精准定位需求、匹配思维模式、发挥框架所长 ## 一、Agent 设计的 “百家争鸣”:从思维模式到框架分化 在 LLM 驱动的 Agent 世界中,不存在 “放之四海而准” 的通用设计模式。Chain of Thought 的线性推理、ReAct 的 “知行合一”、Plan and Execute 的分层规划等认知框架,共同构成了 Agent 解决问题的 “思维模式库”。这些模式的落地差异,直接导致开发框架的路径分化 ——LangChain 聚焦链式推理的流程编排,LlamaIndex 深耕知识检索与整合,Dify 则主打人机协作的混合编排。业务场景的复杂性(如实时数据查询、多步逻辑推理、创意生成)决定了 Agent 必须 “量体裁衣”,而框架的多样性本质上是设计模式哲学的外在映射。 ## 二、认知框架解析:从单步推理到立体探索 ### (一)线性推理范式:抽丝剥茧的思维显化 #### 1. Chain of Thought(思维链):一步一释的逻辑展开 [tabs] [tab name="核心机制" active="true"] 让模型在回答前,把推理过程一步步写出来。不是一口气给出答案,而是把整个推理过程展示出来。 [/tab] [tab name="适用场景"] 问小王比小李大1岁,小张的年龄是小李的两倍。如果三个人的年龄加起来是41岁,问小王多大?思维链方式:假设小李的年龄是 ×,那么小王=×+3,小张=2X,总和=(x1)+×+(2X)=4×+ 1,4x+1=41,4X=38,×=10,所以小王=10+3=13。结果小王13岁。这种方式在逻辑推理、数值计算、逐步分析类问题里,会显得更稳健。[/tab] [tab name="提出背景"] Google Research 在2022年发表的论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》 [/tab] [tab name="框架映射"] LangChain 的 “SequentialChain” 通过链式调用多个工具,实现思维链的工程化落地。 [/tab] [tab name="代码示例"] ``` from langchain_openai import ChatOpenAI from langchain.chains import LLMChain from langchain.prompts import PromptTemplate from langchain.chains import SimpleSequentialChain # 初始化LLM llm = ChatOpenAI(model="gpt-4-turbo", temperature=0) # 第一步:拆解问题(显式推理步骤) step1_prompt = PromptTemplate( input_variables=["question"], template="""请拆解解决以下数学问题的步骤,无需计算最终结果: 问题:{question} 推理步骤:""" ) step1_chain = LLMChain(llm=llm, prompt=step1_prompt, output_key="steps") # 第二步:执行计算(基于步骤推导结果) step2_prompt = PromptTemplate( input_variables=["steps"], template="""根据以下推理步骤,计算最终结果: 推理步骤:{steps} 最终答案(仅输出数字):""" ) step2_chain = LLMChain(llm=llm, prompt=step2_prompt, output_key="result") # 串联链条 cot_chain = SimpleSequentialChain( chains=[step1_chain, step2_chain], verbose=True ) # 运行示例 result = cot_chain.run("计算(18+7)×(25-13)") print("最终结果:", result) ``` **输出效果**: ``` > Entering new SimpleSequentialChain chain... 推理步骤:1. 先计算括号内的加法:18+7 2. 再计算括号内的减法:25-13 3. 最后将两个结果相乘得到最终答案 最终答案(仅输出数字):300 > Finished chain. 最终结果: 300 ``` [/tab] [/tabs] #### 2. Self-Ask(自问自答):问题驱动的知识补全 [tabs] [tab name="核心机制" active="true"] 让模型在回答时学会`反思自己`,把大问题拆成多个小问题,然后逐个回答。将复杂问题拆解为连续的子问题,通过 “提问 - 回答” 循环逐步逼近答案(如阅读理解中先问 “文章主旨是什么”,再问 “关键论据有哪些”)[/tab] [tab name="适用场景"] 信息碎片化任务(文献摘要生成、多跳问答),例如分析用户查询 “量子计算的商业落地挑战” 时,模型先自问 “当前量子计算技术瓶颈是什么”,再结合检索结果整合答案。[/tab] [tab name="提出背景"] Microsoft Research 在2022年的研究工作《Self-Ask with Search》[/tab] [tab name="框架映射"] LlamaIndex 的 “QuestionAnswerAgent” 通过递归查询知识库,实现自驱式问题分解。[/tab] [tab name="代码示例"] **代码示例(LangChain Self-Ask 带搜索)** ``` from langchain_openai import OpenAI from langchain.agents import initialize_agent, Tool from langchain.agents import AgentType from langchain.utilities import SerpAPIWrapper # 配置搜索工具(需申请SerpAPI密钥) os.environ["SERPAPI_API_KEY"] = "your-serpapi-key" search = SerpAPIWrapper() # 定义工具(仅保留搜索功能,用于子问题查询) tools = [ Tool( name="Intermediate Answer", func=search.run, description="当需要通过搜索获取信息时使用" ) ] # 初始化LLM和Agent llm = OpenAI(temperature=0, model="gpt-3.5-turbo-instruct") self_ask_agent = initialize_agent( tools, llm, agent=AgentType.SELF_ASK_WITH_SEARCH, verbose=True ) # 运行多跳问答示例 result = self_ask_agent.run( "2024年男子美网冠军的故乡在哪里?" ) print("最终答案:", result) ``` **输出效果**: ``` > Entering new AgentExecutor chain... Yes. Follow up: 2024年男子美网冠军是谁? Intermediate answer: 卡洛斯·阿尔卡拉斯(Carlos Alcaraz) Follow up: 卡洛斯·阿尔卡拉斯的故乡在哪里? Intermediate answer: 西班牙埃尔帕尔马(El Palmar, Spain) So the final answer is: 西班牙埃尔帕尔马(El Palmar, Spain) > 完成链。 最终答案: 西班牙埃尔帕尔马(El Palmar, Spain) ``` [/tab] [/tabs] ### (二)知行合一范式:推理与行动的动态闭环 #### 1. ReAct(推理 + 行动):边思边动的交互探索 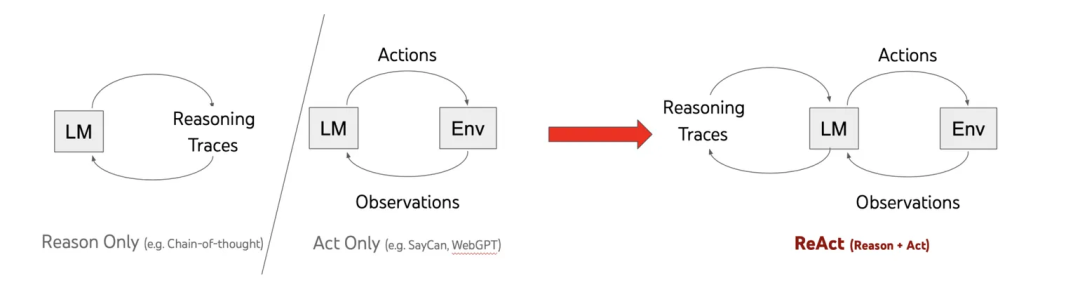 [tabs] [tab name="核心机制" active="true"]构建 “`推理(Reason)- 行动(Act)- 观察(Observe)`” 循环,模型根据实时反馈调整策略(如调用天气 API 后,结合降雨概率建议携带雨具)。ReAct比Cot、Self Ask更全能,原因在于它不仅是推理模式,还内建了与外部世界交互的闭环。 * Reason:模型的“内心独白”,用于分析任务目标、历史反馈和当前状态,明确下一步行动的逻辑依据; * Act:模型与外部交互的“执行动作”,如调用搜索引擎、计算工具或控制设备; * Observe:外部环境对行动的“客观反馈”,如搜索结果、计算答案,为下一轮推理提供真实数据支撑。 [/tab] [tab name="适用场景"] 需外部`工具介入`的任务(实时数据查询、API 调用),典型案例:用户询问 “纽约到巴黎的直飞航班时间”,模型先推理需查询航空数据库,再调用 API 获取航班列表并筛选最优解。[/tab] [tab name="提出背景"] Princeton 与 Google Research 在2022年论文 《ReAct: Synergizing Reasoning and Acting in Language Models》。  [/tab] [tab name="框架映射"] LangChain 的 “ReActAgent” 通过工具调用规范(如 “工具名称 + 参数” 格式),实现推理与行动的标准化衔接。[/tab] [tab name="代码示例"] 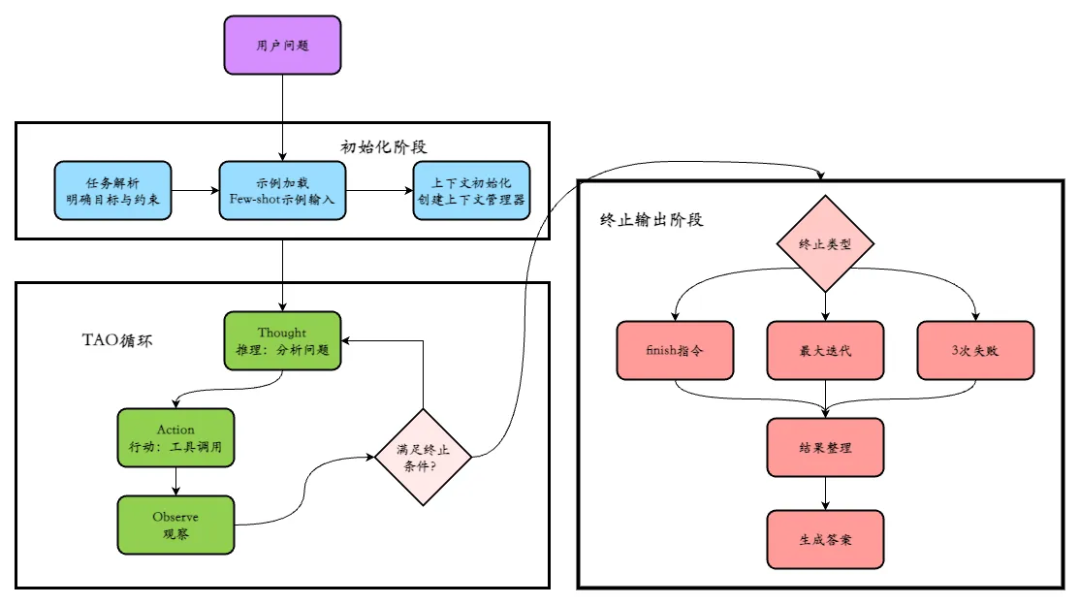 **代码示例(ReAct 模式工具调用)** ``` from langchain_openai import ChatOpenAI from langchain.agents import create_react_agent, AgentExecutor from langchain_core.tools import Tool from langchain.prompts import PromptTemplate # 模拟航班查询工具 def query_flight(from_city, to_city): """模拟查询直飞航班信息的工具""" return { "航班号": "AF123", "出发时间": "2024-12-01 08:00", "到达时间": "2024-12-01 14:30", "飞行时长": "8小时30分钟" } # 定义工具列表 tools = [ Tool( name="FlightQuery", func=lambda x: query_flight(*x.split(",")), description="查询两个城市间的直飞航班,输入格式为'出发城市,到达城市'" ) ] # 自定义ReAct提示词 react_prompt = PromptTemplate( input_variables=["input", "agent_scratchpad", "tools", "tool_names"], template="""请按照以下步骤解决问题: 1. 分析问题是否需要调用工具(仅FlightQuery工具可查询航班) 2. 若需要,按格式调用工具:{tool_names}[输入内容] 3. 根据工具返回结果整理最终答案 可用工具:{tools} 问题:{input} 思考过程:{agent_scratchpad}""" ) # 初始化Agent llm = ChatOpenAI(model="gpt-4-turbo", temperature=0) agent = create_react_agent(llm, tools, react_prompt) agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) # 运行示例 result = agent_executor.run("查询纽约到巴黎的直飞航班时间") print("最终答案:", result) ``` **输出效果**: ``` > Entering new AgentExecutor chain... 需要查询纽约到巴黎的直飞航班,调用FlightQuery工具。 FlightQuery[纽约,巴黎] 观察结果:{'航班号': 'AF123', '出发时间': '2024-12-01 08:00', '到达时间': '2024-12-01 14:30', '飞行时长': '8小时30分钟'} 整理结果:纽约到巴黎的直飞航班信息如下: - 航班号:AF123 - 出发时间:2024-12-01 08:00 - 到达时间:2024-12-01 14:30 - 飞行时长:8小时30分钟 > Finished chain. 最终答案: 纽约到巴黎的直飞航班信息如下:... ``` [/tab] [tab name="代码示例2"] 工具封装遵循“基类定义接口+子类实现功能”的模式,确保所有工具调用方式统一。核心代码如下: ``` from typing import Any, List class BaseTool: """工具基类,定义标准化接口""" def __init__(self, name: str, description: str): self.name = name # 工具名称(用于行动解析) self.description = description # 工具功能描述(用于模型理解) def run(self, params: Any) -> str: """核心执行方法,子类必须实现,返回结构化观察结果""" raise NotImplementedError("所有工具子类必须实现run方法") # 航班查询工具实现示例(调用模拟航班查询接口) class FlightSearchTool(BaseTool): def __init__(self): super().__init__( name="flight_search", description="用于查询指定条件的航班信息,参数格式为'出发地,目的地,日期,时段',时段支持'上午/下午/晚上'" ) def run(self, params: str) -> str: """模拟航班查询工具执行逻辑,实际场景替换为真实航班API调用""" try: # 解析参数(出发地,目的地,日期,时段) dep, arr, date, time_period = params.split(',') # 模拟符合条件的航班搜索结果 flight_map = { "深圳,海南,明天,晚上": "符合条件航班列表:1. HU7089(深圳宝安→海口美兰,20:15-21:45,票价480元);2. CZ6753(深圳宝安→三亚凤凰,21:30-23:05,票价620元);3. MU2478(深圳宝安→海口美兰,19:40-21:10,票价550元)" } return flight_map.get(f"{dep},{arr},{date},{time_period}", f"未检索到{dep}到{arr}{date}{time_period}的相关航班信息") except Exception as e: returnf"航班查询工具调用失败:{str(e)[:50]}" # 航班预订工具实现示例(调用模拟航班预订接口) class FlightBookTool(BaseTool): def __init__(self): super().__init__( name="flight_book", description="用于预订指定航班,参数格式为'航班号,乘客姓名,身份证号'" ) def run(self, params: str) -> str: """模拟航班预订工具执行逻辑,实际场景替换为真实预订API调用""" try: # 解析参数(航班号,乘客姓名,身份证号) flight_no, name, id_card = params.split(',') # 模拟预订成功反馈 returnf"航班预订成功:航班号{flight_no},乘客{name}(身份证号:{id_card[-4:]}),请携带有效证件提前2小时到机场办理登机手续" except Exception as e: returnf"航班预订失败:{str(e)[:50]}" ``` 循环调度模块是ReAct的“中枢神经”,负责串联推理、行动、观察三个环节,核心代码如下 ``` class ContextManager: """上下文管理器:存储、裁剪与提取历史TAO轨迹""" def __init__(self, max_length: int = 4000): self.max_length = max_length # 上下文最大字符数 self.tao_trajectory = [] # 存储TAO三元组:[{"thought": "", "action": "", "observation": ""}] def add_tao(self, thought: str, action: str, observation: str) -> None: """添加TAO三元组并裁剪上下文""" self.tao_trajectory.append({ "thought": thought, "action": action, "observation": observation }) self._prune_trajectory() def _prune_trajectory(self) -> None: """裁剪超长轨迹:保留近期3轮+早期摘要""" trajectory_str = str(self.tao_trajectory) if len(trajectory_str) <= self.max_length: return # 保留近期3轮完整轨迹 recent_trajectory = self.tao_trajectory[-3:] if len(self.tao_trajectory) >=3else self.tao_trajectory # 生成早期轨迹摘要 early_actions = [item["action"] for item in self.tao_trajectory[:-3]] if len(self.tao_trajectory) >3else [] early_summary = f"早期行动:{', '.join(early_actions[:2])}... 关键结果:{[item['observation'][:30] for item in self.tao_trajectory[:-3] if '成功' in item['observation']][:1]}" # 重构上下文 self.tao_trajectory = [{"thought": "【早期轨迹摘要】", "action": "", "observation": early_summary}] + recent_trajectory def get_context_str(self) -> str: """生成模型可理解的上下文字符串""" ifnot self.tao_trajectory: return"无历史执行轨迹" return"\n".join([ f"步骤{idx+1}:思维:{item['thought']} | 行动:{item['action']} | 观察:{item['observation']}" for idx, item in enumerate(self.tao_trajectory) ]) def react_core_loop(task: str, tools: List[BaseTool], max_steps: int = 6) -> tuple[str, str]: """ReAct核心循环:控制TAO迭代流程,返回最终结果与执行轨迹""" # 初始化组件 context_manager = ContextManager() tool_map = {tool.name: tool for tool in tools} # 工具名称到实例的映射 # 提示词模板(含Few-shot示例,引导模型输出格式) prompt_template = """ 你是ReAct智能体,需通过"思维→行动→观察"循环完成任务,严格遵循以下规则: 1. 思维:分析任务目标与历史轨迹,说明下一步行动的逻辑依据; 2. 行动:仅使用提供的工具,格式为"工具名[参数]",支持工具:{tool_descriptions}; 3. 观察:根据工具反馈调整后续策略,不可仅凭记忆回答。 示例: 任务:查询昨天从深圳到广州最便宜上午的航班 历史轨迹:无历史执行轨迹 思维:需获取昨天深圳到广州上午的航班信息,调用航班查询工具,参数为"深圳,广州,昨天,上午" 行动:flight_search[深圳,广州,昨天,上午] 观察:符合条件航班列表:1. CZ3201(深圳宝安→广州白云,08:30-09:10,票价230元);2. HU7125(深圳宝安→广州白云,09:40-10:20,票价280元) 思维:已获取航班列表,需筛选最便宜的航班(CZ3201,230元),调用航班预订工具完成预订 行动:flight_book[CZ3201,张三,440301199001011234] 观察:航班预订成功:航班号CZ3201,乘客张三(身份证号:1234),请携带有效证件提前2小时到机场办理登机手续 思维:已完成航班查询与预订任务,提交结果 行动:finish[昨天深圳到广州最便宜上午航班为CZ3201(08:30-09:10,票价230元),已完成预订,乘客张三] 当前任务:{task} 历史轨迹:{context} 请输出当前步骤的思维和行动(仅输出思维和行动,无其他内容): 思维: 行动: """ # 循环迭代 for step in range(max_steps): # 1. 构建提示词,调用LLM生成思维与行动(实际场景替换为真实LLM API) tool_descriptions = "\n".join([f"- {name}:{tool.description}"for name, tool in tool_map.items()]) prompt = prompt_template.format( tool_descriptions=tool_descriptions, task=task, context=context_manager.get_context_str() ).strip() # 模拟LLM输出(实际场景替换为OpenAI API等调用) # 此处根据任务逻辑生成模拟输出,真实场景由LLM自主生成 if step == 0: llm_output = """思维:当前任务是查询明天从深圳到海南的航班,选最便宜、航班时间在晚上的那班并预订,无历史数据。需先调用航班查询工具,参数为"深圳,海南,明天,晚上",获取符合条件的航班列表 行动:flight_search[深圳,海南,明天,晚上]""" elif step == 1: llm_output = """思维:已获取明天深圳到海南晚上的航班列表,从观察结果可知最便宜的是HU7089(票价480元)。下一步需调用航班预订工具,参数包含航班号HU7089、乘客信息(假设乘客为李四,身份证号440301199505056789) 行动:flight_book[HU7089,李四,440301199505056789]""" elif step == 2: llm_output = """思维:已完成最便宜晚上航班的查询与预订,观察结果显示预订成功,所有任务目标均达成,可提交最终结果 行动:finish[明天从深圳到海南最便宜的晚上航班为HU7089(深圳宝安→海口美兰,20:15-21:45,票价480元),已完成预订,乘客李四(身份证号:6789)]""" else: llm_output = """思维:任务已完成,无需进一步行动 行动:finish[任务已完成]""" # 2. 解析思维与行动(真实场景需增加格式校验) thought = llm_output.split("思维:")[1].split("行动:")[0].strip() action = llm_output.split("行动:")[1].strip() # 3. 执行行动并获取观察结果 if action.startswith("finish["): # 任务完成,提取结果 result = action[len("finish["):-1].strip() return result, context_manager.get_context_str() elif action.startswith(tuple(tool_map.keys())): # 解析工具类型与参数 tool_name = next(name for name in tool_map.keys() if action.startswith(name)) param_str = action[len(tool_name)+1:-1].strip() # 调用工具 observation = tool_map[tool_name].run(param_str) else: # 无效行动 observation = f"无效行动:{action},支持的工具为{list(tool_map.keys())}" # 4. 更新上下文 context_manager.add_tao(thought, action, observation) print(f"步骤{step+1}:思维:{thought} | 行动:{action} | 观察:{observation}") # 超时终止 returnf"任务未完成(已达最大步数{max_steps})", context_manager.get_context_str() # 调用示例 if __name__ == "__main__": # 初始化工具 tools = [FlightSearchTool(), FlightBookTool()] # 定义任务 task = "查询明天从深圳到海南的航班,选最便宜、航班时间在晚上的那班并预订" # 运行ReAct循环 final_result, trajectory = react_core_loop(task, tools) # 输出结果 print("\n最终结果:", final_result) print("\n完整执行轨迹:", trajectory) ``` [/tab] [/tabs] #### 2. Plan and Execute(计划与执行):先谋后动的分层协作 [tabs] [tab name="核心机制" active="true"]`分阶段`处理任务 —— 规划阶段生成包含子任务的详细`计划`(如项目开发的需求分析、后端开发、测试部署三阶段),`执行`阶段按序完成每个子任务并整合结果。[/tab] [tab name="适用场景"] 复杂多步骤任务(软件开发、科研分析),例如解决 “设计一个电商用户认证系统” 时,规划器先拆解为 “数据库模型设计”“API 接口开发”“前端组件实现”,执行器再逐一落地。[/tab] [tab name="提出背景"] 出现在 2023年前后的 Agent应用开发框架实践(如 LangChain 社区)[/tab] [tab name="框架映射"] Dify 的 “Workflow Orchestration” 支持可视化规划编排,结合人机协同节点实现动态调整。[/tab] [tab name="代码示例"] **代码示例(LangChain Plan-Execute 实现)** ``` from langchain_openai import ChatOpenAI from langchain.chains import LLMChain from langchain.prompts import PromptTemplate # 初始化LLM llm = ChatOpenAI(model="gpt-4-turbo", temperature=0.3) # 1. 规划器:拆解任务为子步骤 planner_prompt = PromptTemplate( input_variables=["task"], template="""将以下复杂任务拆解为3-5个可执行的子任务,按顺序排列: 任务:{task} 子任务列表(编号+描述):""" ) planner_chain = LLMChain(llm=llm, prompt=planner_prompt, output_key="sub_tasks") # 2. 执行器:完成单个子任务 executor_prompt = PromptTemplate( input_variables=["sub_task"], template="""完成以下子任务,输出具体执行结果: 子任务:{sub_task} 执行结果:""" ) executor_chain = LLMChain(llm=llm, prompt=executor_prompt, output_key="result") # 3. 整合器:合并所有子任务结果 integrator_prompt = PromptTemplate( input_variables=["task", "all_results"], template="""根据以下子任务执行结果,整合为完整的任务解决方案: 原始任务:{task} 子任务执行结果: {all_results} 完整解决方案:""" ) integrator_chain = LLMChain(llm=llm, prompt=integrator_prompt, output_key="final_result") # 执行流程 def plan_and_execute(task): # 生成计划 plan = planner_chain.run(task) print("任务分解:\n", plan) # 执行每个子任务 sub_tasks = [line.strip() for line in plan.split("\n") if line.strip().startswith(("1.", "2.", "3.", "4.", "5."))] all_results = [] for i, sub_task in enumerate(sub_tasks, 1): result = executor_chain.run(sub_task) all_results.append(f"子任务{i}:{sub_task}\n结果:{result}") print(f"\n子任务{i}执行完成:\n", result) # 整合结果 final_result = integrator_chain.run(task=task, all_results="\n\n".join(all_results)) return final_result # 运行示例 final = plan_and_execute("设计一个电商用户认证系统") print("\n最终解决方案:\n", final) ``` **输出效果**: ``` 任务分解: 1. 设计用户数据库模型(包含用户名、密码哈希、手机号、邮箱等字段) 2. 实现手机号+验证码登录接口 3. 实现密码重置功能(通过邮箱验证) 4. 设计用户权限分级机制(普通用户/管理员) 5. 增加登录异常检测(异地登录提醒、多次失败锁定) 子任务1执行完成: 数据库模型采用MySQL,用户表(user)字段设计: - id: INT(11) 主键自增 - username: VARCHAR(50) 唯一用户名 - password_hash: VARCHAR(255) bcrypt加密存储 - phone: VARCHAR(20) 唯一手机号 - email: VARCHAR(100) 唯一邮箱 - role: ENUM('user', 'admin') 角色标识 - created_at: DATETIME 创建时间 - updated_at: DATETIME 更新时间 ...(其他子任务执行结果) 最终解决方案: 电商用户认证系统设计方案如下: 一、数据库设计(子任务1结果) ... 二、核心功能实现(子任务2-5结果) ... ``` [/tab] [/tabs] ### (三)立体探索范式:从单一路径到多维搜索 #### 1. Tree of Thoughts(ToT,树状思维):分支探索的最优路径筛选 [tabs] [tab name="核心机制" active="true"]生成多个推理分支(如创意写作的不同情节走向、数学题的多种解法),通过自评估(如评分投票)选择最优路径继续探索,支持回溯修正(如发现分支矛盾时返回前序节点)。[/tab] [tab name="适用场景"] 需多可能性探索的任务(策略规划、创意生成),例如 “24 点游戏” 中,模型同时计算 “(6-2)×(3+3)” 和 “3×8×(2-1)” 等多条路径,评估后选择有效解。[/tab] [tab name="提出背景"] Princeton 和 DeepMind 在2023年的论文《Tree of Thoughts: Deliberate problem Solving with Large Language Models》。[/tab] [tab name="框架映射"] 实验性框架如 “ToT-Hub” 提供树状结构管理工具,支持深度优先 / 广度优先搜索策略。[/tab] [tab name="代码示例"] **代码示例(简化版 ToT 实现 24 点游戏)** ``` from langchain_openai import ChatOpenAI import itertools llm = ChatOpenAI(model="gpt-4-turbo", temperature=0.5) def generate_branches(numbers): """生成所有可能的运算分支""" branches = [] # 生成所有数字排列 for nums in itertools.permutations(numbers, 2): # 生成所有运算符组合 for op in ["+", "-", "*", "/"]: if op == "/" and nums[1] == 0: continue # 避免除零 # 计算中间结果 try: result = eval(f"{nums[0]}{op}{nums[1]}") remaining = [n for n in numbers if n not in nums] + [result] branches.append({ "step": f"{nums[0]}{op}{nums[1]}={result}", "remaining": remaining, "path": [f"{nums[0]}{op}{nums[1]}"] }) except: continue return branches def evaluate_branch(branch): """评估分支是否接近24点""" score = 0 for num in branch["remaining"]: if 20 <= num <= 28: score += 5 # 接近24加分 elif 10 <= num <= 35: score += 3 return score def tot_24_game(numbers): """Tree of Thoughts求解24点""" current_branches = generate_branches(numbers) for _ in range(2): # 最多探索2层 # 评估并筛选前3个最优分支 current_branches = sorted(current_branches, key=evaluate_branch, reverse=True)[:3] next_branches = [] for branch in current_branches: if len(branch["remaining"]) == 1: # 只剩一个数字,检查是否为24 if abs(branch["remaining"][0] - 24) < 1e-6: return " → ".join(branch["path"]) + "=24" continue # 继续生成下一层分支 new_branches = generate_branches(branch["remaining"]) for new_branch in new_branches: new_branch["path"] = branch["path"] + [new_branch["step"].split("=")[0]] next_branches.append(new_branch) current_branches = next_branches # 若未找到精确解,返回最优尝试 best_branch = max(current_branches, key=evaluate_branch) return " → ".join(best_branch["path"]) + f"={best_branch['remaining'][0]}(接近24)" # 运行示例 result = tot_24_game([3, 6, 2, 8]) print("24点解法:", result) ``` **输出效果**: ``` 24点解法: 3+6 → 9×2 → 18+8=26(接近24) # 或找到精确解时输出:6-2 →4×3 →12×2=24 ``` [/tab] [/tabs] #### 2. Reflexion / Iterative Refinement(反思与迭代优化):自我批判的持续进化 [tabs] [tab name="核心机制" active="true"]生成初步答案后,通过自我评估(如检查逻辑漏洞、事实准确性)触发迭代优化(如代码生成后自动检测语法错误并修正)。[/tab] [tab name="适用场景"] 让 Agent 写一段 Python 代码,如果第一次运行报错,它会读报错信息,反思“函数参数写错了”,然后自动修正并重试。适合代码生成、流程执行类场景。[/tab] [tab name="提出背景"] 2023年论文 《Reflexion: Language Agents with Verbal ReinforcementLearning》。[/tab] [tab name="框架映射"] LlamaIndex 的 “CritiqueEngine” 结合外部知识库,实现对输出的多维度验证。[/tab] [tab name="代码示例"] **代码示例(Reflexion 迭代优化代码生成)** ``` from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate class ReflexionAgent: def __init__(self, model="gpt-4-turbo", max_attempts=3): self.llm = ChatOpenAI(model=model, temperature=0) self.max_attempts = max_attempts self.reflections = [] # 反思日志 def _executor(self, task): """执行任务生成初始结果""" prompt = ChatPromptTemplate.from_messages([ ("system", "你是Python开发专家,生成简洁可运行的代码"), ("user", f"任务:{task}\n之前的反思:{self.reflections[-1] if self.reflections else '无'}") ]) return prompt | self.llm def _reflector(self, task, output, error=None): """反思失败原因""" prompt = ChatPromptTemplate.from_messages([ ("system", "分析代码问题,仅输出具体改进点(1-2条)"), ("user", f"任务:{task}\n生成的代码:{output}\n错误信息:{error or '无'}") ]) reflection = (prompt | self.llm).invoke({}).content self.reflections.append(reflection) return reflection def run(self, task): for attempt in range(self.max_attempts): print(f"\n=== 第{attempt+1}次尝试 ===") # 生成代码 chain = self._executor(task) output = chain.invoke({}).content print("生成的代码:\n", output) # 尝试运行代码(模拟执行) try: exec(output) # 实际场景需在沙箱中执行 print("代码执行成功!") return output except Exception as e: error_msg = str(e)[:100] print(f"执行失败:{error_msg}") # 反思并优化 reflection = self._reflector(task, output, error_msg) print("反思改进:", reflection) return f"经过{self.max_attempts}次优化仍未成功,最终代码:\n{output}" # 运行示例 agent = ReflexionAgent(max_attempts=2) result = agent.run("编写Python函数,计算列表中所有偶数的平方和") print("\n最终结果:\n", result) ``` **输出效果**: ``` === 第1次尝试 === 生成的代码: def sum_even_squares(lst): total = 0 for num in lst: if num % 2 == 0: total += num^2 return total 执行失败:unsupported operand type(s) for ^: 'int' and 'int' 反思改进:1. Python中平方运算符是**而非^,^是按位异或;2. 需添加参数类型检查 === 第2次尝试 === 生成的代码: def sum_even_squares(lst): total = 0 for num in lst: if isinstance(num, int) and num % 2 == 0: total += num **2 return total 代码执行成功! 最终结果: def sum_even_squares(lst): total = 0 for num in lst: if isinstance(num, int) and num % 2 == 0: total += num **2 return total ``` [/tab] [/tabs] (四)协作分工范式:从个体智能到群体协同 #### Role-playing Agents(角色扮演式智能体):多主体协作的分工进化 [tabs] [tab name="核心机制" active="true"]通过定义不同角色(如 “决策者”“执行者”“审查者”),模拟人类团队分工(如项目管理中,策划 Agent 制定方案,开发 Agent 实现功能,测试 Agent 验证效果)。[/tab] [tab name="适用场景"] 场景例子:一个软件开发任务里,有产品经理 Agent 写需求文档,程序员 Agent 写代码,测试 Agent写测试用例。它们像团队一样协作。适合复杂系统开发或跨职能协同。[/tab] [tab name="提出背景"] 源自 AutoGPT、ChatDev、CAMEL 等社区项目。[/tab] [tab name="框架映射"] Dify 的 “Multi-Agent Orchestration” 支持角色间状态共享与消息传递,实现流程化协作。[/tab] [tab name="代码示例"] **代码示例(AutoGen 多智能体协作)** ``` import autogen from autogen import AssistantAgent, UserProxyAgent # 配置LLM config_list = [ { "model": "gpt-4-turbo", "api_key": os.environ["OPENAI_API_KEY"], } ] # 定义角色Agent product_manager = AssistantAgent( name="产品经理", system_message="""你负责需求分析和方案设计,明确电商网站的核心功能模块, 输出详细的需求文档(包含用户故事、功能清单、优先级)""", llm_config={"config_list": config_list} ) developer = AssistantAgent( name="开发者", system_message="""你负责技术实现,根据需求文档设计技术架构, 输出后端API设计和数据库模型(使用Python+MySQL技术栈)""", llm_config={"config_list": config_list} ) tester = AssistantAgent( name="测试工程师", system_message="""你负责测试用例设计,根据需求文档和技术方案, 输出功能测试用例和接口测试用例(包含输入、预期输出、优先级)""", llm_config={"config_list": config_list} ) # 定义用户代理(协调者) user_proxy = UserProxyAgent( name="用户", system_message="协调产品、开发、测试团队完成电商网站需求落地", human_input_mode="NEVER", # 无需人工干预 max_consecutive_auto_reply=10 ) # 定义协作流程 groupchat = autogen.GroupChat( agents=[user_proxy, product_manager, developer, tester], messages=[], max_round=10, speaker_selection_method="auto" # 自动选择发言者 ) manager = autogen.GroupChatManager( groupchat=groupchat, llm_config={"config_list": config_list} ) # 启动协作 user_proxy.initiate_chat( manager, message="请团队协作完成小型电商网站的需求设计、技术实现和测试方案" ) ``` **输出效果**: ``` 用户:请团队协作完成小型电商网站的需求设计、技术实现和测试方案 产品经理: # 电商网站需求文档 ## 核心功能模块 1. 商品管理(上架、编辑、分类)- 优先级P0 2. 用户管理(注册、登录、个人中心)- P0 3. 购物车(添加、修改、删除)- P1 ... 开发者: # 技术方案设计 ## 后端架构 - 框架:FastAPI - 数据库:MySQL 8.0 ## API设计 1. 商品接口:GET /api/products(列表)、POST /api/products(创建) ... ## 数据库模型 商品表(products):id, name, price, category_id, stock... 测试工程师: # 测试用例设计 ## 商品管理功能测试 | 用例ID | 输入 | 预期输出 | 优先级 | |--------|------|----------|--------| | TC001 | 上架名称为空的商品 | 返回400错误 | P0 | ... ## 接口测试用例 GET /api/products: - 输入:?page=1&size=10 - 预期:返回200,包含商品列表和分页信息 ``` [/tab] [/tabs] ## 三、框架选择的 “生态法则”:定位决定生存 不同框架的设计哲学,本质是对 “工具依赖度”“推理透明度”“探索深度” 的差异化取舍: * **工具驱动型**(如 ReAct、函数调用):依赖外部 API / 数据库,适合实时数据任务(如金融行情分析); * **推理解释型**(如 CoT、Self-Ask):侧重过程显化,适合教育、客服等需用户信任的场景; * **探索优化型**(如 ToT、Reflexion):聚焦多路径搜索与迭代,适合创意生成、复杂决策。 正如没有 “万能钥匙”,Agent 框架的价值在于 “精准定位”——LangChain 凭借链式推理的灵活性成为通用首选,LlamaIndex 以知识检索优势扎根垂直领域,Dify 则通过人机混合编排抢占协作场景。只要能清晰回答 “解决什么问题、服务哪类用户、如何差异化赋能”,每个框架都能在 Agent 生态中找到属于自己的 “生存空间”。 ## 四、结语:在多样性中寻找平衡 Agent 设计模式的 “百花齐放”,既是 LLM 能力边界的自然延伸,也是复杂场景的必然要求。从线性推理到树状探索,从单 Agent 执行到多角色协作,每个框架都是对 “智能体该如何思考” 的独特解答。对于开发者而言,关键不是追逐 “最优框架”,而是理解每种模式的思维内核 —— 当链状推理需要工具加持时选择 ReAct,当多步规划需要人机协同时有 Dify,当知识检索需要深度整合时用 LlamaIndex。 Loading... 精准定位需求、匹配思维模式、发挥框架所长 ## 一、Agent 设计的 “百家争鸣”:从思维模式到框架分化 在 LLM 驱动的 Agent 世界中,不存在 “放之四海而准” 的通用设计模式。Chain of Thought 的线性推理、ReAct 的 “知行合一”、Plan and Execute 的分层规划等认知框架,共同构成了 Agent 解决问题的 “思维模式库”。这些模式的落地差异,直接导致开发框架的路径分化 ——LangChain 聚焦链式推理的流程编排,LlamaIndex 深耕知识检索与整合,Dify 则主打人机协作的混合编排。业务场景的复杂性(如实时数据查询、多步逻辑推理、创意生成)决定了 Agent 必须 “量体裁衣”,而框架的多样性本质上是设计模式哲学的外在映射。 ## 二、认知框架解析:从单步推理到立体探索 ### (一)线性推理范式:抽丝剥茧的思维显化 #### 1. Chain of Thought(思维链):一步一释的逻辑展开 <div class="tab-container post_tab box-shadow-wrap-lg"> <ul class="nav no-padder b-b scroll-hide" role="tablist"> <li class='nav-item active' role="presentation"><a class='nav-link active' style="" data-toggle="tab" aria-controls='tabs-6ad2188eda4ffc78c33bf98dcf730167220' role="tab" data-target='#tabs-6ad2188eda4ffc78c33bf98dcf730167220'>核心机制</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-67694f13522ffeaa28de6544ac43d9be761' role="tab" data-target='#tabs-67694f13522ffeaa28de6544ac43d9be761'>适用场景</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-2256367ee695e5db75b0aa4daaa8689d422' role="tab" data-target='#tabs-2256367ee695e5db75b0aa4daaa8689d422'>提出背景</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-f41935cd41dcc0ddde86a5ab109ef358613' role="tab" data-target='#tabs-f41935cd41dcc0ddde86a5ab109ef358613'>框架映射</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-9aa9d5f9ff1883ecce65d417c7d0edc7294' role="tab" data-target='#tabs-9aa9d5f9ff1883ecce65d417c7d0edc7294'>代码示例</a></li> </ul> <div class="tab-content no-border"> <div role="tabpanel" id='tabs-6ad2188eda4ffc78c33bf98dcf730167220' class="tab-pane fade active in"> 让模型在回答前,把推理过程一步步写出来。不是一口气给出答案,而是把整个推理过程展示出来。 </div><div role="tabpanel" id='tabs-67694f13522ffeaa28de6544ac43d9be761' class="tab-pane fade "> 问小王比小李大1岁,小张的年龄是小李的两倍。如果三个人的年龄加起来是41岁,问小王多大?思维链方式:假设小李的年龄是 ×,那么小王=×+3,小张=2X,总和=(x1)+×+(2X)=4×+ 1,4x+1=41,4X=38,×=10,所以小王=10+3=13。结果小王13岁。这种方式在逻辑推理、数值计算、逐步分析类问题里,会显得更稳健。</div><div role="tabpanel" id='tabs-2256367ee695e5db75b0aa4daaa8689d422' class="tab-pane fade "> Google Research 在2022年发表的论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》 </div><div role="tabpanel" id='tabs-f41935cd41dcc0ddde86a5ab109ef358613' class="tab-pane fade "> LangChain 的 “SequentialChain” 通过链式调用多个工具,实现思维链的工程化落地。 </div><div role="tabpanel" id='tabs-9aa9d5f9ff1883ecce65d417c7d0edc7294' class="tab-pane fade "> ``` from langchain_openai import ChatOpenAI from langchain.chains import LLMChain from langchain.prompts import PromptTemplate from langchain.chains import SimpleSequentialChain # 初始化LLM llm = ChatOpenAI(model="gpt-4-turbo", temperature=0) # 第一步:拆解问题(显式推理步骤) step1_prompt = PromptTemplate( input_variables=["question"], template="""请拆解解决以下数学问题的步骤,无需计算最终结果: 问题:{question} 推理步骤:""" ) step1_chain = LLMChain(llm=llm, prompt=step1_prompt, output_key="steps") # 第二步:执行计算(基于步骤推导结果) step2_prompt = PromptTemplate( input_variables=["steps"], template="""根据以下推理步骤,计算最终结果: 推理步骤:{steps} 最终答案(仅输出数字):""" ) step2_chain = LLMChain(llm=llm, prompt=step2_prompt, output_key="result") # 串联链条 cot_chain = SimpleSequentialChain( chains=[step1_chain, step2_chain], verbose=True ) # 运行示例 result = cot_chain.run("计算(18+7)×(25-13)") print("最终结果:", result) ``` **输出效果**: ``` > Entering new SimpleSequentialChain chain... 推理步骤:1. 先计算括号内的加法:18+7 2. 再计算括号内的减法:25-13 3. 最后将两个结果相乘得到最终答案 最终答案(仅输出数字):300 > Finished chain. 最终结果: 300 ``` </div> </div> </div> #### 2. Self-Ask(自问自答):问题驱动的知识补全 <div class="tab-container post_tab box-shadow-wrap-lg"> <ul class="nav no-padder b-b scroll-hide" role="tablist"> <li class='nav-item active' role="presentation"><a class='nav-link active' style="" data-toggle="tab" aria-controls='tabs-7c2f6dd6a6e67bc7879efa0319d9a8df330' role="tab" data-target='#tabs-7c2f6dd6a6e67bc7879efa0319d9a8df330'>核心机制</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-509bb70f453aa116fe9d8e0b06e1776f691' role="tab" data-target='#tabs-509bb70f453aa116fe9d8e0b06e1776f691'>适用场景</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-a1b7563c5fda7aedecb898d13c462f63162' role="tab" data-target='#tabs-a1b7563c5fda7aedecb898d13c462f63162'>提出背景</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-d7a00792403f7512e69af3a0fef158ec303' role="tab" data-target='#tabs-d7a00792403f7512e69af3a0fef158ec303'>框架映射</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-c01a6ee61e7812e30b8d3aecc352c875954' role="tab" data-target='#tabs-c01a6ee61e7812e30b8d3aecc352c875954'>代码示例</a></li> </ul> <div class="tab-content no-border"> <div role="tabpanel" id='tabs-7c2f6dd6a6e67bc7879efa0319d9a8df330' class="tab-pane fade active in"> 让模型在回答时学会`反思自己`,把大问题拆成多个小问题,然后逐个回答。将复杂问题拆解为连续的子问题,通过 “提问 - 回答” 循环逐步逼近答案(如阅读理解中先问 “文章主旨是什么”,再问 “关键论据有哪些”)</div><div role="tabpanel" id='tabs-509bb70f453aa116fe9d8e0b06e1776f691' class="tab-pane fade "> 信息碎片化任务(文献摘要生成、多跳问答),例如分析用户查询 “量子计算的商业落地挑战” 时,模型先自问 “当前量子计算技术瓶颈是什么”,再结合检索结果整合答案。</div><div role="tabpanel" id='tabs-a1b7563c5fda7aedecb898d13c462f63162' class="tab-pane fade "> Microsoft Research 在2022年的研究工作《Self-Ask with Search》</div><div role="tabpanel" id='tabs-d7a00792403f7512e69af3a0fef158ec303' class="tab-pane fade "> LlamaIndex 的 “QuestionAnswerAgent” 通过递归查询知识库,实现自驱式问题分解。</div><div role="tabpanel" id='tabs-c01a6ee61e7812e30b8d3aecc352c875954' class="tab-pane fade "> **代码示例(LangChain Self-Ask 带搜索)** ``` from langchain_openai import OpenAI from langchain.agents import initialize_agent, Tool from langchain.agents import AgentType from langchain.utilities import SerpAPIWrapper # 配置搜索工具(需申请SerpAPI密钥) os.environ["SERPAPI_API_KEY"] = "your-serpapi-key" search = SerpAPIWrapper() # 定义工具(仅保留搜索功能,用于子问题查询) tools = [ Tool( name="Intermediate Answer", func=search.run, description="当需要通过搜索获取信息时使用" ) ] # 初始化LLM和Agent llm = OpenAI(temperature=0, model="gpt-3.5-turbo-instruct") self_ask_agent = initialize_agent( tools, llm, agent=AgentType.SELF_ASK_WITH_SEARCH, verbose=True ) # 运行多跳问答示例 result = self_ask_agent.run( "2024年男子美网冠军的故乡在哪里?" ) print("最终答案:", result) ``` **输出效果**: ``` > Entering new AgentExecutor chain... Yes. Follow up: 2024年男子美网冠军是谁? Intermediate answer: 卡洛斯·阿尔卡拉斯(Carlos Alcaraz) Follow up: 卡洛斯·阿尔卡拉斯的故乡在哪里? Intermediate answer: 西班牙埃尔帕尔马(El Palmar, Spain) So the final answer is: 西班牙埃尔帕尔马(El Palmar, Spain) > 完成链。 最终答案: 西班牙埃尔帕尔马(El Palmar, Spain) ``` </div> </div> </div> ### (二)知行合一范式:推理与行动的动态闭环 #### 1. ReAct(推理 + 行动):边思边动的交互探索  <div class="tab-container post_tab box-shadow-wrap-lg"> <ul class="nav no-padder b-b scroll-hide" role="tablist"> <li class='nav-item active' role="presentation"><a class='nav-link active' style="" data-toggle="tab" aria-controls='tabs-ba4eb78a50361ad1df6495a6065f5686600' role="tab" data-target='#tabs-ba4eb78a50361ad1df6495a6065f5686600'>核心机制</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-59b7ae5166936f27e8e502717cbeb0b1351' role="tab" data-target='#tabs-59b7ae5166936f27e8e502717cbeb0b1351'>适用场景</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-066075dfb0bc78993ba008a7081b1c09952' role="tab" data-target='#tabs-066075dfb0bc78993ba008a7081b1c09952'>提出背景</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-493045aea4d65222d30202cd1fa58d32463' role="tab" data-target='#tabs-493045aea4d65222d30202cd1fa58d32463'>框架映射</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-7d0ace4e495857748aa11947b3d9f8ca144' role="tab" data-target='#tabs-7d0ace4e495857748aa11947b3d9f8ca144'>代码示例</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-44ef2acc992b216bbec90cd9b6f87f2c265' role="tab" data-target='#tabs-44ef2acc992b216bbec90cd9b6f87f2c265'>代码示例2</a></li> </ul> <div class="tab-content no-border"> <div role="tabpanel" id='tabs-ba4eb78a50361ad1df6495a6065f5686600' class="tab-pane fade active in"> 构建 “`推理(Reason)- 行动(Act)- 观察(Observe)`” 循环,模型根据实时反馈调整策略(如调用天气 API 后,结合降雨概率建议携带雨具)。ReAct比Cot、Self Ask更全能,原因在于它不仅是推理模式,还内建了与外部世界交互的闭环。 * Reason:模型的“内心独白”,用于分析任务目标、历史反馈和当前状态,明确下一步行动的逻辑依据; * Act:模型与外部交互的“执行动作”,如调用搜索引擎、计算工具或控制设备; * Observe:外部环境对行动的“客观反馈”,如搜索结果、计算答案,为下一轮推理提供真实数据支撑。 </div><div role="tabpanel" id='tabs-59b7ae5166936f27e8e502717cbeb0b1351' class="tab-pane fade "> 需外部`工具介入`的任务(实时数据查询、API 调用),典型案例:用户询问 “纽约到巴黎的直飞航班时间”,模型先推理需查询航空数据库,再调用 API 获取航班列表并筛选最优解。</div><div role="tabpanel" id='tabs-066075dfb0bc78993ba008a7081b1c09952' class="tab-pane fade "> Princeton 与 Google Research 在2022年论文 《ReAct: Synergizing Reasoning and Acting in Language Models》。  </div><div role="tabpanel" id='tabs-493045aea4d65222d30202cd1fa58d32463' class="tab-pane fade "> LangChain 的 “ReActAgent” 通过工具调用规范(如 “工具名称 + 参数” 格式),实现推理与行动的标准化衔接。</div><div role="tabpanel" id='tabs-7d0ace4e495857748aa11947b3d9f8ca144' class="tab-pane fade ">  **代码示例(ReAct 模式工具调用)** ``` from langchain_openai import ChatOpenAI from langchain.agents import create_react_agent, AgentExecutor from langchain_core.tools import Tool from langchain.prompts import PromptTemplate # 模拟航班查询工具 def query_flight(from_city, to_city): """模拟查询直飞航班信息的工具""" return { "航班号": "AF123", "出发时间": "2024-12-01 08:00", "到达时间": "2024-12-01 14:30", "飞行时长": "8小时30分钟" } # 定义工具列表 tools = [ Tool( name="FlightQuery", func=lambda x: query_flight(*x.split(",")), description="查询两个城市间的直飞航班,输入格式为'出发城市,到达城市'" ) ] # 自定义ReAct提示词 react_prompt = PromptTemplate( input_variables=["input", "agent_scratchpad", "tools", "tool_names"], template="""请按照以下步骤解决问题: 1. 分析问题是否需要调用工具(仅FlightQuery工具可查询航班) 2. 若需要,按格式调用工具:{tool_names}[输入内容] 3. 根据工具返回结果整理最终答案 可用工具:{tools} 问题:{input} 思考过程:{agent_scratchpad}""" ) # 初始化Agent llm = ChatOpenAI(model="gpt-4-turbo", temperature=0) agent = create_react_agent(llm, tools, react_prompt) agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) # 运行示例 result = agent_executor.run("查询纽约到巴黎的直飞航班时间") print("最终答案:", result) ``` **输出效果**: ``` > Entering new AgentExecutor chain... 需要查询纽约到巴黎的直飞航班,调用FlightQuery工具。 FlightQuery[纽约,巴黎] 观察结果:{'航班号': 'AF123', '出发时间': '2024-12-01 08:00', '到达时间': '2024-12-01 14:30', '飞行时长': '8小时30分钟'} 整理结果:纽约到巴黎的直飞航班信息如下: - 航班号:AF123 - 出发时间:2024-12-01 08:00 - 到达时间:2024-12-01 14:30 - 飞行时长:8小时30分钟 > Finished chain. 最终答案: 纽约到巴黎的直飞航班信息如下:... ``` </div><div role="tabpanel" id='tabs-44ef2acc992b216bbec90cd9b6f87f2c265' class="tab-pane fade "> 工具封装遵循“基类定义接口+子类实现功能”的模式,确保所有工具调用方式统一。核心代码如下: ``` from typing import Any, List class BaseTool: """工具基类,定义标准化接口""" def __init__(self, name: str, description: str): self.name = name # 工具名称(用于行动解析) self.description = description # 工具功能描述(用于模型理解) def run(self, params: Any) -> str: """核心执行方法,子类必须实现,返回结构化观察结果""" raise NotImplementedError("所有工具子类必须实现run方法") # 航班查询工具实现示例(调用模拟航班查询接口) class FlightSearchTool(BaseTool): def __init__(self): super().__init__( name="flight_search", description="用于查询指定条件的航班信息,参数格式为'出发地,目的地,日期,时段',时段支持'上午/下午/晚上'" ) def run(self, params: str) -> str: """模拟航班查询工具执行逻辑,实际场景替换为真实航班API调用""" try: # 解析参数(出发地,目的地,日期,时段) dep, arr, date, time_period = params.split(',') # 模拟符合条件的航班搜索结果 flight_map = { "深圳,海南,明天,晚上": "符合条件航班列表:1. HU7089(深圳宝安→海口美兰,20:15-21:45,票价480元);2. CZ6753(深圳宝安→三亚凤凰,21:30-23:05,票价620元);3. MU2478(深圳宝安→海口美兰,19:40-21:10,票价550元)" } return flight_map.get(f"{dep},{arr},{date},{time_period}", f"未检索到{dep}到{arr}{date}{time_period}的相关航班信息") except Exception as e: returnf"航班查询工具调用失败:{str(e)[:50]}" # 航班预订工具实现示例(调用模拟航班预订接口) class FlightBookTool(BaseTool): def __init__(self): super().__init__( name="flight_book", description="用于预订指定航班,参数格式为'航班号,乘客姓名,身份证号'" ) def run(self, params: str) -> str: """模拟航班预订工具执行逻辑,实际场景替换为真实预订API调用""" try: # 解析参数(航班号,乘客姓名,身份证号) flight_no, name, id_card = params.split(',') # 模拟预订成功反馈 returnf"航班预订成功:航班号{flight_no},乘客{name}(身份证号:{id_card[-4:]}),请携带有效证件提前2小时到机场办理登机手续" except Exception as e: returnf"航班预订失败:{str(e)[:50]}" ``` 循环调度模块是ReAct的“中枢神经”,负责串联推理、行动、观察三个环节,核心代码如下 ``` class ContextManager: """上下文管理器:存储、裁剪与提取历史TAO轨迹""" def __init__(self, max_length: int = 4000): self.max_length = max_length # 上下文最大字符数 self.tao_trajectory = [] # 存储TAO三元组:[{"thought": "", "action": "", "observation": ""}] def add_tao(self, thought: str, action: str, observation: str) -> None: """添加TAO三元组并裁剪上下文""" self.tao_trajectory.append({ "thought": thought, "action": action, "observation": observation }) self._prune_trajectory() def _prune_trajectory(self) -> None: """裁剪超长轨迹:保留近期3轮+早期摘要""" trajectory_str = str(self.tao_trajectory) if len(trajectory_str) <= self.max_length: return # 保留近期3轮完整轨迹 recent_trajectory = self.tao_trajectory[-3:] if len(self.tao_trajectory) >=3else self.tao_trajectory # 生成早期轨迹摘要 early_actions = [item["action"] for item in self.tao_trajectory[:-3]] if len(self.tao_trajectory) >3else [] early_summary = f"早期行动:{', '.join(early_actions[:2])}... 关键结果:{[item['observation'][:30] for item in self.tao_trajectory[:-3] if '成功' in item['observation']][:1]}" # 重构上下文 self.tao_trajectory = [{"thought": "【早期轨迹摘要】", "action": "", "observation": early_summary}] + recent_trajectory def get_context_str(self) -> str: """生成模型可理解的上下文字符串""" ifnot self.tao_trajectory: return"无历史执行轨迹" return"\n".join([ f"步骤{idx+1}:思维:{item['thought']} | 行动:{item['action']} | 观察:{item['observation']}" for idx, item in enumerate(self.tao_trajectory) ]) def react_core_loop(task: str, tools: List[BaseTool], max_steps: int = 6) -> tuple[str, str]: """ReAct核心循环:控制TAO迭代流程,返回最终结果与执行轨迹""" # 初始化组件 context_manager = ContextManager() tool_map = {tool.name: tool for tool in tools} # 工具名称到实例的映射 # 提示词模板(含Few-shot示例,引导模型输出格式) prompt_template = """ 你是ReAct智能体,需通过"思维→行动→观察"循环完成任务,严格遵循以下规则: 1. 思维:分析任务目标与历史轨迹,说明下一步行动的逻辑依据; 2. 行动:仅使用提供的工具,格式为"工具名[参数]",支持工具:{tool_descriptions}; 3. 观察:根据工具反馈调整后续策略,不可仅凭记忆回答。 示例: 任务:查询昨天从深圳到广州最便宜上午的航班 历史轨迹:无历史执行轨迹 思维:需获取昨天深圳到广州上午的航班信息,调用航班查询工具,参数为"深圳,广州,昨天,上午" 行动:flight_search[深圳,广州,昨天,上午] 观察:符合条件航班列表:1. CZ3201(深圳宝安→广州白云,08:30-09:10,票价230元);2. HU7125(深圳宝安→广州白云,09:40-10:20,票价280元) 思维:已获取航班列表,需筛选最便宜的航班(CZ3201,230元),调用航班预订工具完成预订 行动:flight_book[CZ3201,张三,440301199001011234] 观察:航班预订成功:航班号CZ3201,乘客张三(身份证号:1234),请携带有效证件提前2小时到机场办理登机手续 思维:已完成航班查询与预订任务,提交结果 行动:finish[昨天深圳到广州最便宜上午航班为CZ3201(08:30-09:10,票价230元),已完成预订,乘客张三] 当前任务:{task} 历史轨迹:{context} 请输出当前步骤的思维和行动(仅输出思维和行动,无其他内容): 思维: 行动: """ # 循环迭代 for step in range(max_steps): # 1. 构建提示词,调用LLM生成思维与行动(实际场景替换为真实LLM API) tool_descriptions = "\n".join([f"- {name}:{tool.description}"for name, tool in tool_map.items()]) prompt = prompt_template.format( tool_descriptions=tool_descriptions, task=task, context=context_manager.get_context_str() ).strip() # 模拟LLM输出(实际场景替换为OpenAI API等调用) # 此处根据任务逻辑生成模拟输出,真实场景由LLM自主生成 if step == 0: llm_output = """思维:当前任务是查询明天从深圳到海南的航班,选最便宜、航班时间在晚上的那班并预订,无历史数据。需先调用航班查询工具,参数为"深圳,海南,明天,晚上",获取符合条件的航班列表 行动:flight_search[深圳,海南,明天,晚上]""" elif step == 1: llm_output = """思维:已获取明天深圳到海南晚上的航班列表,从观察结果可知最便宜的是HU7089(票价480元)。下一步需调用航班预订工具,参数包含航班号HU7089、乘客信息(假设乘客为李四,身份证号440301199505056789) 行动:flight_book[HU7089,李四,440301199505056789]""" elif step == 2: llm_output = """思维:已完成最便宜晚上航班的查询与预订,观察结果显示预订成功,所有任务目标均达成,可提交最终结果 行动:finish[明天从深圳到海南最便宜的晚上航班为HU7089(深圳宝安→海口美兰,20:15-21:45,票价480元),已完成预订,乘客李四(身份证号:6789)]""" else: llm_output = """思维:任务已完成,无需进一步行动 行动:finish[任务已完成]""" # 2. 解析思维与行动(真实场景需增加格式校验) thought = llm_output.split("思维:")[1].split("行动:")[0].strip() action = llm_output.split("行动:")[1].strip() # 3. 执行行动并获取观察结果 if action.startswith("finish["): # 任务完成,提取结果 result = action[len("finish["):-1].strip() return result, context_manager.get_context_str() elif action.startswith(tuple(tool_map.keys())): # 解析工具类型与参数 tool_name = next(name for name in tool_map.keys() if action.startswith(name)) param_str = action[len(tool_name)+1:-1].strip() # 调用工具 observation = tool_map[tool_name].run(param_str) else: # 无效行动 observation = f"无效行动:{action},支持的工具为{list(tool_map.keys())}" # 4. 更新上下文 context_manager.add_tao(thought, action, observation) print(f"步骤{step+1}:思维:{thought} | 行动:{action} | 观察:{observation}") # 超时终止 returnf"任务未完成(已达最大步数{max_steps})", context_manager.get_context_str() # 调用示例 if __name__ == "__main__": # 初始化工具 tools = [FlightSearchTool(), FlightBookTool()] # 定义任务 task = "查询明天从深圳到海南的航班,选最便宜、航班时间在晚上的那班并预订" # 运行ReAct循环 final_result, trajectory = react_core_loop(task, tools) # 输出结果 print("\n最终结果:", final_result) print("\n完整执行轨迹:", trajectory) ``` </div> </div> </div> #### 2. Plan and Execute(计划与执行):先谋后动的分层协作 <div class="tab-container post_tab box-shadow-wrap-lg"> <ul class="nav no-padder b-b scroll-hide" role="tablist"> <li class='nav-item active' role="presentation"><a class='nav-link active' style="" data-toggle="tab" aria-controls='tabs-cf5a313866a732b0f083b9ba5ad2f302420' role="tab" data-target='#tabs-cf5a313866a732b0f083b9ba5ad2f302420'>核心机制</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-409aabbb5c92705a6349918087f81b7b01' role="tab" data-target='#tabs-409aabbb5c92705a6349918087f81b7b01'>适用场景</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-f5fc148fada61b5d8cec760040b7f1cd402' role="tab" data-target='#tabs-f5fc148fada61b5d8cec760040b7f1cd402'>提出背景</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-99c81bbb2546127d7aeebab0b75c9bd7123' role="tab" data-target='#tabs-99c81bbb2546127d7aeebab0b75c9bd7123'>框架映射</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-5ec5cd89fd7f20c4f1a931465e4767b7894' role="tab" data-target='#tabs-5ec5cd89fd7f20c4f1a931465e4767b7894'>代码示例</a></li> </ul> <div class="tab-content no-border"> <div role="tabpanel" id='tabs-cf5a313866a732b0f083b9ba5ad2f302420' class="tab-pane fade active in"> `分阶段`处理任务 —— 规划阶段生成包含子任务的详细`计划`(如项目开发的需求分析、后端开发、测试部署三阶段),`执行`阶段按序完成每个子任务并整合结果。</div><div role="tabpanel" id='tabs-409aabbb5c92705a6349918087f81b7b01' class="tab-pane fade "> 复杂多步骤任务(软件开发、科研分析),例如解决 “设计一个电商用户认证系统” 时,规划器先拆解为 “数据库模型设计”“API 接口开发”“前端组件实现”,执行器再逐一落地。</div><div role="tabpanel" id='tabs-f5fc148fada61b5d8cec760040b7f1cd402' class="tab-pane fade "> 出现在 2023年前后的 Agent应用开发框架实践(如 LangChain 社区)</div><div role="tabpanel" id='tabs-99c81bbb2546127d7aeebab0b75c9bd7123' class="tab-pane fade "> Dify 的 “Workflow Orchestration” 支持可视化规划编排,结合人机协同节点实现动态调整。</div><div role="tabpanel" id='tabs-5ec5cd89fd7f20c4f1a931465e4767b7894' class="tab-pane fade "> **代码示例(LangChain Plan-Execute 实现)** ``` from langchain_openai import ChatOpenAI from langchain.chains import LLMChain from langchain.prompts import PromptTemplate # 初始化LLM llm = ChatOpenAI(model="gpt-4-turbo", temperature=0.3) # 1. 规划器:拆解任务为子步骤 planner_prompt = PromptTemplate( input_variables=["task"], template="""将以下复杂任务拆解为3-5个可执行的子任务,按顺序排列: 任务:{task} 子任务列表(编号+描述):""" ) planner_chain = LLMChain(llm=llm, prompt=planner_prompt, output_key="sub_tasks") # 2. 执行器:完成单个子任务 executor_prompt = PromptTemplate( input_variables=["sub_task"], template="""完成以下子任务,输出具体执行结果: 子任务:{sub_task} 执行结果:""" ) executor_chain = LLMChain(llm=llm, prompt=executor_prompt, output_key="result") # 3. 整合器:合并所有子任务结果 integrator_prompt = PromptTemplate( input_variables=["task", "all_results"], template="""根据以下子任务执行结果,整合为完整的任务解决方案: 原始任务:{task} 子任务执行结果: {all_results} 完整解决方案:""" ) integrator_chain = LLMChain(llm=llm, prompt=integrator_prompt, output_key="final_result") # 执行流程 def plan_and_execute(task): # 生成计划 plan = planner_chain.run(task) print("任务分解:\n", plan) # 执行每个子任务 sub_tasks = [line.strip() for line in plan.split("\n") if line.strip().startswith(("1.", "2.", "3.", "4.", "5."))] all_results = [] for i, sub_task in enumerate(sub_tasks, 1): result = executor_chain.run(sub_task) all_results.append(f"子任务{i}:{sub_task}\n结果:{result}") print(f"\n子任务{i}执行完成:\n", result) # 整合结果 final_result = integrator_chain.run(task=task, all_results="\n\n".join(all_results)) return final_result # 运行示例 final = plan_and_execute("设计一个电商用户认证系统") print("\n最终解决方案:\n", final) ``` **输出效果**: ``` 任务分解: 1. 设计用户数据库模型(包含用户名、密码哈希、手机号、邮箱等字段) 2. 实现手机号+验证码登录接口 3. 实现密码重置功能(通过邮箱验证) 4. 设计用户权限分级机制(普通用户/管理员) 5. 增加登录异常检测(异地登录提醒、多次失败锁定) 子任务1执行完成: 数据库模型采用MySQL,用户表(user)字段设计: - id: INT(11) 主键自增 - username: VARCHAR(50) 唯一用户名 - password_hash: VARCHAR(255) bcrypt加密存储 - phone: VARCHAR(20) 唯一手机号 - email: VARCHAR(100) 唯一邮箱 - role: ENUM('user', 'admin') 角色标识 - created_at: DATETIME 创建时间 - updated_at: DATETIME 更新时间 ...(其他子任务执行结果) 最终解决方案: 电商用户认证系统设计方案如下: 一、数据库设计(子任务1结果) ... 二、核心功能实现(子任务2-5结果) ... ``` </div> </div> </div> ### (三)立体探索范式:从单一路径到多维搜索 #### 1. Tree of Thoughts(ToT,树状思维):分支探索的最优路径筛选 <div class="tab-container post_tab box-shadow-wrap-lg"> <ul class="nav no-padder b-b scroll-hide" role="tablist"> <li class='nav-item active' role="presentation"><a class='nav-link active' style="" data-toggle="tab" aria-controls='tabs-d478aef99e85437a4ed8cfd181fc754a260' role="tab" data-target='#tabs-d478aef99e85437a4ed8cfd181fc754a260'>核心机制</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-5334281ebb5f8f30ab5e72c86be74199121' role="tab" data-target='#tabs-5334281ebb5f8f30ab5e72c86be74199121'>适用场景</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-ed46141e3fc26a047d34403c0e53625e522' role="tab" data-target='#tabs-ed46141e3fc26a047d34403c0e53625e522'>提出背景</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-620026259fb5f95192c0141d62b28d4d993' role="tab" data-target='#tabs-620026259fb5f95192c0141d62b28d4d993'>框架映射</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-f38eb649687535bf6b41425f7c1ff1a4624' role="tab" data-target='#tabs-f38eb649687535bf6b41425f7c1ff1a4624'>代码示例</a></li> </ul> <div class="tab-content no-border"> <div role="tabpanel" id='tabs-d478aef99e85437a4ed8cfd181fc754a260' class="tab-pane fade active in"> 生成多个推理分支(如创意写作的不同情节走向、数学题的多种解法),通过自评估(如评分投票)选择最优路径继续探索,支持回溯修正(如发现分支矛盾时返回前序节点)。</div><div role="tabpanel" id='tabs-5334281ebb5f8f30ab5e72c86be74199121' class="tab-pane fade "> 需多可能性探索的任务(策略规划、创意生成),例如 “24 点游戏” 中,模型同时计算 “(6-2)×(3+3)” 和 “3×8×(2-1)” 等多条路径,评估后选择有效解。</div><div role="tabpanel" id='tabs-ed46141e3fc26a047d34403c0e53625e522' class="tab-pane fade "> Princeton 和 DeepMind 在2023年的论文《Tree of Thoughts: Deliberate problem Solving with Large Language Models》。</div><div role="tabpanel" id='tabs-620026259fb5f95192c0141d62b28d4d993' class="tab-pane fade "> 实验性框架如 “ToT-Hub” 提供树状结构管理工具,支持深度优先 / 广度优先搜索策略。</div><div role="tabpanel" id='tabs-f38eb649687535bf6b41425f7c1ff1a4624' class="tab-pane fade "> **代码示例(简化版 ToT 实现 24 点游戏)** ``` from langchain_openai import ChatOpenAI import itertools llm = ChatOpenAI(model="gpt-4-turbo", temperature=0.5) def generate_branches(numbers): """生成所有可能的运算分支""" branches = [] # 生成所有数字排列 for nums in itertools.permutations(numbers, 2): # 生成所有运算符组合 for op in ["+", "-", "*", "/"]: if op == "/" and nums[1] == 0: continue # 避免除零 # 计算中间结果 try: result = eval(f"{nums[0]}{op}{nums[1]}") remaining = [n for n in numbers if n not in nums] + [result] branches.append({ "step": f"{nums[0]}{op}{nums[1]}={result}", "remaining": remaining, "path": [f"{nums[0]}{op}{nums[1]}"] }) except: continue return branches def evaluate_branch(branch): """评估分支是否接近24点""" score = 0 for num in branch["remaining"]: if 20 <= num <= 28: score += 5 # 接近24加分 elif 10 <= num <= 35: score += 3 return score def tot_24_game(numbers): """Tree of Thoughts求解24点""" current_branches = generate_branches(numbers) for _ in range(2): # 最多探索2层 # 评估并筛选前3个最优分支 current_branches = sorted(current_branches, key=evaluate_branch, reverse=True)[:3] next_branches = [] for branch in current_branches: if len(branch["remaining"]) == 1: # 只剩一个数字,检查是否为24 if abs(branch["remaining"][0] - 24) < 1e-6: return " → ".join(branch["path"]) + "=24" continue # 继续生成下一层分支 new_branches = generate_branches(branch["remaining"]) for new_branch in new_branches: new_branch["path"] = branch["path"] + [new_branch["step"].split("=")[0]] next_branches.append(new_branch) current_branches = next_branches # 若未找到精确解,返回最优尝试 best_branch = max(current_branches, key=evaluate_branch) return " → ".join(best_branch["path"]) + f"={best_branch['remaining'][0]}(接近24)" # 运行示例 result = tot_24_game([3, 6, 2, 8]) print("24点解法:", result) ``` **输出效果**: ``` 24点解法: 3+6 → 9×2 → 18+8=26(接近24) # 或找到精确解时输出:6-2 →4×3 →12×2=24 ``` </div> </div> </div> #### 2. Reflexion / Iterative Refinement(反思与迭代优化):自我批判的持续进化 <div class="tab-container post_tab box-shadow-wrap-lg"> <ul class="nav no-padder b-b scroll-hide" role="tablist"> <li class='nav-item active' role="presentation"><a class='nav-link active' style="" data-toggle="tab" aria-controls='tabs-47c47c93f973c54af20301ba3d126b78480' role="tab" data-target='#tabs-47c47c93f973c54af20301ba3d126b78480'>核心机制</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-c76cb0f44c7b3b8940ac65e8f1d7328f41' role="tab" data-target='#tabs-c76cb0f44c7b3b8940ac65e8f1d7328f41'>适用场景</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-f63159e16b36268fd9cf1a3b23566b65762' role="tab" data-target='#tabs-f63159e16b36268fd9cf1a3b23566b65762'>提出背景</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-a1485f3d0e39fc1a099d6985c478bf02953' role="tab" data-target='#tabs-a1485f3d0e39fc1a099d6985c478bf02953'>框架映射</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-ff67cac6bab9fb8c79ccd3d515627f36514' role="tab" data-target='#tabs-ff67cac6bab9fb8c79ccd3d515627f36514'>代码示例</a></li> </ul> <div class="tab-content no-border"> <div role="tabpanel" id='tabs-47c47c93f973c54af20301ba3d126b78480' class="tab-pane fade active in"> 生成初步答案后,通过自我评估(如检查逻辑漏洞、事实准确性)触发迭代优化(如代码生成后自动检测语法错误并修正)。</div><div role="tabpanel" id='tabs-c76cb0f44c7b3b8940ac65e8f1d7328f41' class="tab-pane fade "> 让 Agent 写一段 Python 代码,如果第一次运行报错,它会读报错信息,反思“函数参数写错了”,然后自动修正并重试。适合代码生成、流程执行类场景。</div><div role="tabpanel" id='tabs-f63159e16b36268fd9cf1a3b23566b65762' class="tab-pane fade "> 2023年论文 《Reflexion: Language Agents with Verbal ReinforcementLearning》。</div><div role="tabpanel" id='tabs-a1485f3d0e39fc1a099d6985c478bf02953' class="tab-pane fade "> LlamaIndex 的 “CritiqueEngine” 结合外部知识库,实现对输出的多维度验证。</div><div role="tabpanel" id='tabs-ff67cac6bab9fb8c79ccd3d515627f36514' class="tab-pane fade "> **代码示例(Reflexion 迭代优化代码生成)** ``` from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate class ReflexionAgent: def __init__(self, model="gpt-4-turbo", max_attempts=3): self.llm = ChatOpenAI(model=model, temperature=0) self.max_attempts = max_attempts self.reflections = [] # 反思日志 def _executor(self, task): """执行任务生成初始结果""" prompt = ChatPromptTemplate.from_messages([ ("system", "你是Python开发专家,生成简洁可运行的代码"), ("user", f"任务:{task}\n之前的反思:{self.reflections[-1] if self.reflections else '无'}") ]) return prompt | self.llm def _reflector(self, task, output, error=None): """反思失败原因""" prompt = ChatPromptTemplate.from_messages([ ("system", "分析代码问题,仅输出具体改进点(1-2条)"), ("user", f"任务:{task}\n生成的代码:{output}\n错误信息:{error or '无'}") ]) reflection = (prompt | self.llm).invoke({}).content self.reflections.append(reflection) return reflection def run(self, task): for attempt in range(self.max_attempts): print(f"\n=== 第{attempt+1}次尝试 ===") # 生成代码 chain = self._executor(task) output = chain.invoke({}).content print("生成的代码:\n", output) # 尝试运行代码(模拟执行) try: exec(output) # 实际场景需在沙箱中执行 print("代码执行成功!") return output except Exception as e: error_msg = str(e)[:100] print(f"执行失败:{error_msg}") # 反思并优化 reflection = self._reflector(task, output, error_msg) print("反思改进:", reflection) return f"经过{self.max_attempts}次优化仍未成功,最终代码:\n{output}" # 运行示例 agent = ReflexionAgent(max_attempts=2) result = agent.run("编写Python函数,计算列表中所有偶数的平方和") print("\n最终结果:\n", result) ``` **输出效果**: ``` === 第1次尝试 === 生成的代码: def sum_even_squares(lst): total = 0 for num in lst: if num % 2 == 0: total += num^2 return total 执行失败:unsupported operand type(s) for ^: 'int' and 'int' 反思改进:1. Python中平方运算符是**而非^,^是按位异或;2. 需添加参数类型检查 === 第2次尝试 === 生成的代码: def sum_even_squares(lst): total = 0 for num in lst: if isinstance(num, int) and num % 2 == 0: total += num **2 return total 代码执行成功! 最终结果: def sum_even_squares(lst): total = 0 for num in lst: if isinstance(num, int) and num % 2 == 0: total += num **2 return total ``` </div> </div> </div> (四)协作分工范式:从个体智能到群体协同 #### Role-playing Agents(角色扮演式智能体):多主体协作的分工进化 <div class="tab-container post_tab box-shadow-wrap-lg"> <ul class="nav no-padder b-b scroll-hide" role="tablist"> <li class='nav-item active' role="presentation"><a class='nav-link active' style="" data-toggle="tab" aria-controls='tabs-19003aafa6d6a7daf6ed63a009f6640c750' role="tab" data-target='#tabs-19003aafa6d6a7daf6ed63a009f6640c750'>核心机制</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-dfed268539cb06ea36a17e17a9139ea6341' role="tab" data-target='#tabs-dfed268539cb06ea36a17e17a9139ea6341'>适用场景</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-02fbf75501cc4e4d2da4d527695502e3902' role="tab" data-target='#tabs-02fbf75501cc4e4d2da4d527695502e3902'>提出背景</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-68fc6561f6e9ebeb583a335d4c04da17113' role="tab" data-target='#tabs-68fc6561f6e9ebeb583a335d4c04da17113'>框架映射</a></li><li class='nav-item ' role="presentation"><a class='nav-link ' style="" data-toggle="tab" aria-controls='tabs-c4e9faf069695e915494a7c2494e379b464' role="tab" data-target='#tabs-c4e9faf069695e915494a7c2494e379b464'>代码示例</a></li> </ul> <div class="tab-content no-border"> <div role="tabpanel" id='tabs-19003aafa6d6a7daf6ed63a009f6640c750' class="tab-pane fade active in"> 通过定义不同角色(如 “决策者”“执行者”“审查者”),模拟人类团队分工(如项目管理中,策划 Agent 制定方案,开发 Agent 实现功能,测试 Agent 验证效果)。</div><div role="tabpanel" id='tabs-dfed268539cb06ea36a17e17a9139ea6341' class="tab-pane fade "> 场景例子:一个软件开发任务里,有产品经理 Agent 写需求文档,程序员 Agent 写代码,测试 Agent写测试用例。它们像团队一样协作。适合复杂系统开发或跨职能协同。</div><div role="tabpanel" id='tabs-02fbf75501cc4e4d2da4d527695502e3902' class="tab-pane fade "> 源自 AutoGPT、ChatDev、CAMEL 等社区项目。</div><div role="tabpanel" id='tabs-68fc6561f6e9ebeb583a335d4c04da17113' class="tab-pane fade "> Dify 的 “Multi-Agent Orchestration” 支持角色间状态共享与消息传递,实现流程化协作。</div><div role="tabpanel" id='tabs-c4e9faf069695e915494a7c2494e379b464' class="tab-pane fade "> **代码示例(AutoGen 多智能体协作)** ``` import autogen from autogen import AssistantAgent, UserProxyAgent # 配置LLM config_list = [ { "model": "gpt-4-turbo", "api_key": os.environ["OPENAI_API_KEY"], } ] # 定义角色Agent product_manager = AssistantAgent( name="产品经理", system_message="""你负责需求分析和方案设计,明确电商网站的核心功能模块, 输出详细的需求文档(包含用户故事、功能清单、优先级)""", llm_config={"config_list": config_list} ) developer = AssistantAgent( name="开发者", system_message="""你负责技术实现,根据需求文档设计技术架构, 输出后端API设计和数据库模型(使用Python+MySQL技术栈)""", llm_config={"config_list": config_list} ) tester = AssistantAgent( name="测试工程师", system_message="""你负责测试用例设计,根据需求文档和技术方案, 输出功能测试用例和接口测试用例(包含输入、预期输出、优先级)""", llm_config={"config_list": config_list} ) # 定义用户代理(协调者) user_proxy = UserProxyAgent( name="用户", system_message="协调产品、开发、测试团队完成电商网站需求落地", human_input_mode="NEVER", # 无需人工干预 max_consecutive_auto_reply=10 ) # 定义协作流程 groupchat = autogen.GroupChat( agents=[user_proxy, product_manager, developer, tester], messages=[], max_round=10, speaker_selection_method="auto" # 自动选择发言者 ) manager = autogen.GroupChatManager( groupchat=groupchat, llm_config={"config_list": config_list} ) # 启动协作 user_proxy.initiate_chat( manager, message="请团队协作完成小型电商网站的需求设计、技术实现和测试方案" ) ``` **输出效果**: ``` 用户:请团队协作完成小型电商网站的需求设计、技术实现和测试方案 产品经理: # 电商网站需求文档 ## 核心功能模块 1. 商品管理(上架、编辑、分类)- 优先级P0 2. 用户管理(注册、登录、个人中心)- P0 3. 购物车(添加、修改、删除)- P1 ... 开发者: # 技术方案设计 ## 后端架构 - 框架:FastAPI - 数据库:MySQL 8.0 ## API设计 1. 商品接口:GET /api/products(列表)、POST /api/products(创建) ... ## 数据库模型 商品表(products):id, name, price, category_id, stock... 测试工程师: # 测试用例设计 ## 商品管理功能测试 | 用例ID | 输入 | 预期输出 | 优先级 | |--------|------|----------|--------| | TC001 | 上架名称为空的商品 | 返回400错误 | P0 | ... ## 接口测试用例 GET /api/products: - 输入:?page=1&size=10 - 预期:返回200,包含商品列表和分页信息 ``` </div> </div> </div> ## 三、框架选择的 “生态法则”:定位决定生存 不同框架的设计哲学,本质是对 “工具依赖度”“推理透明度”“探索深度” 的差异化取舍: * **工具驱动型**(如 ReAct、函数调用):依赖外部 API / 数据库,适合实时数据任务(如金融行情分析); * **推理解释型**(如 CoT、Self-Ask):侧重过程显化,适合教育、客服等需用户信任的场景; * **探索优化型**(如 ToT、Reflexion):聚焦多路径搜索与迭代,适合创意生成、复杂决策。 正如没有 “万能钥匙”,Agent 框架的价值在于 “精准定位”——LangChain 凭借链式推理的灵活性成为通用首选,LlamaIndex 以知识检索优势扎根垂直领域,Dify 则通过人机混合编排抢占协作场景。只要能清晰回答 “解决什么问题、服务哪类用户、如何差异化赋能”,每个框架都能在 Agent 生态中找到属于自己的 “生存空间”。 ## 四、结语:在多样性中寻找平衡 Agent 设计模式的 “百花齐放”,既是 LLM 能力边界的自然延伸,也是复杂场景的必然要求。从线性推理到树状探索,从单 Agent 执行到多角色协作,每个框架都是对 “智能体该如何思考” 的独特解答。对于开发者而言,关键不是追逐 “最优框架”,而是理解每种模式的思维内核 —— 当链状推理需要工具加持时选择 ReAct,当多步规划需要人机协同时有 Dify,当知识检索需要深度整合时用 LlamaIndex。 最后修改:2026 年 01 月 09 日 © 允许规范转载 赞 1 如果觉得我的文章对你有用,请随意赞赏
2 条评论
咳,agent不好控制稳定
稳定可控和智能体自动化程度成反比