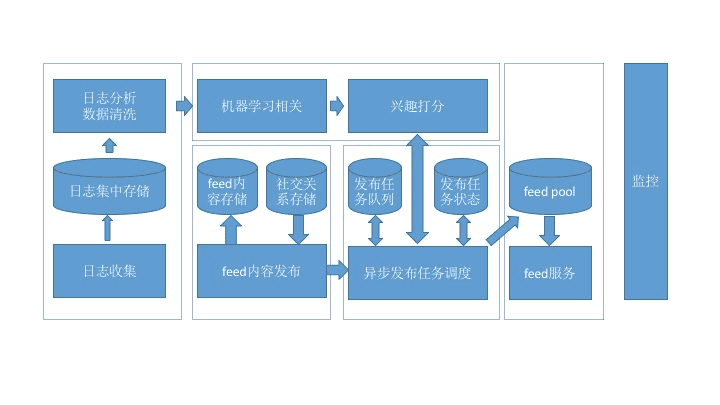
存储
离线阶段会产生数据按照用途来分,归纳起来一共就有三类:
特征: 特征数据会是最多的,所谓用户画像,物品画像,这些都是特征数据,更新并不频繁。
模型: 尤其是机器学习模型,这类数据的特点是它们大都是键值对,更新比较频繁。
结果: 就是一些推荐方法在离线阶段批量计算出推荐结果后,供最后融合时召回使用。任何一个数据都可以直接做推荐结果,如协同过滤结果。
推荐系统依赖的特征是由各种特征工程得到,这些线下的特征工程和样本数据共同得到模型数据,这些模型在线上使用时,需要让线上的特征和线下的特征一致,因此需要把线下挖掘的特征放到线上去。特征数据有两种,一种是稀疏的,一种是稠密的,稀疏的特征常见就是文本类特征,用户标签之类的,稠密的特征则是各种隐因子模型的产出参数。
数据存在的形态:
正排:以用户 ID 或者物品 ID 作为主键查询(线下从日志中得到曝光和点击样本后,还需要把对应的用户 ID 和物品 ID 展开成各自的特征向量,再送入学习算法中得到最终模型),需要用列式数据库存储
倒排:以特征作为主键查询(已知用户的个人标签,要用个人标签召回推荐信息,需要提前准备好标签对推荐信息的倒排索引),索引需要用 KV 数据库存储
稠密特征向量:例如各种隐因子向量,Embedding 向量,考虑文件存储,采用内存映射的方式,会更加高效地读取和使用
模型数据:相似度矩阵,物品相似度,用户相似度,在离线阶段通过用户行为协同矩阵计算得到,用来对用户或者物品历史评分加权的,这些历史评分就是特征。
候选集:预先计算出来的推荐结果,数据通常是 ID 类,召回方式是用户 ID 和策略算法名称。这种列表类的数据一般也是采用高效的 KV 数据库存储,如Redis。
推荐系统的简单第一版:ElasticSearch分布式搜索引擎,用于日志存储和分析,承担了存储和计算的任务。
列式存储
把数据都想象成为矩阵,行是一条一条的记录,例如一个物品是一行,列是记录的各个字段,例如 ID 是一列,名称是一列等。数据在计算机中,不管行式还是列式,都要以一个一维序列的方式存在内存里或者磁盘上。所以是按照列的方式把数据变成一维,还是按照行的方式把数据变成一维,就是列式数据库和行式数据库的区别。列式数据库有个列族的概念,可以对应于关系型数据库中的表,还有一个键空间的概念,对应于关系型数据库中的数据库。列式数据库适合批量写入和批量查询。
键值存储
Redis 可以简单理解成是一个网络版的 HashMap,但是它存储的值类型比较丰富,有字符串、列表、有序列表、集合、二进制位。
并且,Redis 的数据放在了内存中,所以都是闪电般的速度来读取。
在推荐系统的常常见到 Redis 的使用:
1. 消息队列,List 类型的存储可以满足这一需求;
2. 优先队列,比如兴趣排序后的信息流,或者相关物品,对此 sorted set 类型的存储可以满足这一需求;
3. 模型参数,这是典型的键值对来满足。