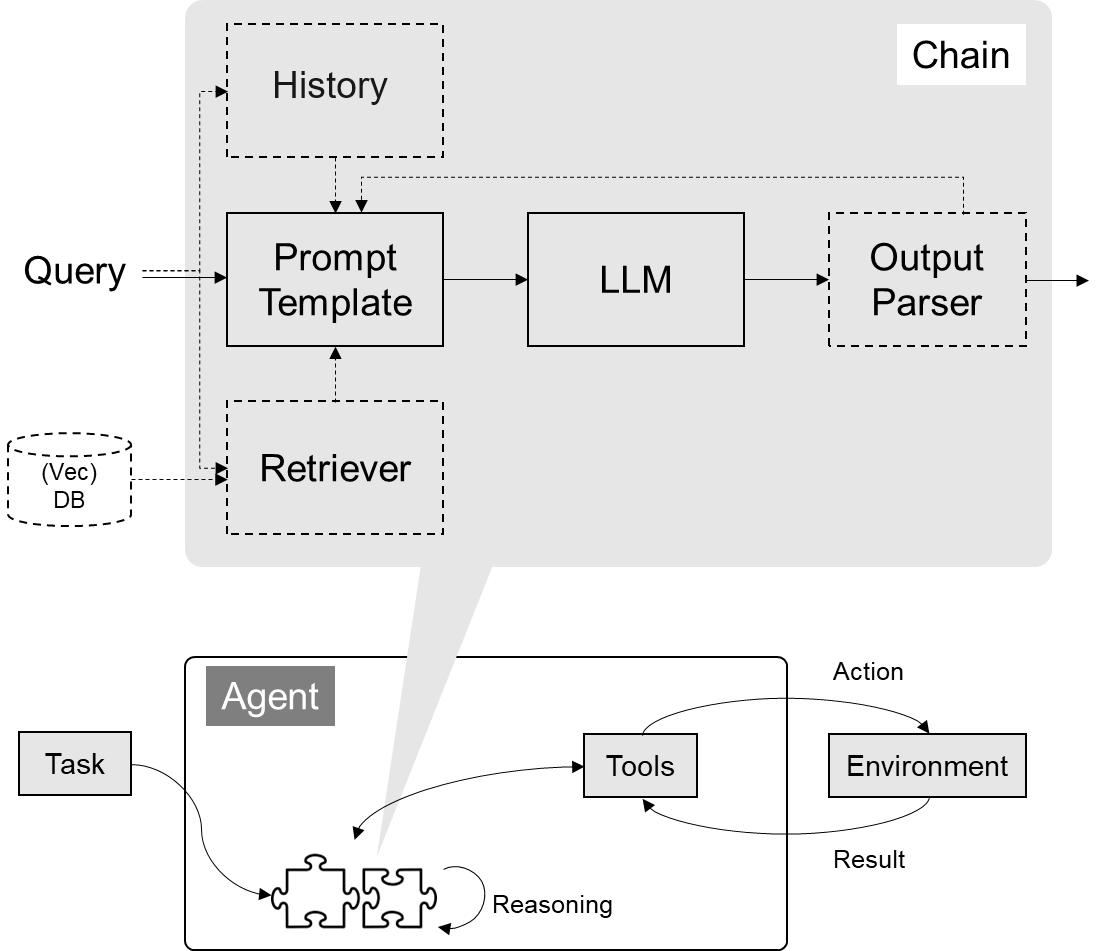
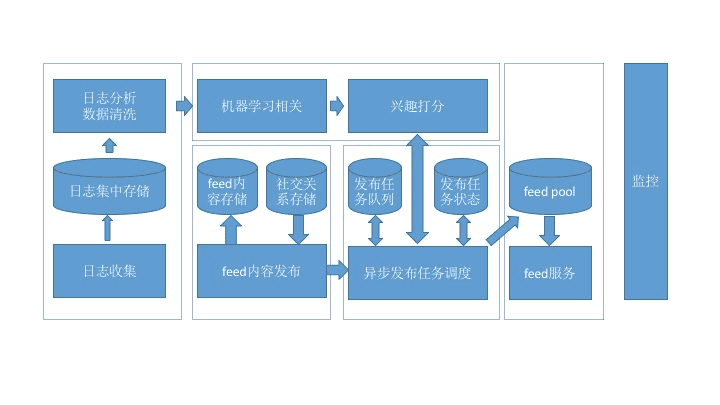
一、推荐系统的功能及作用
从事电商项目近4年的时间,参与了电商项目的整个生命周期,到目前为止,已经参照互联网最新潮流技术,构建出一个功能比较全面包含会员、订单、物流、营销、账单、分销、活动、抽奖、多供应商、多仓库等功能非常强的电商系统。但是,相比于物联网主流电商平台还是缺少一个很大的功能模块---推荐系统。
众所周知,淘宝、京东等主流电商平台都有自己的推荐系统,还有很多垮平台的推荐系统。例如在浏览一些汽车查询平台后,在浏览微信朋友圈时会发现经常会推荐一些汽车广告。
信息过载:通过互联网我们获取信息的途径得到了极大的拓展。但是,随着互联网的迅速发展,网上的信息量呈现爆炸式的增长。过多的信息反而是的在获取真正有用的那部分信息时变得十分困难,信息的利用率反而降低。
在解决“信息过载”问题方面是一个非常有潜力的方法----推荐系统。他是根据用户的额信息需求、兴趣爱好等,将用户感兴趣的信息、产品等推荐给用户的个性化信息系统。另外,站在电商网站角度,只是从销量方面进行推荐,这样的推荐方式肯定起不到吸引客户消费的目的。除此之外还要考虑用户的喜好以及产品的特点,用户经常浏览以及购买的什么商品?购买产品最多的是年轻人还是老人?等等
二、推荐系统的核心问题
1、到底什么是推荐系统-求解的数学问题
关于推荐系统,百度百科的解释是:推荐系统是利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程。个性化推荐是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。
电商系统在向用户推荐商品时,通常是基于用户的浏览记录、评价记录等,将这些记录抽象为(userId,productId,score)这样的向量结构,这里的score可以是任意一个数字,也可以是0/1,表示用户与商品之间建立了关系,比如是否购买过商品、是否浏览过商品。这些数据是比较零散的,在数据梳理之后,会形成以userId为列,productId为行形成一个矩阵。
一个向量数据就代表矩阵中的一个点。矩阵中数据比较稀疏的通常称为稀疏矩阵。推荐算法要做的就是将这些矩阵这种中的空白点,以某种方式填充。填充的每一个点就代表向用户推荐这个产品的一个推荐指数。以后实现推荐功能时,只需要从这些填充的指数中寻找排名比较靠前的就可以了。所以,推荐系统各有千秋,纷繁复杂的应用形式和场景,但是其本质就是二维矩阵的补全问题。
2、推荐系统的衡量标准
基于常识:推荐系统是一个数字游戏,但是业务不是简单的数字游戏。有些推荐结果是可以从业务上直接判断好坏。
基于指标:通过一定的业务指标衡量,例如PV、UV、用户留存率、转化等等,通过对比推荐系统使用或事更新前后的指标数据来衡量一个推荐系统是不是有效。
基于机器学习:基于机器学习算法的判断指标和优化方法。
三、推荐系统中的机器学习
机器学习的门槛是比较高的,需要有大量的高等数学以及统计学的基础知识
1、什么事机器学习
机器学习是属于人工智能的一个研究范畴。目前,主要的应用领域可以分为3个主要方向:
传统预测:数据挖掘、预测
图形识别:自动驾驶、人脸识别
自然语言处理:ChatGPT
关于机器学习推荐一本寄给经典的入门资料
2、机器学习数据形式
机器学习有三个关键词:数据、模型、预测。机器学习强调从历史数据中自动学习,对数据之间的规律进行归纳,形成模型,然后用模型来对实际问题进行预测。这个过程跟人类理解一个事物的过程很类似。
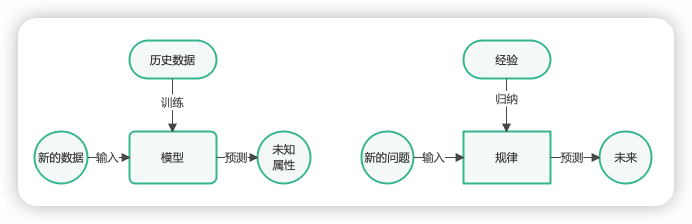
机器学习的数据构成:特征值+目标值,在数据集中特征值是必不可少的,目标值有可能需要通过对数据进行处理来获得,但是有些数据集是可以没有目标值。
比如这样一个房价的数据,每一行称为一个样本。多个样本构成一个数据集。在这个数据集中
特征值:房子的各个属性
目标值:样本结果
机器学习的过程就是从已有房价数据中学习到房价之间的规律,以后如果再来一个房子,就可以根据房子的这些属性,预测房子的价格。
3、机器学习的算法分类
机器学习涉及到非常多的数学算法。对这些数学算法,通常会根据目标值的类型进行简单分类。
分类算法: 这一类问题的目标值是有限的几个离散值。例如我们对动物进行分类。常用的算法有:k近邻算法、贝叶斯算法、决策树与随机森林、逻辑回归等。
回归算法: 这一类问题的目标值是一组连续值。例如对房价的预测。常用的算法有:线性回归、岭回归等。
无监督学习:这一类问题没有目标值。也就是说,没有一个固定的目标去监督机器学习的过程。例如我们常说的人以类聚,物以群分。我们通常会需要将所有客户区分成一个个具有相似特征的客户群,但是我们也不知道要把客户分成哪些群比较合适。这个时候,就可以用无监督学习,让机器学习去找出最具有区分度的划分方式。常用的算法有 k-Means分类算法。
与无监督学习对应的,分类算法和回归算法都是有目标值,也就是有具体目标的机器学习算法,他们就统称为监普学习。
4、机器学习的处理流程
数据收集:收集尽量多,尽量全的业务数据,整个机器学习的结果才会更准确。机器通过学习历史数据,总结出一些最有可能的规律,当这些规律达到比较高的可信度时,就可以用来对未来数据进行预测。所以数据的体量和质量,往往就决定了机器学习所能达到的高度。
数据清洗:通过数据清洗将明显无用的数据去掉,并且把数据整理成能够被机器学习接受的数据格式。
训练模型:选择合适的机器学习算法,通过学习数据形成一个数据模型。同一个模型不同的算法,同一个算法不同的参数都会计算出不同的数据模型。
模型优化:1.测试集和训练集,用机器学习算法在训练集上学习,然后用测试集对模型进行测试。2.新的业务数据需要让模型继续学习。
五、特征工程
数据和特征决定了机器学习的上限,模型和算法只是不断逼近这个上限而已。
特征工程是使用专业背景知识和技巧,处理数据,是的特征能够在机器学习算法上发挥更好的作用的过程。特征工程会直接影响机器学习的效率。其本质就是在数据收集清洗之后,在机器学习之前,对数据进行预处理的过程。
1、特征抽取
机器学习只能学习数字类型的特征值,诸如图片、文本、字符类型的原始数据就需要使用特征抽取将数据转化成适合机器学习的特征数字。
2、特征预处理
有这样一组特征值: 用户年龄和用户收入。年龄的数字相比收入的数字会小很多。根据之前特征要平等的原则,这一组数据集中,用户收入的特征会被放大,而用户年龄的特征就容易被忽略。所以在用这样的数据集之前,要把各个特征值的范围尽量统一。这种方式称之为无量纲化,也就是要在保留数据之间的特征关系的同时,消除单位不同造成的特征之间的不平等。
3、降维
在某些限定条件下,降低特征的个数,得到一组"不相关”的主变量的过程。例如,学习某一个地区的降雨量,就会去统计一些常用的天气特征。而这其中,相对湿度与降雨量就是一个相关的特征,相对湿度大,肯定降雨量就会偏大。在进行机器学习训练算法时,如果特征本身存在问题或者特征之间相关性较强,那对于算法学习预测的影响就会比较大。而我们降维的过程,不光是要降低特征值的个数,同时也要尽量保留不相关的特征。