基于RAM
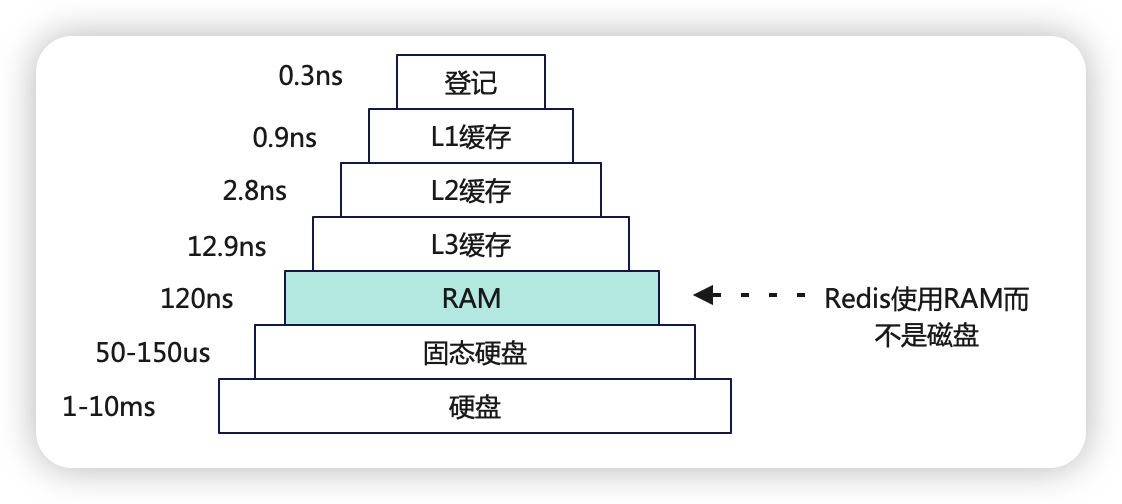
IO多路复用&单线程读写

高效的数据结构


环境配置 internlm2 模型部署 创建虚拟环境 conda create -n deepseek_rag python=3.10 -y conda activate deepseek_rag 并在环境中安装运行 demo 所需要的依赖 # 升级pip python -m pip install
在自然语言处理(NLP)任务中,处理超长文本(通常指长度超过模型最大支持长度的文本)是一个常见的挑战。BERT等预训练模型通常具有固定的最大序列长度限制(例如,BERT-base的最大序列长度为512个标记)。当需要处理超过这个长度的文本时,需要采取特定的策略来确保模型能够有效地处理这些数据。 Be
数据集的类别均衡性对模型的性能有着至关重要的影响。当数据集中某些类别的样本数量远多于其他类别时,就会出现数据不均衡问题。这种不平衡可能导致模型在训练过程中偏向多数类,从而影响对少数类的预测性能。 问题描述 分类数据集统计 import pandas as pd # 读取CSV文件 csv_file
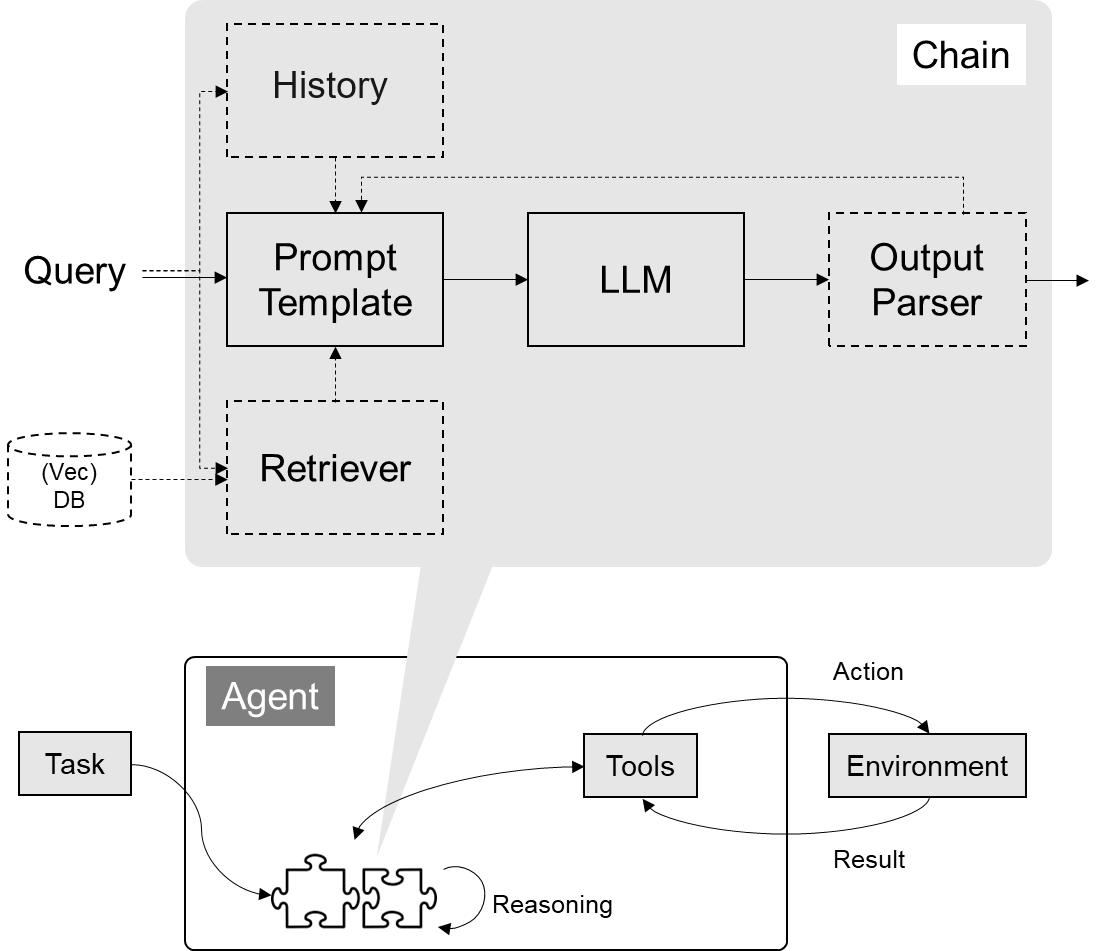
本文内容 LangChain(大模型能力封装框架) 的基本使用 基于LangChain探索AGI时代原型 需提前安装环境依赖,以及设置环境变量,如果选择openai开放接口需要会上网 export OPENAI_API_KEY="b233095ff.00gIXhXyE8yNc3Hx" export
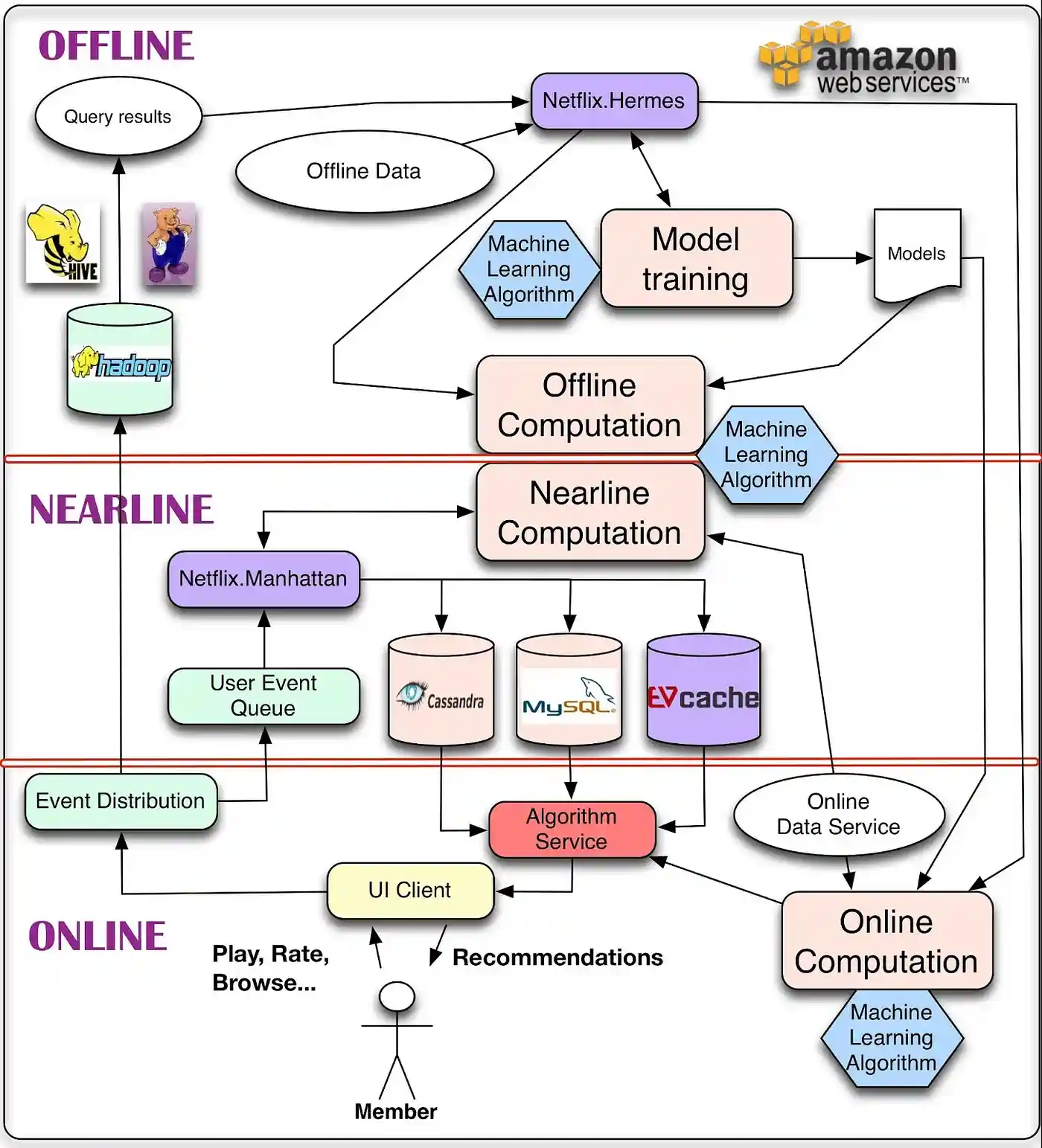
离线、近线和在线计算 在线计算可以更好地响应最近的事件和用户交互,但必须实时响应请求。这会限制所采用算法的计算复杂性以及可处理的数据量。这个实时响应的过程中,如果发生意外,比如说这个物品 ID 就没有相关的物品,那么这时候服务就需要降级,所谓的降级就是不能达到最好的效果了,但是不能低于最低要求,这里
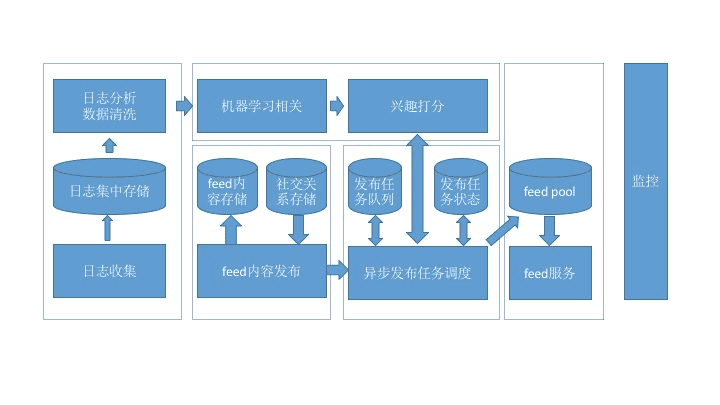
整体框架 信息流,通常也叫作 feed,传统的信息流产品知识简单按照时间排序,而被推荐系统接管后的信息流逐渐成为主流,按照兴趣排序,也叫作“兴趣 feed”。 这张架构图划分成几个大的模块:日志收集、内容发布、机器学习、信息流服务、监控 日志收集,是所有排序训练的数据来源,要收集的最核心数据就是用户