离线、近线和在线计算
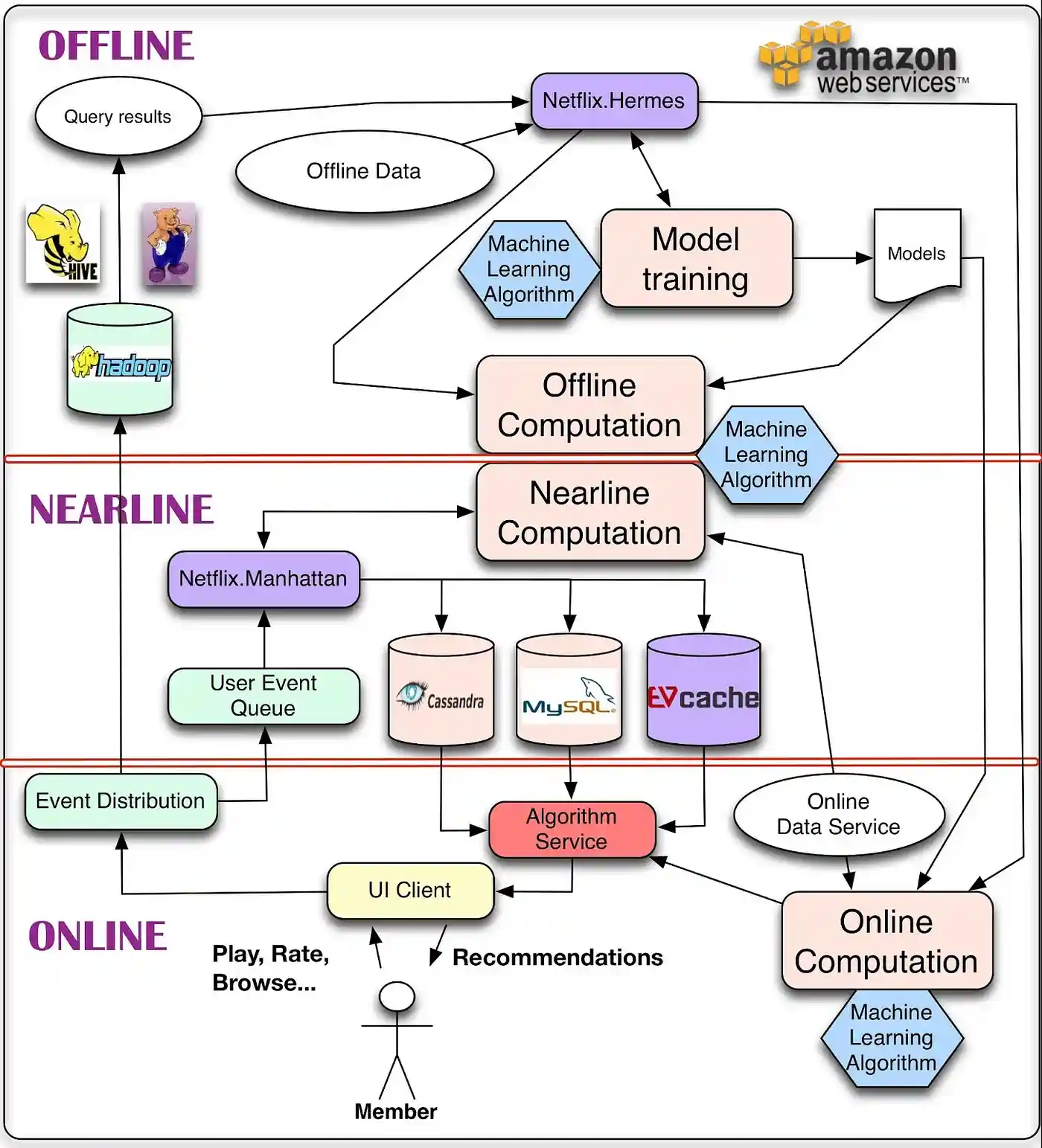
在线计算可以更好地响应最近的事件和用户交互,但必须实时响应请求。这会限制所采用算法的计算复杂性以及可处理的数据量。这个实时响应的过程中,如果发生意外,比如说这个物品 ID 就没有相关的物品,那么这时候服务就需要降级,所谓的降级就是不能达到最好的效果了,但是不能低于最低要求,这里的最低要求就是必须要返回东西,不能开天窗。
于是,这就降级为取出热门排行榜返回。虽然不是个性化的相关结果,但是总比开天窗要好。这就是服务的可用性。
在线阶段还要实时地分发用户事件数据,就是当用户不断使用产品过程产生的行为数据,需要实时地上报给有关模块。这一部分也是需要实时的,比如用于防重复推荐的过滤。
离线计算对数据量和算法计算复杂性的限制较少,因为它以批处理方式运行,时间要求宽松。但是,由于未纳入最新数据,因此它在更新之间很容易变得陈旧。大多数推荐算法,实际上都是在离线阶段产生推荐结果的。离线阶段的推荐计算和模型训练,如果要用分布式框架,通常可以选择 Spark 等。
近线计算是这两种模式之间的折衷方案,在这种模式下,我们可以执行类似在线的计算,但不需要实时提供这些计算。从前面的架构图中也可以看出,这一层的数据来源是实时的行为事件队列,但是计算的结果并不是沿着输入数据的方向原路返回,而是进入了在线数据库中,得到用户真正发起请求时,再提供服务。
一个典型的近线计算任务是这样的:从事件队列中获取最新的一个或少许几个用户反馈行为,首先将这些用户已经反馈过的物品从离线推荐结果中剔除,进一步,用这几个反馈行为作为样本,以小批量梯度下降的优化方法去更新融合模型的参数。
这两个计算任务都不会也不需要立即对用户做出响应,也不必须在下一次用户请求时就产生效果,就是说当用户实时请求时,不需要去等待近线任务的最新结果,因为两者是异步的。
近线计算任务一个核心的组件就是流计算,因为它要处理的实时数据流。常用的流计算框架有 Storm,Spark Streaming,FLink 等
事件和数据分发系统需要如何处理不同类型的事件和数据
离线作业
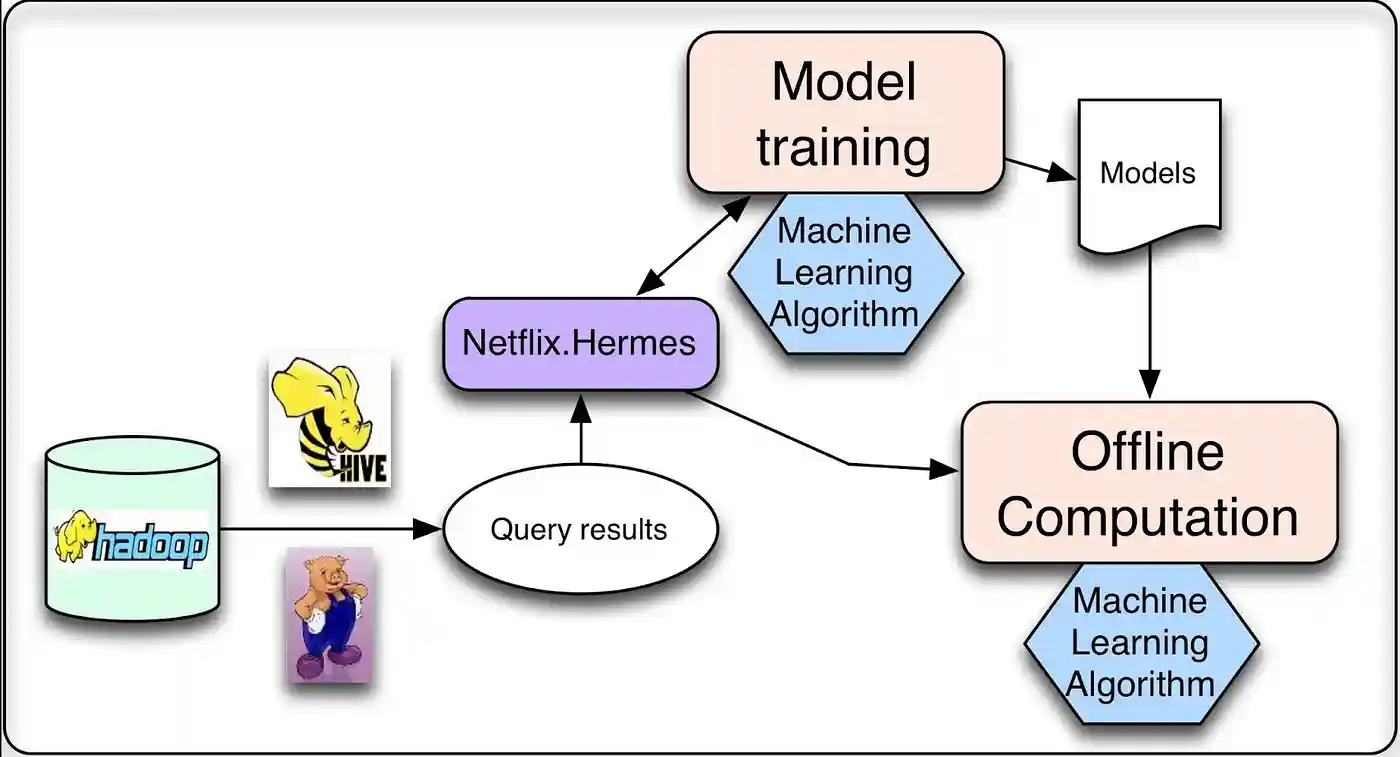
运行个性化机器学习算法时,进行的大部分计算都可以离线完成。有两种主要类型的任务属于此类别:模型训练和中间或最终结果的批量计算。
在模型训练中,收集相关的现有数据并应用机器学习算法生成一组模型。大多数模型是以批处理模式离线训练,也有一些在线学习技术增量训练。
这两项任务都需要处理精炼数据,这些数据通常是通过运行数据库查询生成的。由于这些查询涉及大量数据,因此以分布式方式运行它们会大有裨益,这使得它们非常适合通过 Hive 在 Hadoop 上运行。查询完成后,需要一种发布结果数据的机制。
信号与模型
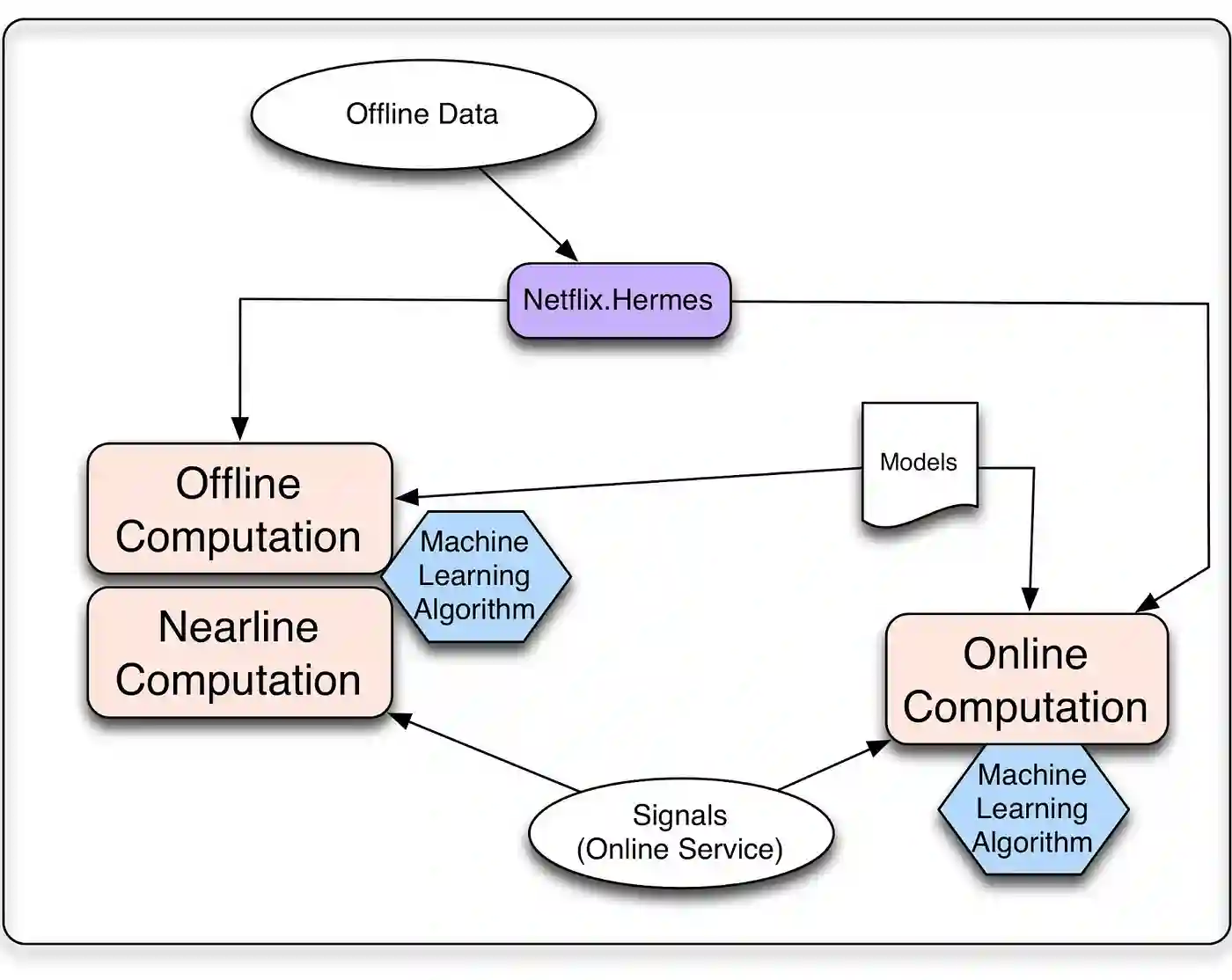
无论在进行在线还是离线计算,都需要考虑算法如何处理三种输入:模型、数据和信号。模型通常是之前经过离线训练的参数的小文件。数据是之前处理过的信息,存储在某种数据库。这些数据来自实时服务,可以由用户相关信息组成,例如会员最近观看的内容,也可以由上下文数据(例如会话、设备、日期或时间)组成。
事件与数据分布
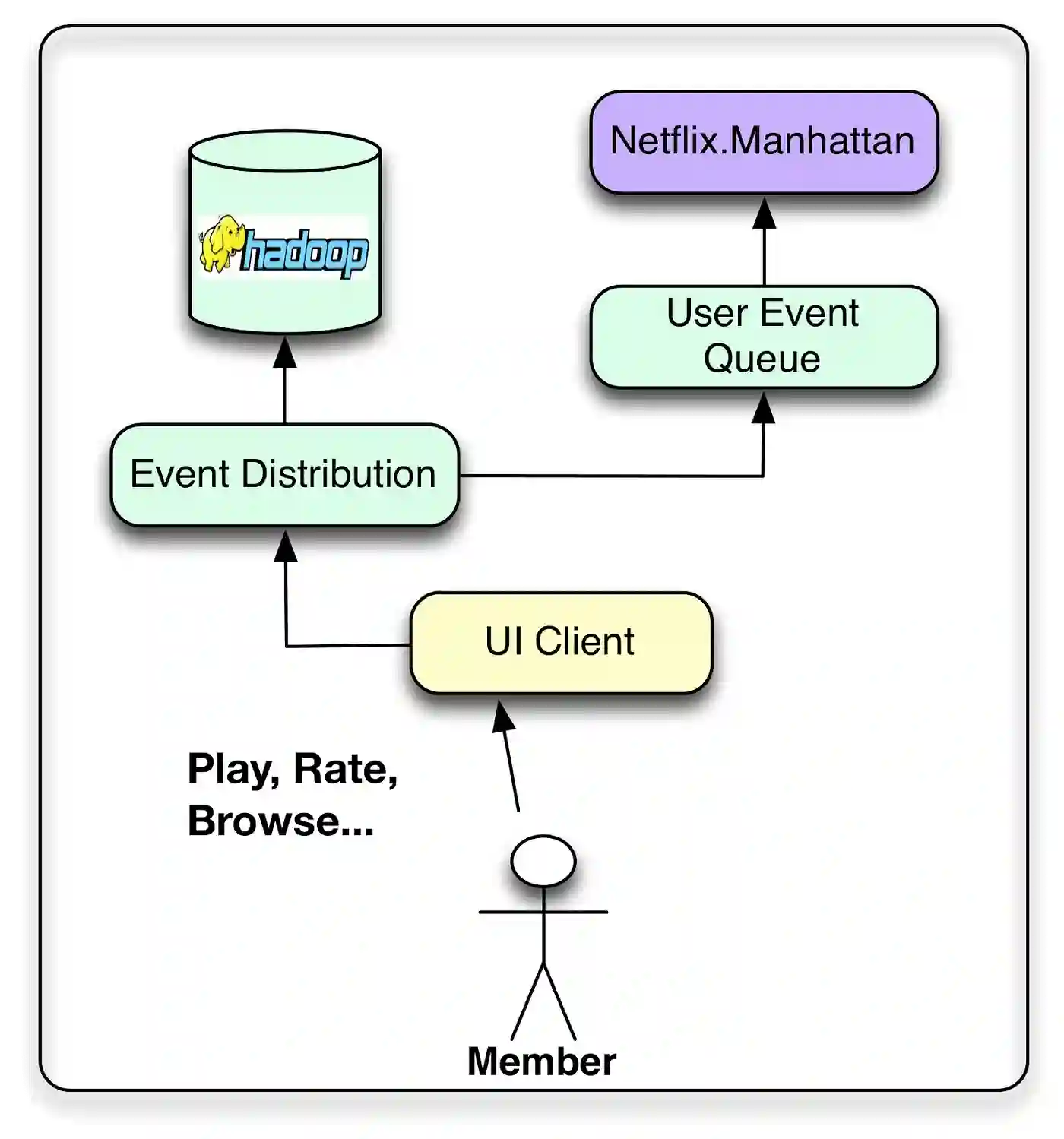
区分数据和事件,尽管边界肯定很模糊。
将事件视为需要以尽可能少的延迟进行处理的时间敏感信息的小单元。这些事件被路由以触发后续操作或过程,例如更新近线结果集。
将数据视为更密集的信息单元,可能需要处理和存储以供以后使用。
在这里,延迟并不像信息质量和数量那么重要。当然,有些用户事件可以同时被视为事件和数据,因此可以发送到两个流。
推荐结果
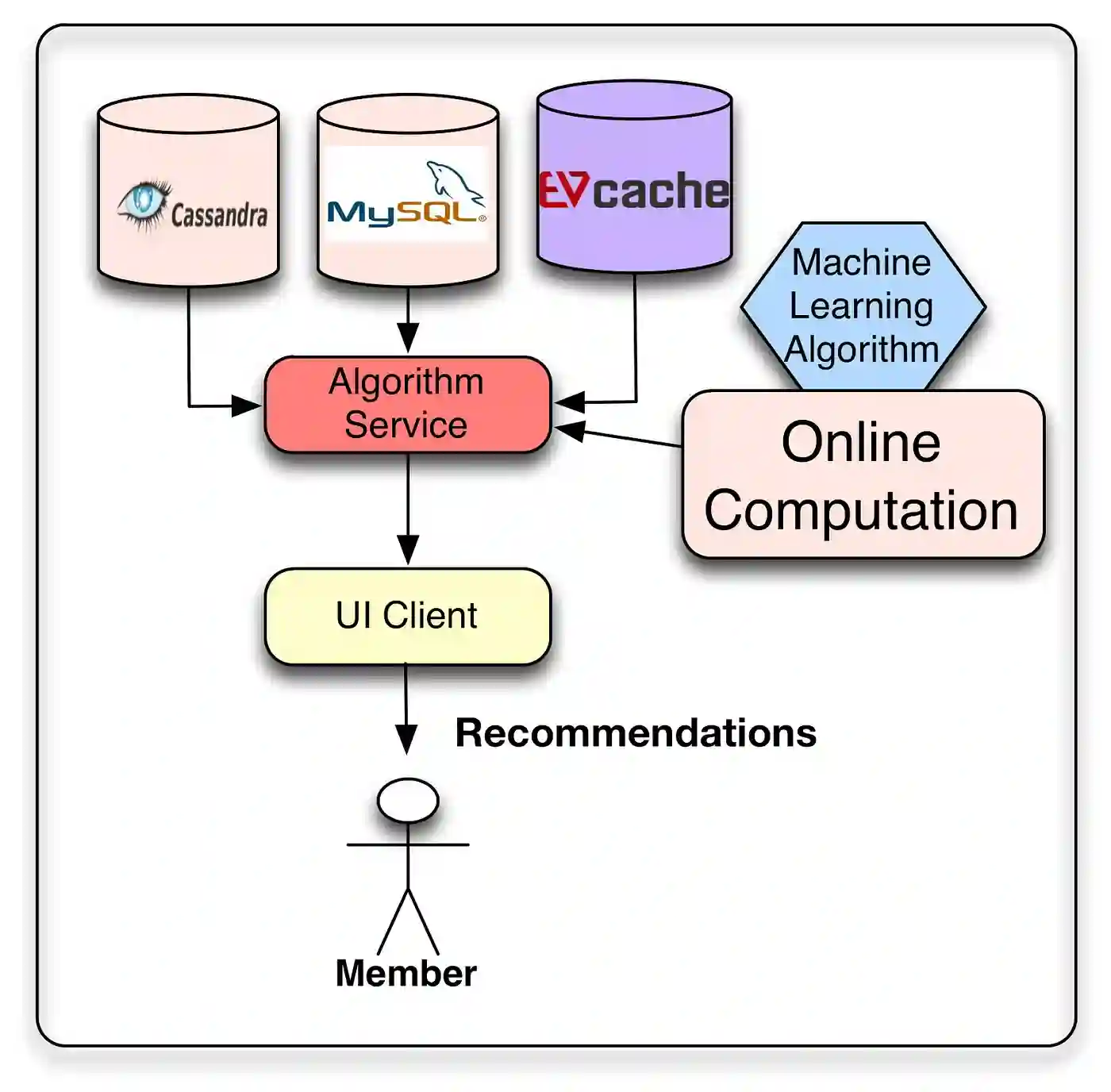
机器学习方法的目标是提供个性化推荐。这些推荐结果可以直接从之前计算的列表中提供,也可以通过在线算法即时生成。可以考虑使用两者的组合,其中大部分推荐都是离线计算的,通过使用实时信号的在线算法对列表进行后处理来增加一些新鲜度。