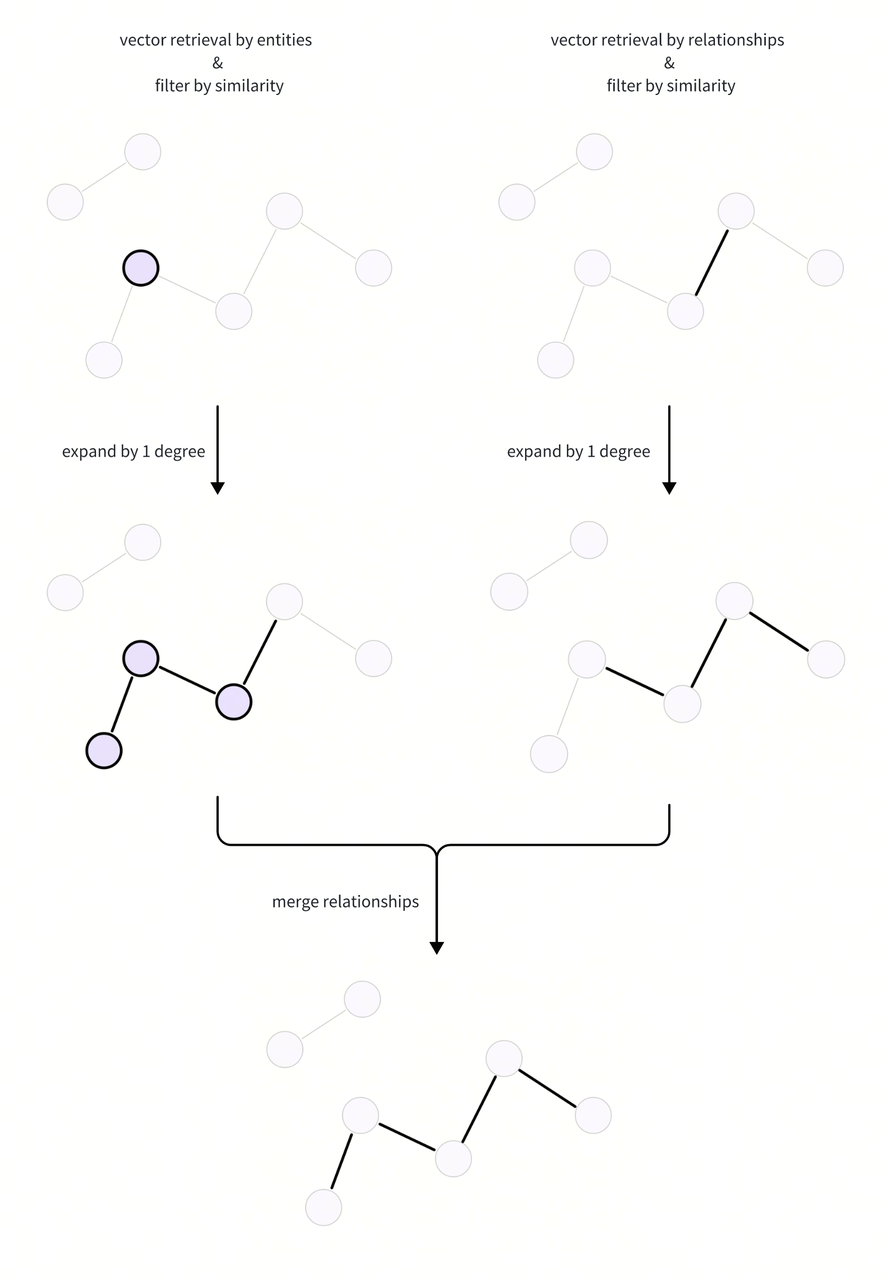
介绍
Hugging Face 是一个提供自然语言处理(NLP)工具的平台,支持 Transformer 模型的开发和应用。拥有庞大的模型库和社区资源,能够满足从研究到工业应用的各种需求。https://huggingface.co
安装
基础环境:conda、CUDA、CUDDA、pytorch
镜像环境:transformers、datasets、tokenizers pip install transformers datasets tokenizers
清华源:pip install -i https://mirrors.aliyun.com/pypi/simple xxxxx
API使用
匿名访问API
import requests
API_URL = "https://api-inference.huggingface.co/models/bert-base-chinese"
# 不使用 Authorization 头以进行匿名访问
response = requests.post(API_URL, json={"inputs": "你好,Hugging Face!"})
print(response.json())Inference API
获取 API Token 后,使用 API Token 进行访问:
from transformers import pipeline
# 替换为你的实际 API Token
API_TOKEN = "your_api_token_here"
# 使用 API Token
generator = pipeline("text-generation", model="gpt2", use_auth_token=API_TOKEN)
output = generator("The future of AI is", max_length=50)
print(output)下载模型
下载方法
官方案例:https://huggingface.co/docs/transformers/installation#offline-mode
# AutoModelForCausalLM huggingface模型下载工具
# AutoTokenizer 向量、分词工具
from transformers import AutoModelForCausalLM, AutoTokenizer
# 要下载的模型
model_name = "uer/gpt2-chinese-cluecorpussmall"
# 指定模型保存路径
cache_dir = "/Volumes/Date/huggingface/model"
# 下载并加载模型和分词器到指定文件夹
AutoModelForCausalLM.from_pretrained(model_name, cache_dir=cache_dir)
AutoTokenizer.from_pretrained(model_name, cache_dir=cache_dir)
模型文件分析
└── models--uer--gpt2-chinese-cluecorpussmall
├── .no_exist
│ └── c2c0249d8a2731f269414cc3b22dff021f8e07a3
│ ├── added_tokens.json
│ ├── chat_template.jinja
│ ├── generation_config.json
│ ├── model.safetensors
│ ├── model.safetensors.index.json
│ └── tokenizer.json
├── blobs
│ ├── 5478b950f53650c82f7f7e91010787c870813a76adeabe23c8571b01af1379b4
│ ├── 7427f68f74a68f64941103a0270d66482bbdb615
│ ├── a4a5c7f3c4c4c3c8576193b6c631e5a882debfc1
│ ├── ca4f9781030019ab9b253c6dcb8c7878b6dc87a5
│ └── e7b0375001f109a6b8873d756ad4f7bbb15fbaa5
├── refs
│ └── main
└── snapshots
├── .DS_Store
└── c2c0249d8a2731f269414cc3b22dff021f8e07a3 # 软连接到blobs中的文件
├── config.json 模型配置文件
├── pytorch_model.bin 模型本体
├── special_tokens_map.json 特殊字符集
├── tokenizer_config.json 分词器配置文件
└── vocab.txt 字符编码,模型能够识别的所有字符,行号为编码config.json
{
"activation_function": "gelu_new",
"architectures": [ #类型
"GPT2LMHeadModel"
],
"attn_pdrop": 0.1,
"embd_pdrop": 0.1,
"gradient_checkpointing": false,
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"model_type": "gpt2", # 模型类型
"n_ctx": 1024,
"n_embd": 768,
"n_head": 12,
"n_inner": null,
"n_layer": 12,
"n_positions": 1024,
"output_past": true,
"resid_pdrop": 0.1,
"task_specific_params": {
"text-generation": {
"do_sample": true,
"max_length": 320
}
},
"tokenizer_class": "BertTokenizer", # 当前模型使用的分词器
"vocab_size": 21128 # 字符集大小,及vocab.txt中模型可以识别的字符数量
}
vocab.txt
[unused98]
[UNK]
[MASK]
<S>
!
风
##风单个字符在这个集合中存在两种形式,例如上面的 风 和 ##风 ,本质上这两个字是一样的,单个编码表示没有上下文关系,加了##表示包含上下文关系。
模型对于输入的处理过程是,首先,将输入的字符更具vocab.txt 中的内容转换为编码,再对编码进行处理
special_tokens_map.json
{"unk_token": "[UNK]", "sep_token": "[SEP]", "pad_token": "[PAD]", "cls_token": "[CLS]", "mask_token": "[MASK]"}tokenizer_config.json
{
"do_lower_case": false,
"unk_token": "[UNK]",
"sep_token": "[SEP]",
"pad_token": "[PAD]",
"cls_token": "[CLS]",
"mask_token": "[MASK]",
"tokenize_chinese_chars": true, # 是否包含中文字符
"strip_accents": null,
"model_max_length": 1024。 # 模型最大输出字符数量
}model库
文本生成
在线访问
import requests
#使用Token访问在线模型
API_URL = "https://api-inference.huggingface.co/models/uer/gpt2-chinese-cluecorpussmall"
API_TOKEN = "hf_UxzVDqZAZasShKePbXSxxxxxxxxx"
headers = {"Authorization": f"Bearer {API_TOKEN}"}
response = requests.post(API_URL,headers=headers,json={"inputs":"你好,Hugging face"})
print(response.json())离线访问
# AutoModelForCausalLM huggingface模型下载工具
# AutoTokenizer 向量、分词工具
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers import pipeline
model_name = "uer/gpt2-chinese-cluecorpussmall"
cache_dir = "/Volumes/Date/huggingface/model/usr/gpt2-chinese-cluecorpussmall"
model = AutoModelForCausalLM.from_pretrained(cache_dir, local_files_only=True)
tokenizer = AutoTokenizer.from_pretrained( cache_dir, local_files_only=True)
generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
# 生成文本
output = generator("你好,我是一款语言模型,", max_length=50, num_return_sequences=1)
print(output)
# AutoModelForCausalLM huggingface模型下载工具
# AutoTokenizer 向量、分词工具
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers import pipeline
cache_dir = "/Volumes/Date/huggingface/model/usr/gpt2-chinese-cluecorpussmall"
model = AutoModelForCausalLM.from_pretrained(cache_dir, local_files_only=True)
tokenizer = AutoTokenizer.from_pretrained( cache_dir, local_files_only=True)
# 使用加载的模型和分词器创建生成文本的 pipeline
generator = pipeline("text-generation", model=model, tokenizer=tokenizer,device="cpu")
# 生成文本
# output = generator("你好,我是一款语言模型,", max_length=50, num_return_sequences=1)
# output = generator("你好,我是一款语言模型,", max_length=50, num_return_sequences=1, truncation=True, clean_up_tokenization_spaces=False)
output = generator(
"你好,我是一款语言模型,",#生成文本的输入种子文本(prompt)。模型会根据这个初始文本,生成后续的文本
max_length=50,#指定生成文本的最大长度。这里的 50 表示生成的文本最多包含 50 个标记(tokens)
num_return_sequences=2,#参数指定返回多少个独立生成的文本序列。值为 1 表示只生成并返回一段文本。
truncation=True,#该参数决定是否截断输入文本以适应模型的最大输入长度。如果 True,超出模型最大输入长度的部分将被截断;如果 False,模型可能无法处理过长的输入,可能会报错。
temperature=0.7,#该参数控制生成文本的随机性。值越低,生成的文本越保守(倾向于选择概率较高的词);值越高,生成的文本越多样(倾向于选择更多不同的词)。0.7 是一个较为常见的设置,既保留了部分随机性,又不至于太混乱。
top_k=50,#该参数限制模型在每一步生成时仅从概率最高的 k 个词中选择下一个词。这里 top_k=50 表示模型在生成每个词时只考虑概率最高的前 50 个候选词,从而减少生成不太可能的词的概率。
top_p=0.9,#该参数(又称为核采样)进一步限制模型生成时的词汇选择范围。它会选择一组累积概率达到 p 的词汇,模型只会从这个概率集合中采样。top_p=0.9 意味着模型会在可能性最强的 90% 的词中选择下一个词,进一步增加生成的质量。
clean_up_tokenization_spaces=True#该参数控制生成的文本中是否清理分词时引入的空格。如果设置为 True,生成的文本会清除多余的空格;如果为 False,则保留原样。默认值即将改变为 False,因为它能更好地保留原始文本的格式。
)
print(output)
# [{'generated_text': '你好,我是一款语言模型, 来 自 高 校 的 实 习 生 。 我 想 学 习 语 言 模 型 , 从 零 开 始 学 习 , 在 这 里 , 我 要 感 谢 我 的 老'}, {'generated_text': '你好,我是一款语言模型, 于 2016 年 4 月 在 ios 和 安 卓 平 台 上 推 出 。 该 模 型 主 要 适 用 于 一 个 人 群 , 每 个 人 的 生 活 方'}]
datasets库
加载数据集
在线加载数据集NousResearch/hermes-function-calling-v1,一个中文的情感分类数据集
from datasets import load_dataset
#在线加载数据
dataset = load_dataset(path="NousResearch/hermes-function-calling-v1",split="train")
# 缓存到本地
dataset.save_to_disk(dataset_path="/Volumes/Date/huggingface/dataset/ChnSentiCorp")
print(dataset)离线加载数据集
from datasets import load_from_disk
#加载本地磁盘数据,指向包含dataset_dict.json文件目录
dataset = load_from_disk("/Volumes/Date/huggingface/dataset/ChnSentiCorp")
print(dataset)
#取出测试集
test_data = dataset["test"]
print(test_data)
#查看数据
for data in test_data:
print(data)DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 9600
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 1200
})
test: Dataset({
features: ['text', 'label'],
num_rows: 1200
})
})
Dataset({
features: ['text', 'label'],
num_rows: 1200
})
{'text': '这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般', 'label': 1}
{'text': '怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片!开始还怀疑是不是赠送的个别现象,可是后来发现每张DVD后面都有!真不知道生产商怎么想的,我想看的是猫和老鼠,不是米老鼠!如果厂家是想赠送的话,那就全套米老鼠和唐老鸭都赠送,只在每张DVD后面添加一集算什么??简直是画蛇添足!!', 'label': 0}
{'text': '还稍微重了点,可能是硬盘大的原故,还要再轻半斤就好了。其他要进一步验证。贴的几种膜气泡较多,用不了多久就要更换了,屏幕膜稍好点,但比没有要强多了。建议配赠几张膜让用用户自己贴。', 'label': 0}
{'text': '交通方便;环境很好;服务态度很好 房间较小', 'label': 1}
{'text': '不错,作者的观点很颠覆目前中国父母的教育方式,其实古人们对于教育已经有了很系统的体系了,可是现在的父母以及祖父母们更多的娇惯纵容孩子,放眼看去自私的孩子是大多数,父母觉得自己的孩子在外面只要不吃亏就是好事,完全把古人几千年总结的教育古训抛在的九霄云外。所以推荐准妈妈们可以在等待宝宝降临的时候,好好学习一下,怎么把孩子教育成一个有爱心、有责任心、宽容、大度的人。', 'label': 1}
{'text': '有了第一本书的铺垫,读第二本的时候开始进入状态。基本上第二本就围绕主角们的能力训练展开,故事的主要发生场地设置在美洲的亚马逊丛林。心里一直疑惑这和西藏有什么关系,不过大概看完全书才能知道内里的线索。其中描述了很多热带雨林中特有的神秘动植物以及一些生存技巧和常识,受益匪浅。能够想像出要写这样一部书,融合这样许多的知识,作者需要花费多少心血来搜集和整理并成文。', 'label': 1}
{'text': '前台接待太差,酒店有A B楼之分,本人check-in后,前台未告诉B楼在何处,并且B楼无明显指示;房间太小,根本不像4星级设施,下次不会再选择入住此店啦。', 'label': 0}
{'text': '1. 白色的,很漂亮,做工还可以; 2. 网上的软件资源非常丰富,这是我买它的最主要原因; 3. 电池不错,昨天从下午两点到晚上十点还有25分钟的剩余时间(关闭摄像头,无线和蓝牙)主要拷贝东西,看起来正常使用八小时左右没问题; 4. 散热不错,CPU核心不过40~55度,很多小本要上到80度了; 5. 变压器很小巧,很多小本的电源都用的是大本的电源,本倒是很轻,可旅行重量还是比较重。', 'label': 1}
{'text': '在当当上买了很多书,都懒于评论。但这套书真的很好,3册都非常精彩。我家小一的女儿,认字多,非常喜爱,每天睡前必读。她还告诉我,学校的语文课本中也有相同的文章。我还借给我的同事的女儿,我同事一直头疼她女儿不爱看书,但这套书,她女儿非常喜欢。两周就看完了。建议买。很少写评论,但忍不住为这套书写下。也给别的读者参考下。', 'label': 1}
{'text': '19天硬盘就罢工了~~~算上运来的一周都没用上15天~~~可就是不能换了~~~唉~~~~你说这算什么事呀~~~', 'label': 0}
{'text': '书一到,即被朋友借走,我是早已看过了的,买它,是因为张爱玲。看过张子静的《我的姊姊张爱玲》,可以看出,张对自己的弟弟也是不甚热情,这是她的性格。但是有一次张子静去找她,那天张爱玲却是很开心的样子。后来张子静推算,彼时张爱玲正与胡兰成相恋。很多人不耻于胡兰成的用情不专,我当然也很反感,但我也想说,胡兰成是给过张爱的欢喜的。张是怎样聪明的女子,若不是爱,她也不会那么痴。属于他们的爱情,让他们自己品尝与承担。胡的文字,确实是不错的,有一种儒雅在里面。不知道是不是那份淡淡的气氛,曾经让张心动——“岁月静好,现世安稳”。', 'label': 0}
{'text': '书的印刷看起来也不好,画面也不漂亮,内容的连惯性也不好,所以让人看起来一点也不能吸引孩子的兴趣和眼球,只是实在不想睡觉看一下,起催眠作用.作为家长来说,我也不爱讲这几本书.', 'label': 0}
......{
"builder_name": "chn_senti_corp",
"citation": "",
"config_name": "default",
"dataset_size": 3871919,
"description": "",
"download_checksums": {
"https://drive.google.com/u/0/uc?id=1uV-aDQoMI51A27OxVgJnzxqZFQqkDydZ&export=download": {
"num_bytes": 3032906,
"checksum": "5394d3b2867ece9452a275fc84924ae030d827bb57b90c6aed6009ffdd1b8cee"
},
"https://drive.google.com/u/0/uc?id=1kI_LUYm9m0pVGDb4LHqtjwauUrIGo_rC&export=download": {
"num_bytes": 375862,
"checksum": "a8770badf76a638fb21f92d5be9280eb8c50a7644dbe2dd881aff040c6fe6513"
},
"https://drive.google.com/u/0/uc?id=1YJkSqGFeo-8ifmgVbxGMTte7Y-yxPHg7&export=download": {
"num_bytes": 371381,
"checksum": "5ffc04692e4f7bf6b18eb9f94cef3090bd5fb55bb3e138ac7080f0739529ef1f"
}
},
"download_size": 3780149,
"features": {
"text": {
"dtype": "string",
"id": null,
"_type": "Value"
},
"label": { # 标签
"num_classes": 2,
"names": [
"negative", # 分类,积极:消极
"positive"
],
"id": null,
"_type": "ClassLabel"
}
},
"homepage": "",
"license": "",
"post_processed": null,
"post_processing_size": null,
"size_in_bytes": 7652068,
"splits": {
"train": { # 训练集
"name": "train",
"num_bytes": 3106365,
"num_examples": 9600,
"dataset_name": "chn_senti_corp"
},
"validation": { # 校验集
"name": "validation",
"num_bytes": 385021,
"num_examples": 1200,
"dataset_name": "chn_senti_corp"
},
"test": { # 测试集
"name": "test",
"num_bytes": 380533,
"num_examples": 1200,
"dataset_name": "chn_senti_corp"
}
},
"supervised_keys": null,
"task_templates": null,
"version": {
"version_str": "0.0.0",
"description": null,
"major": 0,
"minor": 0,
"patch": 0
}
}分词工具与文字编码工具
模型接收的是输入文本在字典中所对应的索引,因此,再将文本输入模型之前需要通过分词器将文本转换为编码。
加载字典和分词工具
AutoTokenizer自动加载分词工具
from transformers import AutoTokenizer
# 加载BERT模型的分词器
tokenizer = AutoTokenizer.from_pretrained("bert_base_chinese")批量编码句子
sentences = ["我爱自然语言",["Hugging Face 真强大"]]
encoded_inputs = tokenizer(sentences, padding=True,truncation=True,return_tensors="pt")
print(encoded_inputs)
"""
BertTokenizer(name_or_path='/Volumes/Date/huggingface/model/bert-base-chinese/models--bert-base-chinese/snapshots/c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f', vocab_size=21128, model_max_length=512, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True, added_tokens_decoder={
0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
101: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
102: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
103: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
)
"""vocab_size 识别字符
model_max_length 支持的最大字符长度
special_tokens 特殊字符,不包含在vocab中的字符,全部识别为特殊字符
added_tokens_decoder 索引字符
分词过程:编码器对文本进行编码,编码依赖于vocab.txt事先存住的编码字符集。
from transformers import AutoTokenizer, BertTokenizer
from transformers.models.marian.convert_marian_to_pytorch import add_special_tokens_to_vocab
token = BertTokenizer.from_pretrained(
"/Volumes/Date/huggingface/model/bert-base-chinese/models--bert-base-chinese/snapshots/c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f")
sents = ["白日依山尽",
"怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片!开始还怀疑是不是赠送的个别现象,可是后来发现每张DVD后面都有!真不知道生产商怎么想的,我想看的是猫和老鼠,不是米老鼠!如果厂家是想赠送的话,那就全套米老鼠和唐老鸭都赠送,只在每张DVD后面添加一集算什么??简直是画蛇添足!!"]
# 批量编码句子
out = token._batch_encode_plus(
batch_text_or_text_pairs=[sents[0], sents[1]],
add_special_tokens=True,
max_length=50,
# 语句不够长就填充0
padding="max_length",
return_tensors=None,
return_attention_mask=True,
return_token_type_ids=True,
return_special_tokens_mask=True,
# 返回编码之后length的长度
return_length=True,
)
for k, v in out.items():
print(k, ":", v)
"""
input_ids : [[101, 4635, 3189, 898, 2255, 2226, 102], [101, 2577, 4708, 1282, 1146, 4080, 1220, 4638, 2552, 2658, 3123, 3216, 8024, 1377, 3221, 4692, 4708, 4692, 4708, 1355, 4385, 8024, 1762, 3123, 3216, 2130, 3684, 1400, 8024, 1139, 4385, 671, 7415, 5101, 5439, 7962, 4638, 1220, 4514, 4275, 8013, 2458, 1993, 6820, 2577, 4542, 3221, 679, 3221, 6615, 6843, 4638, 702, 1166, 4385, 6496, 8024, 1377, 3221, 1400, 3341, 1355, 4385, 3680, 2476, 100, 1400, 7481, 6963, 3300, 8013, 4696, 679, 4761, 6887, 4495, 772, 1555, 2582, 720, 2682, 4638, 8024, 2769, 2682, 4692, 4638, 3221, 4344, 1469, 5439, 7962, 8024, 679, 3221, 5101, 5439, 7962, 8013, 1963, 3362, 1322, 2157, 3221, 2682, 6615, 6843, 4638, 6413, 8024, 6929, 2218, 1059, 1947, 5101, 5439, 7962, 1469, 1538, 5439, 7890, 6963, 6615, 6843, 8024, 1372, 1762, 3680, 2476, 100, 1400, 7481, 3924, 1217, 671, 7415, 5050, 784, 720, 8043, 8043, 5042, 4684, 3221, 4514, 6026, 3924, 6639, 8013, 8013, 102]]
token_type_ids : [[0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
special_tokens_mask : [[1, 0, 0, 0, 0, 0, 1], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]]
length : [7, 151]
attention_mask : [[1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
"""input_ids: 字符位置编码,给模型输入的数据。101:[CLS]开始标识、102:[SEP]结束标识、[PAD]补足编码(要转向量,两个向量的距离计算需要长度相同)
token_type_ids:第一个句子和特殊符号的位置是0,第二个句子位置是1
special_tokens_mask:特殊符号的位置是1,其他位置是0
# 解码文本数据
print(token.decode(out["input_ids"][0]))
print(token.decode(out["input_ids"][1]))
"""
[CLS] 白 日 依 山 尽 [SEP] [PAD]
[CLS] 怀 着 十 分 激 动 的 心 情 放 映 , 可 是 看 着 看 着 发 现 , 在 放 映 完 毕 后 , 出 现 一 集 米 老 鼠 的 动 画 片 ! 开 始 还 怀 疑 是 不 是 赠 送 的 个 别 现 象 , 可 是 后 来 发 现 每 张 [UNK] 后 面 都 有 ! 真 不 知 道 生 产 商 怎 么 想 的 , 我 想 看 的 是 猫 和 老 鼠 , 不 是 米 老 鼠 ! 如 果 厂 家 是 想 赠 送 的 话 , 那 就 全 套 米 老 鼠 和 唐 老 鸭 都 赠 送 , 只 在 每 张 [UNK] 后 面 添 加 一 集 算 什 么 ? ? 简 直 是 画 蛇 添 足 ! ! [SEP]
"""其他
访问问题
在线接口、模型下载、数据集下载都需要代理才能正常请求接口
镜像网站下载https://hf-mirror.com,添加环境变量
手动下载模型,本地加载https://huggingface.co/docs/transformers/installation#offline-mode