Transformer 是一种神经网络架构。Transformer 最初在2017年的论文《Attention is All You Need》中被提出,并迅速成为深度学习模型的首选架构,广泛应用于文本生成、音频生成、图像识别、蛋白质结构预测等多个领域。 > 核心组件:每个基于Transformer的文本生成模型主要由以下三个关键部分组成 > > 1.**Embedding(嵌入层)** > > 2.**Transformer Block(Transformer块)** > > * **Attention Mechanism** > * **MLP (Multilayer Perceptron) Layer** > > 3.**Output Probabilities(输出概率)** 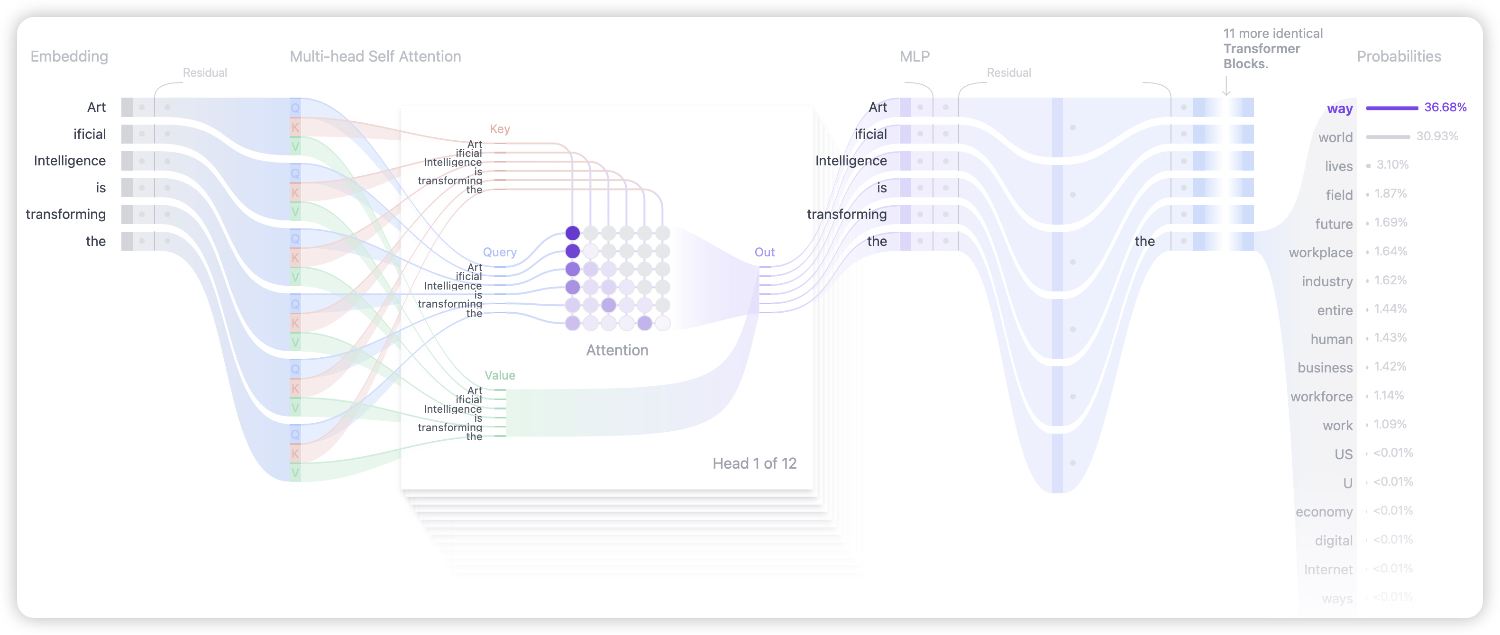 ## Embedding(嵌入层)  **步骤1:Tokenization(分词):** 输入文本被分解成更小的单元,称为tokens(可以是单词或子词)。例如,输入`"Data visualization empowers users to"` 可能会被分解为`["Data", "visual", "##ization", "empowers", "users", "to"]`。GPT-2 的词汇表包含50,257个唯一的tokens。 **步骤2:Token Embedding(token嵌入):**每个token被映射到一个高维向量空间中,这个向量捕捉了token的语义信息。例如,GPT-2 Small 模型使用768维的向量来表示每个token。这些嵌入向量存储在一个形状为`(vocab_size:词汇表大小, hidden_size:隐藏层维度)` 的矩阵中。 **步骤3:Positional Encoding(位置编码):**为了捕捉序列中的位置信息,每个token还会附加一个位置编码。位置编码可以是固定的(如正弦/余弦函数)或可训练的(如GPT-2中直接训练的位置编码)。位置编码确保模型能够区分相同token在不同位置的不同含义。 **步骤4:Final Embedding(最终嵌入):**将token嵌入和位置编码相加,得到最终的嵌入表示。这一步使得模型不仅能够理解token的语义,还能理解它们在序列中的相对位置。 ## Transformer Block(Transformer块) Transformer Block是Transformer架构的核心组件,通常由多个相同的块堆叠而成。每个块包括两个主要部分: **Multi-Head Self-Attention(多头自注意力机制)** **MLP(多层感知机)** ### Multi-Head Self-Attention(多头自注意力机制) Self-Attention使模型可以关注输入的相关部分,能够捕获数据中的复杂关系和依赖关系。 #### **步骤1:Query, Key, and Value Matrices(QKV矩阵)**  每个token的嵌入向量通过线性变换转换为三个向量:Query (Q)、Key (K) 和 Value (V)。这些向量用于计算注意力分数,确定每个token与其他token的相关性。 * Query (Q) :搜索引擎栏中键入的搜索文本。这是您想要“查找更多信息”的令牌。 * Key (K) :搜索结果窗口中每个网页的标题。它代表了查询可以满足的可能标记。 * Value (V) :显示的网页的实际内容。将适当的搜索词(Query)与相关结果(Key)匹配,获得最相关页面的内容(Value)。 #### **步骤2:Masked Self-Attention(掩码自注意力)** 在生成任务中,为了防止模型“窥探”未来的信息,会应用掩码。具体来说,上三角矩阵的值被设置为负无穷大,使得模型只能关注当前及之前的token。  **Attention Score**:Query和Key矩阵的点积决定了每个查询与每个密钥的对齐,生成一个反映所有输入令牌之间关系的方形矩阵。 **Masking:**将屏蔽应用于注意力矩阵的上三角形,以防止模型访问未来令牌,将这些值设置为负无穷大。该模型需要学习如何在不“窥视”未来的情况下预测下一个token。 **Softmax:**屏蔽后,注意力得分通过softmax操作转换为概率,该操作取每个注意力分数的指数。矩阵的每一行总和为一,并表示其左侧所有其他令牌的相关性。 #### **步骤3:Attention Output(注意力输出)**  计算注意力分数后,通过softmax函数将其转换为概率分布,然后与Value矩阵相乘,得到最终的注意力输出。GPT-2 使用12个自注意力头,每个头捕捉不同的token间关系。这些头的输出被拼接在一起并通过一个线性投影层。 ### MLP(多层感知机)  经过多头自注意力机制处理后的token表示被传递给MLP层,以进一步增强其表达能力。MLP层通常包括两层线性变换,中间夹着一个激活函数(如GELU)。第一层将输入维度扩展四倍,第二层再将其压缩回原始维度。 ## Output Probabilities(输出概率) 经过所有Transformer块处理后的输出被传递给最终的线性层,该层将表示投影到词汇表大小的空间中,生成logits。通过softmax函数将logits转换为概率分布,任何令牌都可以是下一个单词,因此这个过程允许我们简单地根据它们成为下一个单词的可能性对这些令牌进行排名。从而预测下一个最有可能出现的token。 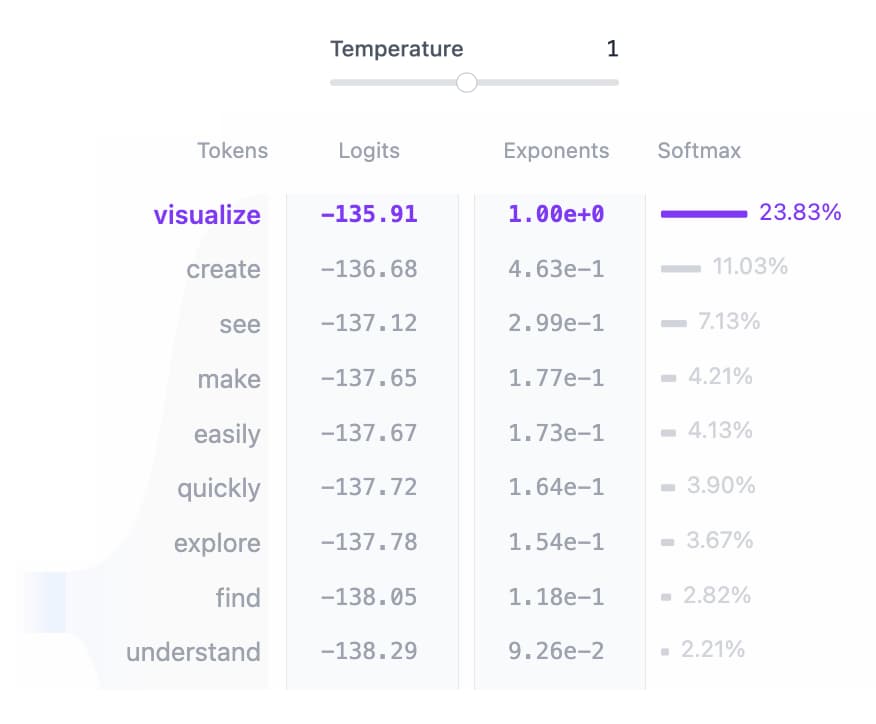 词汇中的每个令牌都根据模型的输出对数分配一个概率。这些概率决定了每个令牌成为序列中下一个单词的可能性。 ## Transformer组成  ### BERT BERT是一种基于Transformer的预训练语言模型,引入了双向Transformer编码器,这使得模型可以同时考虑输入序列的前后上下文信息。 > 1. 输入层(Embedding): > * Token Embeddings:将单词或子词转换为固定维度的向量。 > * Segment Embeddings:用于区分句子对中的不同句子。 > * Position Embeddings:由于Transformer模型本身不具备处理序列顺序的能力,所以需要加入位置嵌入来提供序列中单词的位置信息。 > 2. 编码层(Transformer Encoder):BERT模型使用双向Transformer编码器进行编码。 > 3. 输出层(Pre-trained Task-specific Layers): > * MLM输出层:用于预测被掩码(masked)的单词。在训练阶段,模型会随机遮盖输入序列中的部分单词,并尝试根据上下文预测这些单词。 > * NSP输出层:用于判断两个句子是否为连续的句子对。在训练阶段,模型会接收成对的句子作为输入,并尝试预测第二个句子是否是第一个句子的后续句子。 以下是bert-base-chinese模型信息: ```nestedtext # 加载预训练模型 import torch from transformers import BertModel DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") pretrained = BertModel.from_pretrained("/Volumes/Date/huggingface/model/bert-base-chinese/models--bert-base-chinese/snapshots/c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f").to(DEVICE) print(pretrained) """ BertModel( (embeddings): BertEmbeddings( # 编码层(词向量化):文本位置编码编码为词向量 (word_embeddings): Embedding(21128, 768, padding_idx=0) (position_embeddings): Embedding(512, 768) (token_type_embeddings): Embedding(2, 768) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) (encoder): BertEncoder( # 特征提取 (layer): ModuleList( (0-11): 12 x BertLayer( # 12层 (attention): BertAttention( (self): BertSdpaSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) (intermediate_act_fn): GELUActivation() ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) ) ) (pooler): BertPooler( # 输出层 (dense): Linear(in_features=768, out_features=768, bias=True) #输出728特征 (activation): Tanh() ) ) """ ``` * Embeddings 层(词向量化) * Word Embeddings: 将输入文本中的每个单词映射为一个固定维度的向量(例如768维)。这是通过查找预训练的嵌入矩阵来实现的。 * Position Embeddings: 由于BERT是双向的,它需要位置信息来理解句子中单词的顺序。位置嵌入为每个单词添加了其在句子中的位置信息。 * Token Type Embeddings: 用于区分不同句子(例如在句子对任务中),以便模型知道哪些标记属于哪个句子。 * LayerNorm: 对嵌入进行归一化处理,以确保数值稳定。 * Dropout: 随机丢弃一部分神经元,防止过拟合。 * Encoder 层(特征提取) * BertEncoder: 包含多个 BertLayer,每个 BertLayer 又包含两个子模块:\`Attention\` 和 Feed-Forward Network。 * Attention: * Self-Attention: 计算输入序列中每个单词与其他单词之间的关系。这使得模型可以关注到上下文中的相关信息。 * Output: 对自注意力的结果进行线性变换,并应用归一化和dropout。 * Intermediate: * Linear: 扩展维度(例如从768维扩展到3072维),并应用激活函数(如GELU)。 * Output: * Linear: 缩小维度(例如从3072维缩小回768维),并应用归一化和dropout。 * **Pooler 层(输出层)** * **BertPooler**: 用于生成一个固定长度的向量表示整个输入序列。通常取** **`[CLS]` 标记对应的隐藏状态,并通过线性变换和激活函数(如Tanh)得到最终表示。 ### GPT GPT也是一种基于Transformer的预训练语言模型,使用了单向Transformer编码器,这使得模型可以更好地捕捉输入序列的上下文信息。** ** > 1. 输入层(Input Embedding): > * 将输入的单词或符号转换为固定维度的向量表示。 > * 可以包括词嵌入、位置嵌入等,以提供单词的语义信息和位置信息。 > 2. 编码层(Transformer Encoder):GPT模型使用单向Transformer编码器进行编码和生成。 > 3. 输出层(Output Linear and Softmax): > * 线性输出层将最后一个Transformer Decoder Block的输出转换为词汇表大小的向量。 > * Softmax函数将输出向量转换为概率分布,以便进行词汇选择或生成下一个单词。 以下是GPT-2模型信息: ```routeros from transformers import BertTokenizer,GPT2LMHeadModel,TextGenerationPipeline tokenizer = BertTokenizer.from_pretrained(r"/Volumes/Date/huggingface/model/gpt2-chinese/models--uer--gpt2-chinese-cluecorpussmall/snapshots/c2c0249d8a2731f269414cc3b22dff021f8e07a3") model = GPT2LMHeadModel.from_pretrained(r"/Volumes/Date/huggingface/model/gpt2-chinese/models--uer--gpt2-chinese-cluecorpussmall/snapshots/c2c0249d8a2731f269414cc3b22dff021f8e07a3") print(model) “”“ GPT2LMHeadModel( (transformer): GPT2Model( (wte): Embedding(21128, 768) (wpe): Embedding(1024, 768) (drop): Dropout(p=0.1, inplace=False) (h): ModuleList( (0-11): 12 x GPT2Block( (ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True) (attn): GPT2SdpaAttention( (c_attn): Conv1D(nf=2304, nx=768) (c_proj): Conv1D(nf=768, nx=768) (attn_dropout): Dropout(p=0.1, inplace=False) (resid_dropout): Dropout(p=0.1, inplace=False) ) (ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True) (mlp): GPT2MLP( (c_fc): Conv1D(nf=3072, nx=768) (c_proj): Conv1D(nf=768, nx=3072) (act): NewGELUActivation() (dropout): Dropout(p=0.1, inplace=False) ) ) ) (ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True) ) (lm_head): Linear(in_features=768, out_features=21128, bias=False) ) ”“” ``` #### 模型输入数据信息 * **输入文本**:输入文本需要先通过分词器(如** **`BertTokenizer`)进行编码,转换为模型可以理解的格式。具体来说,输入文本会被分割成一个个token(词汇或字符),并映射到模型的词汇表中对应的ID。 * 输入张量 * **input\_ids**:这是一个二维张量,形状为** **`[batch_size, sequence_length]`,其中** **`batch_size` 是批次大小,\`sequence\_length\` 是序列长度。每个元素是词汇表中的token ID。 **attention\_mask**(可选):用于指示哪些位置是有效的token(值为1),哪些位置是填充的(值为0)。形状为** **`[batch_size, sequence_length]`。 **position\_ids**(可选):用于指示每个token在序列中的位置。形状为** **`[batch_size, sequence_length]`。 **token\_type\_ids**(可选):用于区分不同类型的token(例如,在句子对任务中区分两个句子)。形状为** **`[batch_size, sequence_length]`。 #### 模型输出数据信息 * 输出张量 * **logits**:这是模型生成的每个位置上所有可能token的概率分布。形状为** **`[batch_size, sequence_length, vocab_size]`,其中** **`vocab_size` 是词汇表的大小(21128)。每个位置上的概率分布可以通过softmax函数转换为概率值。 * **past\_key\_values**(可选):用于加速推理过程中的自回归生成。包含之前计算的注意力键和值,可以在生成下一个token时复用。 #### 模型结构 * **Embedding层** * **wte (word embeddings)**:将输入的token ID嵌入到768维的向量空间中。形状为** **`[vocab_size, hidden_size]`,其中** **`hidden_size=768`。 * **wpe (position embeddings)**:将每个token的位置信息嵌入到768维的向量空间中。形状为`[max_position_embeddings, hidden_size]`,其中** `max_position_embeddings=1024`。 * **Dropout层:**在嵌入层之后应用一个dropout层,以防止过拟合。dropout概率为0.1。 * **Transformer层:**包含12个`GPT2Block`,每个块由以下部分组成: * **LayerNorm (ln\_1)**:在多头自注意力机制之前应用层归一化。 * **Attention (attn)**:多头自注意力机制,用于捕捉输入序列中的依赖关系。包括三个子模块: * **c\_attn**:线性变换,将输入映射到查询、键和值的组合空间。 * **c\_proj**:线性变换,将注意力结果映射回隐藏状态空间。 * **attn\_dropout** 和**resid\_dropout**:分别应用于注意力权重和残差连接的dropout层。 * **LayerNorm (ln\_2)**:在前馈神经网络之前应用层归一化。 * **MLP (mlp)**:两层全连接网络,激活函数为`NewGELUActivation`,并在最后一层应用dropout。 * **Final LayerNorm:**在所有Transformer层之后应用最终的层归一化。 * **Language Model Head (lm\_head):**线性变换,将隐藏状态映射回词汇表大小的空间。形状为`[hidden_size, vocab_size]`,没有偏置项。 #### 工作流程 1.**输入处理**:输入文本通过分词器编码为`input_ids`,并可能附加`attention_mask` 和`position_ids`。 2.**嵌入层**:将`input_ids` 和`position_ids` 转换为嵌入向量,并应用dropout。 3.**Transformer层**:嵌入向量依次通过12个`GPT2Block`,每个块内部进行多头自注意力计算和前馈神经网络变换。 4.**输出层**:最终的隐藏状态通过`lm_head` 线性变换,得到每个位置上所有可能token的概率分布。 5.**生成文本**:使用生成策略(如贪心搜索、束搜索或采样)从概率分布中选择最合适的token,逐步生成新的文本。 Loading... Transformer 是一种神经网络架构。Transformer 最初在2017年的论文《Attention is All You Need》中被提出,并迅速成为深度学习模型的首选架构,广泛应用于文本生成、音频生成、图像识别、蛋白质结构预测等多个领域。 > 核心组件:每个基于Transformer的文本生成模型主要由以下三个关键部分组成 > > 1.**Embedding(嵌入层)** > > 2.**Transformer Block(Transformer块)** > > * **Attention Mechanism** > * **MLP (Multilayer Perceptron) Layer** > > 3.**Output Probabilities(输出概率)**  ## Embedding(嵌入层)  **步骤1:Tokenization(分词):** 输入文本被分解成更小的单元,称为tokens(可以是单词或子词)。例如,输入`"Data visualization empowers users to"` 可能会被分解为`["Data", "visual", "##ization", "empowers", "users", "to"]`。GPT-2 的词汇表包含50,257个唯一的tokens。 **步骤2:Token Embedding(token嵌入):**每个token被映射到一个高维向量空间中,这个向量捕捉了token的语义信息。例如,GPT-2 Small 模型使用768维的向量来表示每个token。这些嵌入向量存储在一个形状为`(vocab_size:词汇表大小, hidden_size:隐藏层维度)` 的矩阵中。 **步骤3:Positional Encoding(位置编码):**为了捕捉序列中的位置信息,每个token还会附加一个位置编码。位置编码可以是固定的(如正弦/余弦函数)或可训练的(如GPT-2中直接训练的位置编码)。位置编码确保模型能够区分相同token在不同位置的不同含义。 **步骤4:Final Embedding(最终嵌入):**将token嵌入和位置编码相加,得到最终的嵌入表示。这一步使得模型不仅能够理解token的语义,还能理解它们在序列中的相对位置。 ## Transformer Block(Transformer块) Transformer Block是Transformer架构的核心组件,通常由多个相同的块堆叠而成。每个块包括两个主要部分: **Multi-Head Self-Attention(多头自注意力机制)** **MLP(多层感知机)** ### Multi-Head Self-Attention(多头自注意力机制) Self-Attention使模型可以关注输入的相关部分,能够捕获数据中的复杂关系和依赖关系。 #### **步骤1:Query, Key, and Value Matrices(QKV矩阵)**  每个token的嵌入向量通过线性变换转换为三个向量:Query (Q)、Key (K) 和 Value (V)。这些向量用于计算注意力分数,确定每个token与其他token的相关性。 * Query (Q) :搜索引擎栏中键入的搜索文本。这是您想要“查找更多信息”的令牌。 * Key (K) :搜索结果窗口中每个网页的标题。它代表了查询可以满足的可能标记。 * Value (V) :显示的网页的实际内容。将适当的搜索词(Query)与相关结果(Key)匹配,获得最相关页面的内容(Value)。 #### **步骤2:Masked Self-Attention(掩码自注意力)** 在生成任务中,为了防止模型“窥探”未来的信息,会应用掩码。具体来说,上三角矩阵的值被设置为负无穷大,使得模型只能关注当前及之前的token。  **Attention Score**:Query和Key矩阵的点积决定了每个查询与每个密钥的对齐,生成一个反映所有输入令牌之间关系的方形矩阵。 **Masking:**将屏蔽应用于注意力矩阵的上三角形,以防止模型访问未来令牌,将这些值设置为负无穷大。该模型需要学习如何在不“窥视”未来的情况下预测下一个token。 **Softmax:**屏蔽后,注意力得分通过softmax操作转换为概率,该操作取每个注意力分数的指数。矩阵的每一行总和为一,并表示其左侧所有其他令牌的相关性。 #### **步骤3:Attention Output(注意力输出)**  计算注意力分数后,通过softmax函数将其转换为概率分布,然后与Value矩阵相乘,得到最终的注意力输出。GPT-2 使用12个自注意力头,每个头捕捉不同的token间关系。这些头的输出被拼接在一起并通过一个线性投影层。 ### MLP(多层感知机)  经过多头自注意力机制处理后的token表示被传递给MLP层,以进一步增强其表达能力。MLP层通常包括两层线性变换,中间夹着一个激活函数(如GELU)。第一层将输入维度扩展四倍,第二层再将其压缩回原始维度。 ## Output Probabilities(输出概率) 经过所有Transformer块处理后的输出被传递给最终的线性层,该层将表示投影到词汇表大小的空间中,生成logits。通过softmax函数将logits转换为概率分布,任何令牌都可以是下一个单词,因此这个过程允许我们简单地根据它们成为下一个单词的可能性对这些令牌进行排名。从而预测下一个最有可能出现的token。  词汇中的每个令牌都根据模型的输出对数分配一个概率。这些概率决定了每个令牌成为序列中下一个单词的可能性。 ## Transformer组成  ### BERT BERT是一种基于Transformer的预训练语言模型,引入了双向Transformer编码器,这使得模型可以同时考虑输入序列的前后上下文信息。 > 1. 输入层(Embedding): > * Token Embeddings:将单词或子词转换为固定维度的向量。 > * Segment Embeddings:用于区分句子对中的不同句子。 > * Position Embeddings:由于Transformer模型本身不具备处理序列顺序的能力,所以需要加入位置嵌入来提供序列中单词的位置信息。 > 2. 编码层(Transformer Encoder):BERT模型使用双向Transformer编码器进行编码。 > 3. 输出层(Pre-trained Task-specific Layers): > * MLM输出层:用于预测被掩码(masked)的单词。在训练阶段,模型会随机遮盖输入序列中的部分单词,并尝试根据上下文预测这些单词。 > * NSP输出层:用于判断两个句子是否为连续的句子对。在训练阶段,模型会接收成对的句子作为输入,并尝试预测第二个句子是否是第一个句子的后续句子。 以下是bert-base-chinese模型信息: ```nestedtext # 加载预训练模型 import torch from transformers import BertModel DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") pretrained = BertModel.from_pretrained("/Volumes/Date/huggingface/model/bert-base-chinese/models--bert-base-chinese/snapshots/c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f").to(DEVICE) print(pretrained) """ BertModel( (embeddings): BertEmbeddings( # 编码层(词向量化):文本位置编码编码为词向量 (word_embeddings): Embedding(21128, 768, padding_idx=0) (position_embeddings): Embedding(512, 768) (token_type_embeddings): Embedding(2, 768) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) (encoder): BertEncoder( # 特征提取 (layer): ModuleList( (0-11): 12 x BertLayer( # 12层 (attention): BertAttention( (self): BertSdpaSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) (intermediate_act_fn): GELUActivation() ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) ) ) (pooler): BertPooler( # 输出层 (dense): Linear(in_features=768, out_features=768, bias=True) #输出728特征 (activation): Tanh() ) ) """ ``` * Embeddings 层(词向量化) * Word Embeddings: 将输入文本中的每个单词映射为一个固定维度的向量(例如768维)。这是通过查找预训练的嵌入矩阵来实现的。 * Position Embeddings: 由于BERT是双向的,它需要位置信息来理解句子中单词的顺序。位置嵌入为每个单词添加了其在句子中的位置信息。 * Token Type Embeddings: 用于区分不同句子(例如在句子对任务中),以便模型知道哪些标记属于哪个句子。 * LayerNorm: 对嵌入进行归一化处理,以确保数值稳定。 * Dropout: 随机丢弃一部分神经元,防止过拟合。 * Encoder 层(特征提取) * BertEncoder: 包含多个 BertLayer,每个 BertLayer 又包含两个子模块:\`Attention\` 和 Feed-Forward Network。 * Attention: * Self-Attention: 计算输入序列中每个单词与其他单词之间的关系。这使得模型可以关注到上下文中的相关信息。 * Output: 对自注意力的结果进行线性变换,并应用归一化和dropout。 * Intermediate: * Linear: 扩展维度(例如从768维扩展到3072维),并应用激活函数(如GELU)。 * Output: * Linear: 缩小维度(例如从3072维缩小回768维),并应用归一化和dropout。 * **Pooler 层(输出层)** * **BertPooler**: 用于生成一个固定长度的向量表示整个输入序列。通常取** **`[CLS]` 标记对应的隐藏状态,并通过线性变换和激活函数(如Tanh)得到最终表示。 ### GPT GPT也是一种基于Transformer的预训练语言模型,使用了单向Transformer编码器,这使得模型可以更好地捕捉输入序列的上下文信息。** ** > 1. 输入层(Input Embedding): > * 将输入的单词或符号转换为固定维度的向量表示。 > * 可以包括词嵌入、位置嵌入等,以提供单词的语义信息和位置信息。 > 2. 编码层(Transformer Encoder):GPT模型使用单向Transformer编码器进行编码和生成。 > 3. 输出层(Output Linear and Softmax): > * 线性输出层将最后一个Transformer Decoder Block的输出转换为词汇表大小的向量。 > * Softmax函数将输出向量转换为概率分布,以便进行词汇选择或生成下一个单词。 以下是GPT-2模型信息: ```routeros from transformers import BertTokenizer,GPT2LMHeadModel,TextGenerationPipeline tokenizer = BertTokenizer.from_pretrained(r"/Volumes/Date/huggingface/model/gpt2-chinese/models--uer--gpt2-chinese-cluecorpussmall/snapshots/c2c0249d8a2731f269414cc3b22dff021f8e07a3") model = GPT2LMHeadModel.from_pretrained(r"/Volumes/Date/huggingface/model/gpt2-chinese/models--uer--gpt2-chinese-cluecorpussmall/snapshots/c2c0249d8a2731f269414cc3b22dff021f8e07a3") print(model) “”“ GPT2LMHeadModel( (transformer): GPT2Model( (wte): Embedding(21128, 768) (wpe): Embedding(1024, 768) (drop): Dropout(p=0.1, inplace=False) (h): ModuleList( (0-11): 12 x GPT2Block( (ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True) (attn): GPT2SdpaAttention( (c_attn): Conv1D(nf=2304, nx=768) (c_proj): Conv1D(nf=768, nx=768) (attn_dropout): Dropout(p=0.1, inplace=False) (resid_dropout): Dropout(p=0.1, inplace=False) ) (ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True) (mlp): GPT2MLP( (c_fc): Conv1D(nf=3072, nx=768) (c_proj): Conv1D(nf=768, nx=3072) (act): NewGELUActivation() (dropout): Dropout(p=0.1, inplace=False) ) ) ) (ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True) ) (lm_head): Linear(in_features=768, out_features=21128, bias=False) ) ”“” ``` #### 模型输入数据信息 * **输入文本**:输入文本需要先通过分词器(如** **`BertTokenizer`)进行编码,转换为模型可以理解的格式。具体来说,输入文本会被分割成一个个token(词汇或字符),并映射到模型的词汇表中对应的ID。 * 输入张量 * **input\_ids**:这是一个二维张量,形状为** **`[batch_size, sequence_length]`,其中** **`batch_size` 是批次大小,\`sequence\_length\` 是序列长度。每个元素是词汇表中的token ID。 **attention\_mask**(可选):用于指示哪些位置是有效的token(值为1),哪些位置是填充的(值为0)。形状为** **`[batch_size, sequence_length]`。 **position\_ids**(可选):用于指示每个token在序列中的位置。形状为** **`[batch_size, sequence_length]`。 **token\_type\_ids**(可选):用于区分不同类型的token(例如,在句子对任务中区分两个句子)。形状为** **`[batch_size, sequence_length]`。 #### 模型输出数据信息 * 输出张量 * **logits**:这是模型生成的每个位置上所有可能token的概率分布。形状为** **`[batch_size, sequence_length, vocab_size]`,其中** **`vocab_size` 是词汇表的大小(21128)。每个位置上的概率分布可以通过softmax函数转换为概率值。 * **past\_key\_values**(可选):用于加速推理过程中的自回归生成。包含之前计算的注意力键和值,可以在生成下一个token时复用。 #### 模型结构 * **Embedding层** * **wte (word embeddings)**:将输入的token ID嵌入到768维的向量空间中。形状为** **`[vocab_size, hidden_size]`,其中** **`hidden_size=768`。 * **wpe (position embeddings)**:将每个token的位置信息嵌入到768维的向量空间中。形状为`[max_position_embeddings, hidden_size]`,其中** `max_position_embeddings=1024`。 * **Dropout层:**在嵌入层之后应用一个dropout层,以防止过拟合。dropout概率为0.1。 * **Transformer层:**包含12个`GPT2Block`,每个块由以下部分组成: * **LayerNorm (ln\_1)**:在多头自注意力机制之前应用层归一化。 * **Attention (attn)**:多头自注意力机制,用于捕捉输入序列中的依赖关系。包括三个子模块: * **c\_attn**:线性变换,将输入映射到查询、键和值的组合空间。 * **c\_proj**:线性变换,将注意力结果映射回隐藏状态空间。 * **attn\_dropout** 和**resid\_dropout**:分别应用于注意力权重和残差连接的dropout层。 * **LayerNorm (ln\_2)**:在前馈神经网络之前应用层归一化。 * **MLP (mlp)**:两层全连接网络,激活函数为`NewGELUActivation`,并在最后一层应用dropout。 * **Final LayerNorm:**在所有Transformer层之后应用最终的层归一化。 * **Language Model Head (lm\_head):**线性变换,将隐藏状态映射回词汇表大小的空间。形状为`[hidden_size, vocab_size]`,没有偏置项。 #### 工作流程 1.**输入处理**:输入文本通过分词器编码为`input_ids`,并可能附加`attention_mask` 和`position_ids`。 2.**嵌入层**:将`input_ids` 和`position_ids` 转换为嵌入向量,并应用dropout。 3.**Transformer层**:嵌入向量依次通过12个`GPT2Block`,每个块内部进行多头自注意力计算和前馈神经网络变换。 4.**输出层**:最终的隐藏状态通过`lm_head` 线性变换,得到每个位置上所有可能token的概率分布。 5.**生成文本**:使用生成策略(如贪心搜索、束搜索或采样)从概率分布中选择最合适的token,逐步生成新的文本。 最后修改:2026 年 03 月 21 日 © 允许规范转载 赞 如果觉得我的文章对你有用,请随意赞赏